1月15日上午,第51期由AIR DISCOVER实验室主办的AIR青年科学家论坛如期举行。本次活动我们有幸邀请到美国宾夕法尼亚大学的顾佳涛教授,分享其在Towards Robust Video World Models方向的最新研究进展。

顾佳涛,现任宾夕法尼亚大学计算机与信息科学系助理教授,也是GRASP实验室核心成员及ASSET中心成员,并兼任苹果公司(Apple MLR)主任研究科学家。他本科毕业于清华大学,于香港大学获得博士学位,此前曾在Meta AI(FAIR)担任研究科学家。其研究长期聚焦于生成式机器学习领域,致力于通过世界建模、迭代推理与决策机制,构建高效、灵活且可扩展的智能系统。
本次论坛顾佳涛主要探讨了如何利用新型生成式模型构建具备鲁棒性的视频世界模型,并以此作为通向物理智能的关键路径。顾佳涛从背景动机出发,详细介绍了其团队在自回归流模型(Autoregressive Flows)方面的创新工作,以及该技术在视频生成与物理仿真中的应用。
顾佳涛首先指出,构建通用物理智能(既能行动又能对话的机器人)面临着巨大的数据挑战。目前主流的模仿学习(Imitation Learning)依赖于“语言-图像-动作”的配对数据,但研究表明,要达到训练大语言模型同等的泛化水平,机器人可能需要收集长达10万年的交互数据,这在现实中是不可行的。
