1月7日,第50期AIR学术沙龙如期举行,本期活动荣幸邀请到了清华大学交叉信息研究院长聘教授李建,为清华师生带来一场题为《Understanding LLM Behaviors via Compression: Data Generation, Knowledge Acquisition and Scaling Laws》的深度分享。

李建,清华大学交叉信息研究院长聘教授,博士生导师。研究方向为理论计算机科学、人工智能基础理论、金融科技。在主流国际会议和杂志上发表了100余篇论文,并获得了数据库顶级会议VLDB和欧洲算法年会ESA的最佳论文奖、数据库理论会议ICDT最佳新人奖、多篇论文入选口头报告或亮点论文。曾主持或参与了多项自然科学基金项目及企业合作项目。
李建教授首先回顾了大语言模型理论研究现状与问题。尽管大语言模型在实际应用中表现强大,但底层逻辑和机理尚不清晰,相关理论严重滞后。尽管过去 6 - 7 年深度学习理论有了很大发展,但是深度学习中仍然有很多基础问题未能完全解决。最近,大语言模型的出现带来了更多当前学习理论无法解释的问题,如尺度缩放定律(scaling law),思维链,推理能力等。
李建教授特别强调,尺度缩放定律所呈现特定的指数形式显著偏离了传统统计机器学习理论通常展示的收敛率。此外,目前针对大语言模型现象的理论工作存在局限性,理论模型多为简化模型,相互兼容性差,且一般只能解释一个现象,难以解释多个现象。当前大语言模型的研究主要集中在结构、优化器和后训练等方面,对数据的研究相对缺乏。多数研究假设简单的数据分布,如高斯分布,从数据建模获得有价值理论的工作较少。
在上述背景下,李教授提出一种以数据为中心的研究方法,将数据分布和大模型代表性现象联系起来,同时解释了尺度定律与in-context-learning等,并且通过信息论工具绕过了复杂的架构和优化器。具体为构建了一个生成模型来模拟自然语言分布,并从理论和实验两方面共同验证尺度缩放定律等现象。
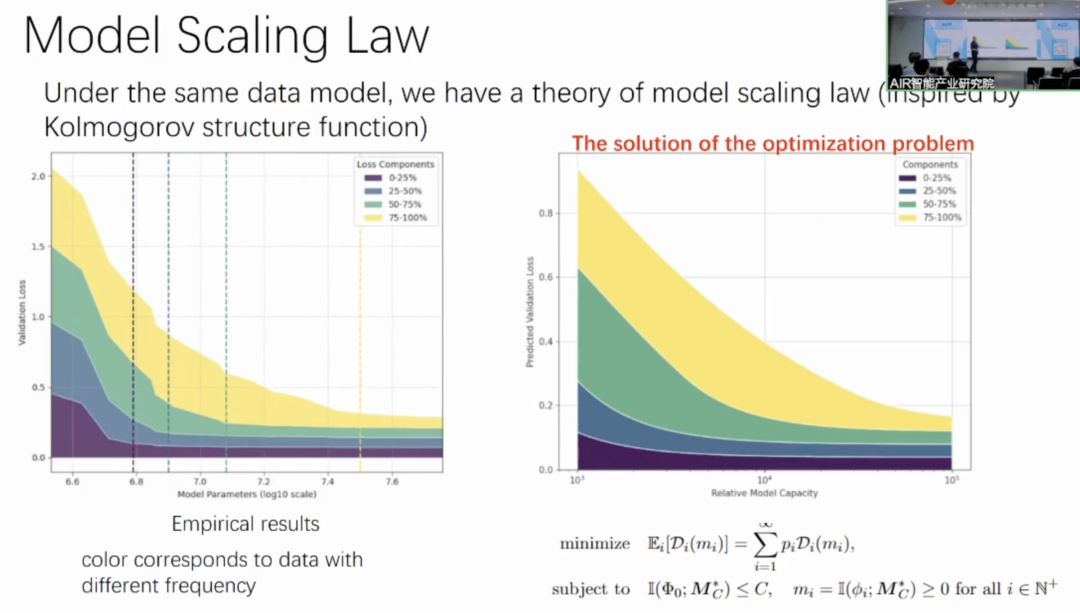
研究的理论框架来自于香农编码定理与柯尔莫戈罗夫结构函数。压缩与预测的等价性:建立了大语言模型预测损失(交叉熵损失)与压缩的等价关系,即更好地预测下一个令牌(next token)能更好地压缩序列。若能达到交叉熵损失 c,每个令牌(TOKEN)就能压缩到 c 个比特,并且最优的预测对应着最短的压缩长度。这个理论工具可以计算最优的压缩(即预测)性能。
研究构建了一个生成模型来模拟自然语言。首先将语言分为知识和语法两部分。知识部分可形成不同的簇,如数学、政治、足球等,且知识是抽象的,通过不同的语法编码形成句子。语法部分具有共性,相对简短,能用小的固定参数模型学会,如用小的循环神经网络(RNN)可学会英文语法。
知识部分的刻画:用中国饭店过程(Chinese restaurant process)刻画知识部分。该过程中,顾客对应句子,桌子对应主题。顾客选择桌子的概率与已坐在桌子上的人数和参数α有关,还有一定概率坐在新桌子上开启新主题。该过程与实践中观察到的希普斯定律(Hip's law)和齐普夫定律(Zipf's law)相吻合。
对于上述数据生成的理论分析表明,最优预测的损失服从缩放定律。特别地,语法部分和知识服从不同的幂律,知识幂律存在因子α,说明大模型先学习语法,后学习知识。
为验证理论,进行了可控实验,使用生物数据集(Bio dataset),该数据集是合成数据,可调控数据分布。实验结果表明,不同的α值对应不同的数据分布和缩放定律曲线,且数据的幂律分布决定了缩放定律中的幂律,与理论结果一致。模型会先学习语法,然后是出现频率较高的知识,最后是低频知识。
不同尺度的模型同样展现出先学高频后学低频的规律:
李教授提到,类似分析可以扩展到in-context-learning与模型幻觉。
最后,李建教授总结了理论在实践中的应用与启发
1.预训练数据处理:预训练数据需要进行处理,数据混合比例很重要。如在 LLAMA 3 中,会对出现过于频繁的无营养数据进行下采样,对出现较少的数据进行上采样。合适的调配比例能调整数据分布,决定哪些知识能被学好。
2.数据生成的启发:数据生成方面,可考虑用更精简的语法编码知识,如大家通常觉得中文比英文更精简,因此,可以考虑设计新的语法编码,更精简的表示知识,达到更搞的训练效率。另外,不同的分词方法(tokenization method)也可以被理解成不同的语法编码,那么通过修改分词方法可以改变训练效率,改变缩放定律。
3.合成数据分布设计:均匀分布的数据在学习过程中会出现奇怪现象,开始学不会,直到模型大小达到一定程度才集体学会。而幂律分布的数据具有光滑的学习曲线,这表明在设计合成数据时,幂律分布可能更有利于学习。