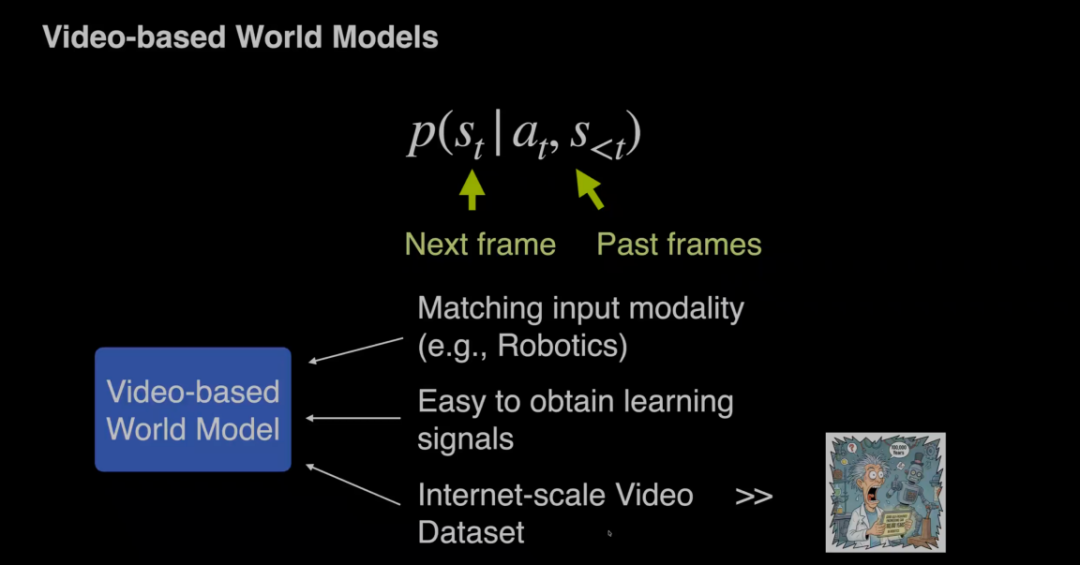
相比之下,人类具有强大的“世界模型”能力,能够通过和世界的交互来采取动作并学习技能。例如人类可以通过观看烹饪视频学会做饭,而无需从零试错。由于互联网上拥有海量的视频数据,并且和现有机器人的输入模态(视频输入)一致,顾佳涛提出将视频生成模型作为世界模型的代理,让智能体通过视频预测未来状态,从而低成本地学习物理世界的演变规律。
在技术上,顾佳涛分析了当前两大主流生成模型的局限性:
(1)扩散模型:虽然生成质量高,但是由于扩散模型通常将视频视为一个整体的三维数据块,在训练和推理时是对所有帧同时添加噪声并同时去噪,导致在生成当前帧时,模型实际上已经看到了未来的信息。这虽然能生成连贯的视频,但并不符合世界模型需要的因果性。
(2)自回归扩散生成模型:融合了自回归模型和扩散头,虽然具备因果性,但在连续空间和时间生成时面临严重的误差累积问题。由于每一次生成时的条件分布较为复杂,一旦某一步预测稍有偏差,误差就会随着时间迅速放大,导致生成崩溃。相比之下,大语言模型之所以稳定,是因为其工作在有限的离散词表空间内,每一步预测最终都会落在一个确定的词元上。这种离散化实际上起到了纠错作用,阻止了微小误差的传递。

现有的方法可以在一定程度解决这些问题,比如说可以通过一次性生成多帧来缓解误差累积;或者通过一些训练方法,比如Self-Forcing等方法,在生成过程中通过人为加入噪声来适应误差,但是这无法模拟推理时的复杂误差分布,且始终未能解决训练目标与推理过程分离的矛盾。
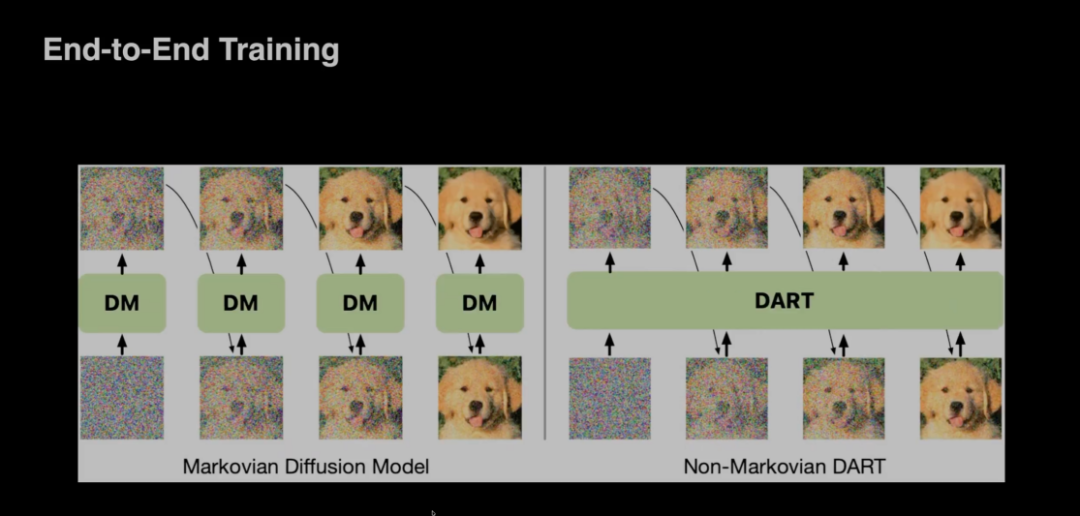
顾佳涛也介绍了团队为解决这些问题提出的DART工作。DART尝试通过非马尔可夫过程直接建模完整的生成轨迹,它允许模型以自回归的方式,在每个步骤中直接以所有历史信息和整体噪声统计量为条件进行回归。通过让模型看到生成过程的完整历史,DART能够有效缓解误差传播的问题,使生成轨迹更加稳定。但是即DART本质上和传统扩散模型一样,仍是在建模高斯分布,因此也会出现一些建模能力的问题。
针对上述痛点,顾佳涛在NeurIPS 2025上的工作提出了一种全新的生成架构STARFlow,其核心理念是将连续空间的生成过程约束在高斯空间内。该方法是基于传统Normalizing Flow架构的改进。传统的Normalizing Flow旨在寻找一条确定性的、可逆的路径,直接将数据分布映射到某种分布(通常是高斯分布),由于对模型的流函数有严格的可逆性限制,因此往往导致表达能力不如扩散模型。
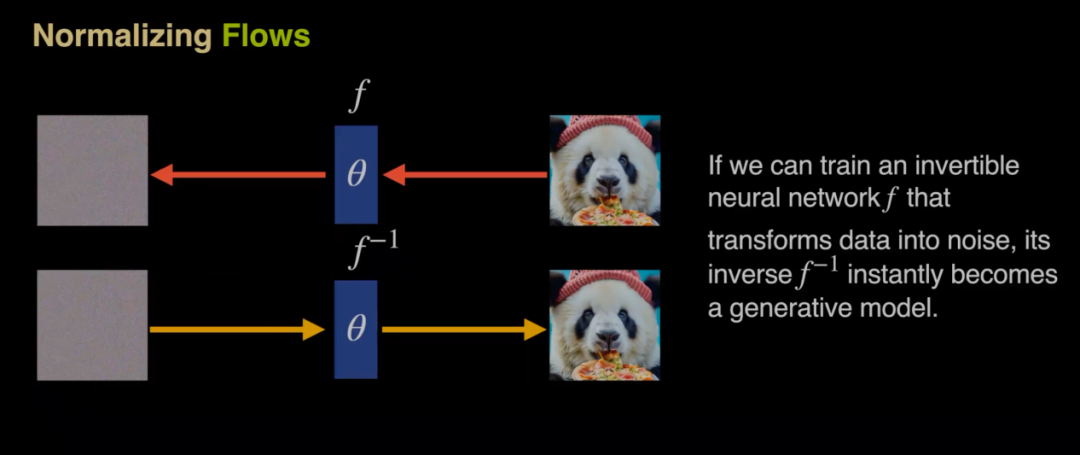
顾佳涛在对Normalizing Flow的研究中发现,如果在高斯空间中构建自回归模型,它本质上就是一种Normalizing Flow。这是因为在数学上可以将图像生成过程建模为逐像素的自回归高斯预测,数据的单向依赖性自然形成了一个三角雅可比矩阵,也就形成了可逆的流函数。这一结构上的联系,将传统流模型中的复杂求解过程,简化为仅需累加对角线上预测方差的线性操作。

顾佳涛基于当前理论提出了STARFlow。该方法利用 Normalizing Flow的组合性质,将多个简单的自回归流层串联起来,使得上一层的输出成为下一层的隐变量,提升模型的表达能力。顾佳涛从数学上证明,这种深度的堆叠结构等价于构建了一个无限高斯混合模型。这意味着STARFlow虽然由简单的高斯组件构成,却具备了拟合任意复杂数据分布的强大能力。同时,为了进一步提升上下文信息的交互效率,STARFlow在堆叠层之间采用了交替方向的设计(如第一层从左到右,第二层从右到左)。这种设计让模型能够更充分地利用全局信息进行预测。
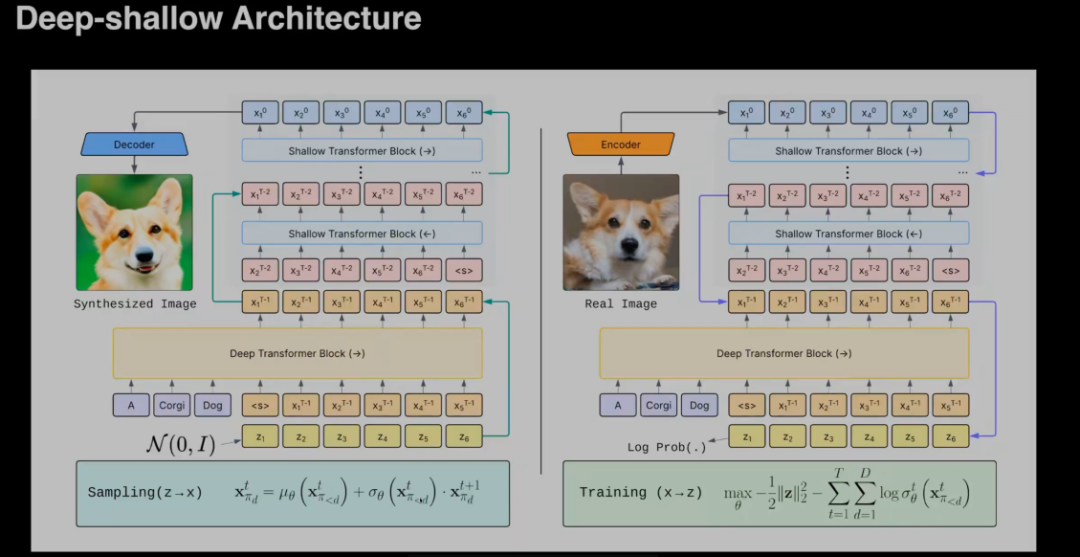
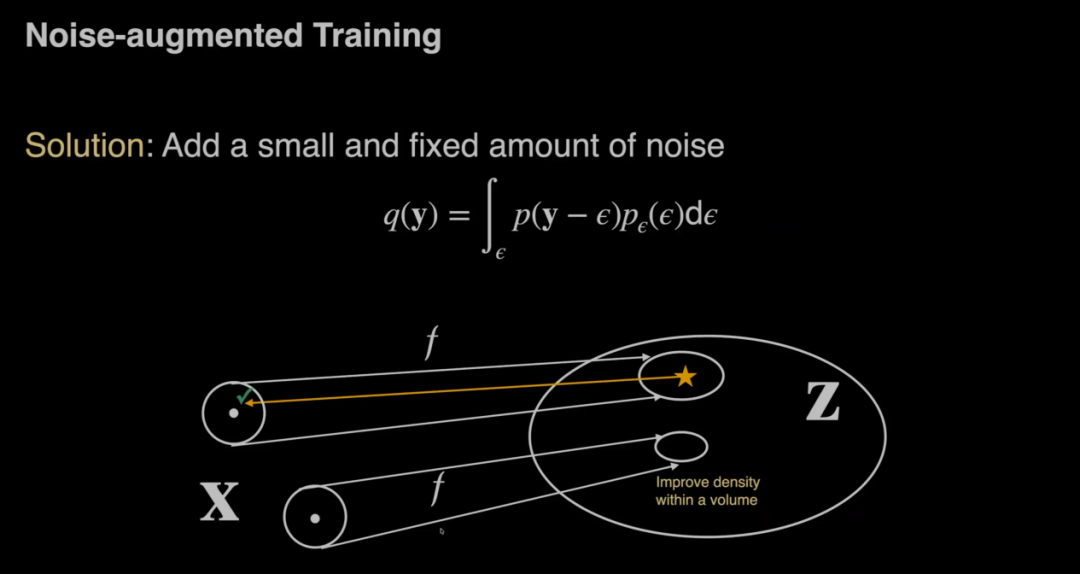
在训练时,顾佳涛指出,如果直接把用于最大似然训练搬到图像上,通常会导致Loss爆炸或生成全是噪点的“垃圾图像”。这是因为在连续空间中,概率密度是可以无限高的。如果模型发现它只要把数据空间压缩得无限小,就能获得无限大的密度值(即极高的Likelihood分数),它就会拼命去压缩空间,不再去学习图像之间平滑、通用的转换规律,而是学会了将所有概率集中在极少数的几个点上。因此,为了阻止模型作弊,STARFlow引入了一个关键技巧:在训练数据中加入微量的固定噪声。这一方法的原理是:原始图像在数据流形上可以看作是一个无限小的点。加上噪声后,这个点就变成了一团有体积的球。一旦数据有了体积,模型就无法将其无限压缩了。这使得训练过程变得平滑,使得模型学会真正的图像结构。
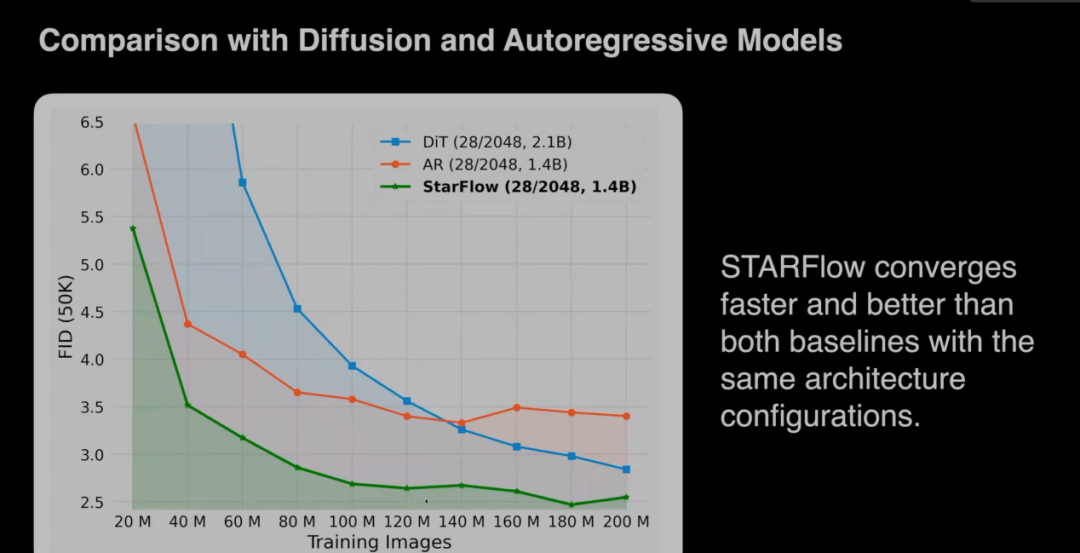
STARFlow在图像生成上取得了较好的效果,在收敛速度和生成质量上均比现在同参数量的扩散模型和自回归模型要更好。同时该模型也可以应用在图像编辑中,并取得了较好的效果。
顾佳涛基于STARFlow原理,开发了全新的视频生成模型STARFlow-V,旨在攻克长视频生成中常见的误差累积难题。该模型采用了一种独特的双层自回归流架构:底层利用深层网络始终在高斯空间内进行稳定的因果时序建模,而表层则使用浅层网络负责单帧细节的精修。这种设计确保局部生成的错误不会反向传播干扰时序主干,从而将累积误差限制在高斯空间内部,保证了视频生成的长时连贯性。

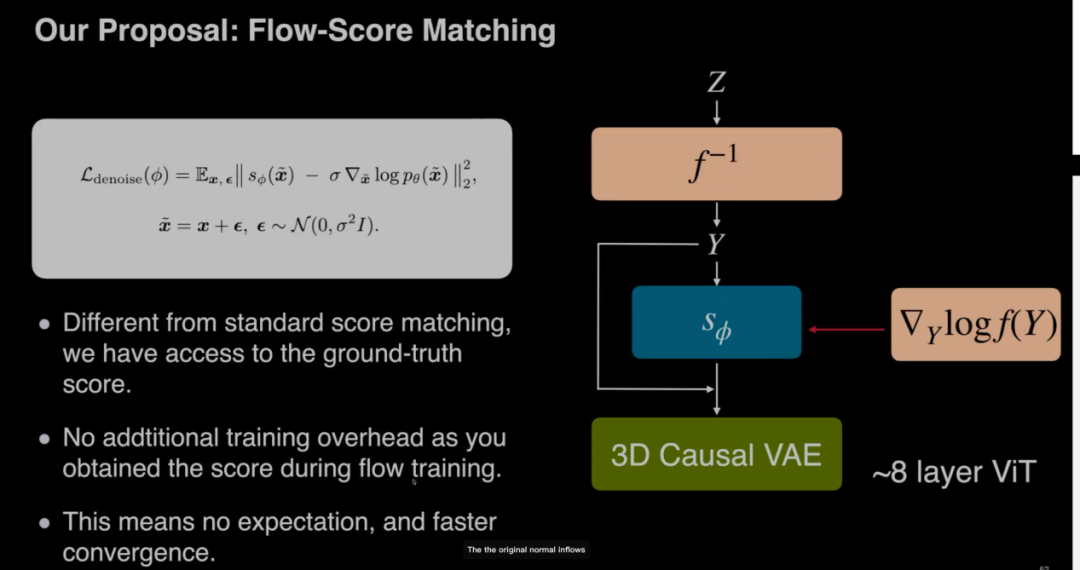
针对视频生成中容易出现的画面伪影问题,STARFlow-V 创新性地引入了“Flow Score Matching”机制。顾佳涛发现,直接沿用流模型输出的原始评分往往不够完美,容易导致动态场景中出现尖锐噪点。为此,他设计了一个独立的、可学习的因果去噪器,以流模型的输出为指导,利用神经网络天然的平滑特性对原始信号进行过滤和修正。这不仅有效消除了高频伪影,还大幅提升了视频画面的纯净度与动态表现。
得益于归一化流天然的可逆性,STARFlow-V 实现了编码与解码的完美统一,成为一个无需额外适配器即可适应多任务的全能模型。无论是文生视频、图生视频,还是长视频续写与编辑,都可以通过将数据“反向”映射回潜空间来实现,极大地简化了工作流。此外,为了提升推理效率,模型还结合了类似推测解码的块级循环迭代技术。STARFlow-V成功证明了在扩散模型的主流范式之外,构建高性能、非扩散架构视频生成模型是完全可行的。

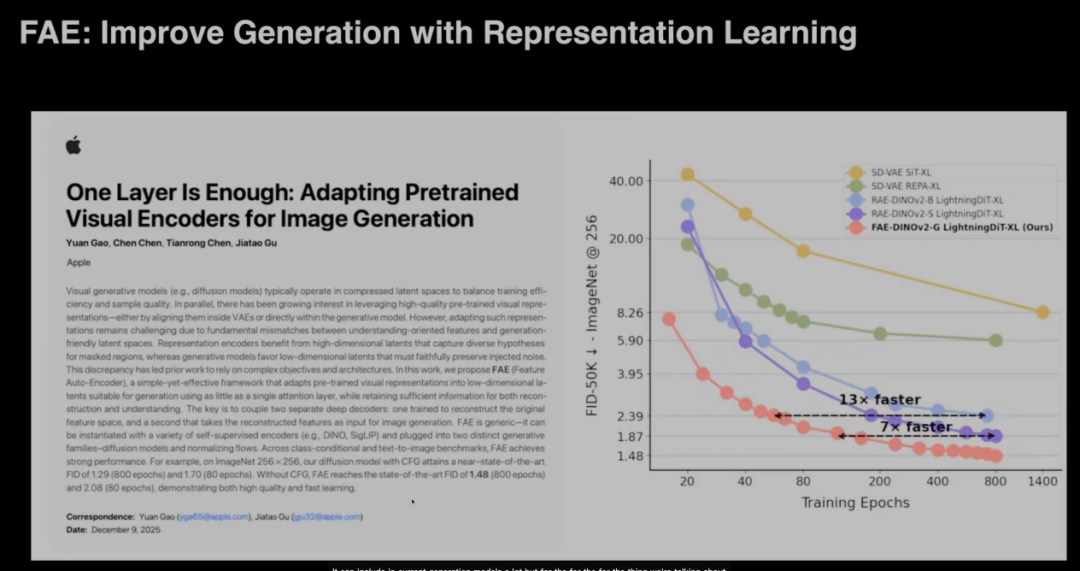
为了解决生成模型效率与质量的平衡问题,顾佳涛提出了一项名为“FAE”的新技术。该技术尝试将DINO或CLIP等强大的表征学习模型与生成模型相结合。通过引入一个轻量级的注意力层,将复杂的表征信息压缩至较小的潜在空间中。实验证明,这种方法不仅能显著加速训练过程,还能大幅提升生成质量,使模型在保留表征编码器丰富信息的同时,具备更高效的生成能力。
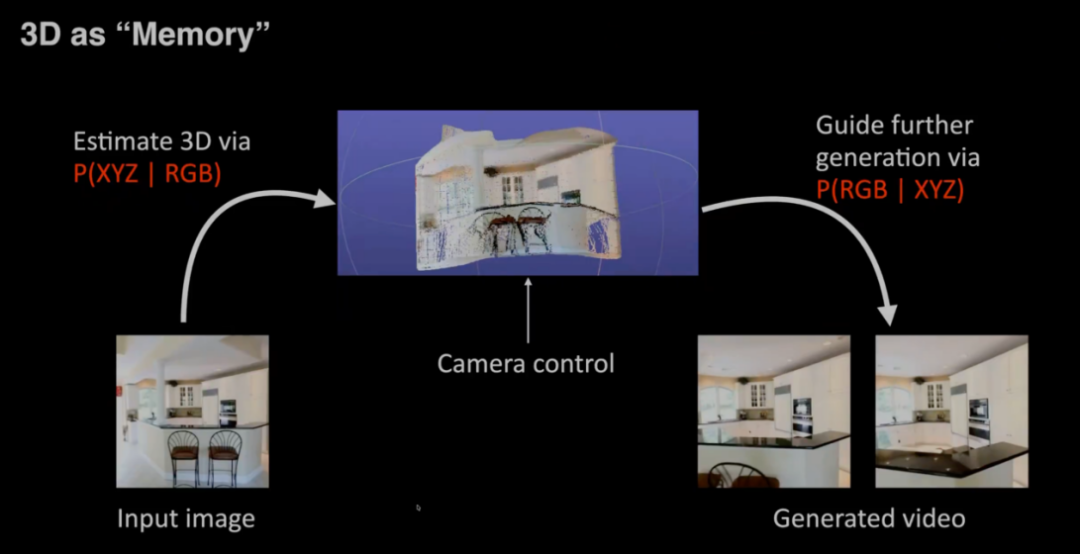
在谈及如何让视频生成更符合真实物理世界时,顾佳涛强调了引入几何信息和物理轨迹的重要性。他介绍了团队在“世界一致性视频生成”方面的工作,即联合建模视频与3D点云,利用3D点作为结构先验来指导生成。此外,他还提到了被NeurIPS收录的相关工作,展示了如何通过预测物理轨迹来引导视频生成,实现符合物理规律的动态效果。
在本期AIR DISCOVER青年科学家论坛,顾佳涛分享了关于“构建鲁棒视频世界模型”的最新研究,旨在通过利用海量互联网视频训练生成模型,以解决通用物理智能面临的交互数据匮乏挑战。针对现有扩散模型缺乏因果性预测能力以及传统自回归模型在连续空间中存在严重误差累积的局限,顾佳涛提出了基于自回归流理论的STARFlow及其视频版STARFlow-V架构。该研究创新性地将连续空间生成约束在高斯空间内,通过引入噪声增强训练、双层自回归流设计以及Flow Score Matching去噪机制,有效克服了长视频生成的连贯性难题并消除了画面伪影,证明了非扩散架构在构建高效、可逆且多任务通用的视频世界模型方面的巨大潜力,并进一步探讨了结合表征学习(FAE)与3D物理先验的未来发展路径。






