11月17日,第47期AIR学术沙龙如期举行。本期活动荣幸邀请到了伯克利前沿基金科技顾问芮勇博士,为清华师生带来一场题为《AI Agent在现实世界的落地:从概念框架到实践演化》的深度分享。

芮勇博士是全球产业界、科技界、学术界三栖领袖。是多家企业、大学、VC 的董事及顾问。现任伯克利前沿基金科技顾问,是前联想集团全球CTO,前微软亚洲研究院常务副院长。他创建了联想首个 AI 实验室,领导15000名研发工程师,是联想智能化转型、端侧智能体、智能制造、智能柔性设备、智能数据中心的技术领导者,助力联想市值上涨三倍。他领导微软总部及亚太的研发团队,为微软的数字媒体、必应搜索、视频会议、Azure AI Services 的多媒体化和智能化做出了重要贡献。他是欧洲科学院及加拿大工程院外籍院士,是 Fellow of ACM/IEEE/AAAS/IAPR/SPIE. 他是清华、北大、中科院客座教授,清华企业家协会成员。是全球多媒体期刊 IEEE Multimedia Magazine 首任华人主编。
在人工智能快速演进的时代,我们越来越关心一个核心问题:AI Agent 如何真正走向现实世界,成为能够“落地”的智能体?两千多年前,屈原在《天问》中提出百余个问题,后人将其总结为“九问”。今天,我们站在人工智能第三次浪潮的中心,芮勇博士同样以“九问”之名,向 AI Agent 的未来提出九个重要的问题。这九个问题将从大模型的局限性与 Agent 的必然性、从概念框架走向可落地的 Agent以及未来趋势展望这三个方向展开。
要理解为什么 AI Agent会成为新的方向,就必须先认识大模型本身的局限。在人工智能这个词诞生的69年里,人工智能经历了两次寒冬,而每一次寒冬的核心原因都是无法在真实世界落地。现在大模型固然强大,产业化也在飞速发展,但仍存在多个关键问题。
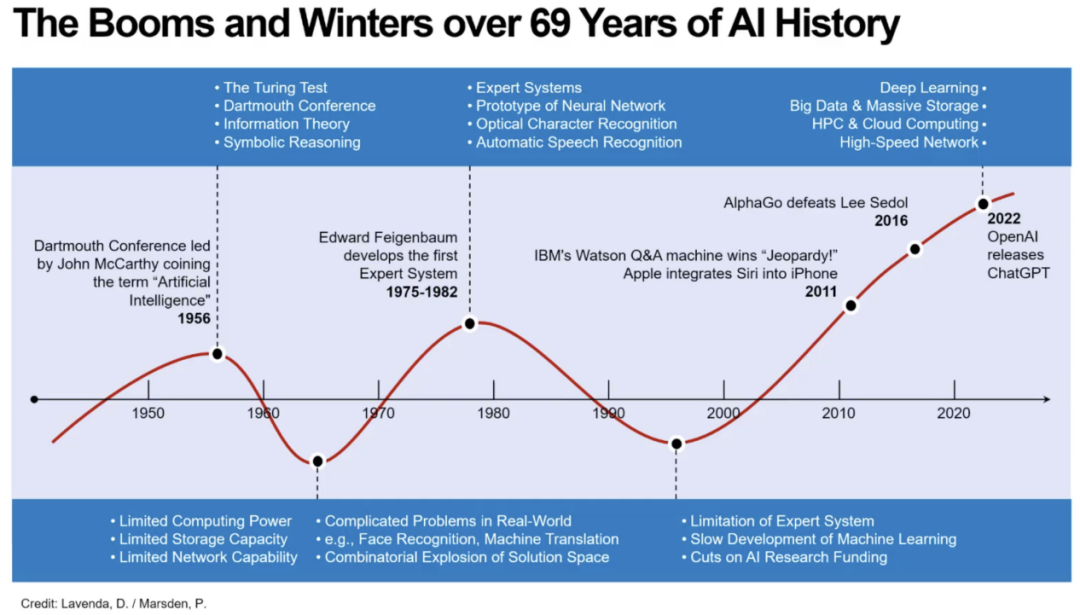
首先便是理解能力不足,例如:让现有最强的大模型读取简单的模拟时钟,准确率只有 39%;读日期,只有 23%。这种人类能轻松获取的基础能力上的短板,暴露出模型在“理解”层面上的结构性局限。其次是存在幻觉问题,大模型会自信地说错。人类对于自己的不确定性是有意识的,而大模型则看似笃定地给出错误答案。最后是缺乏真正的认知能力,例如物理直觉、因果推理、结构化认知等。模型会“照猫画虎”地套用过去的模式,却未真正理解背后机制。
这些问题让我们意识到:光靠一个大模型,不足以支撑真正的智能体。我们需要给它一些列外挂,包括自我认知(Self-awareness)、记忆系统(Memory)、任务分解(Decomposition)、计划能力(Planning)、与环境互动的感知(Perception)和工具与知识库的调度能力(Tool-use)。
Agent 的出现,正是为了解决这些“大模型做不到的问题”。
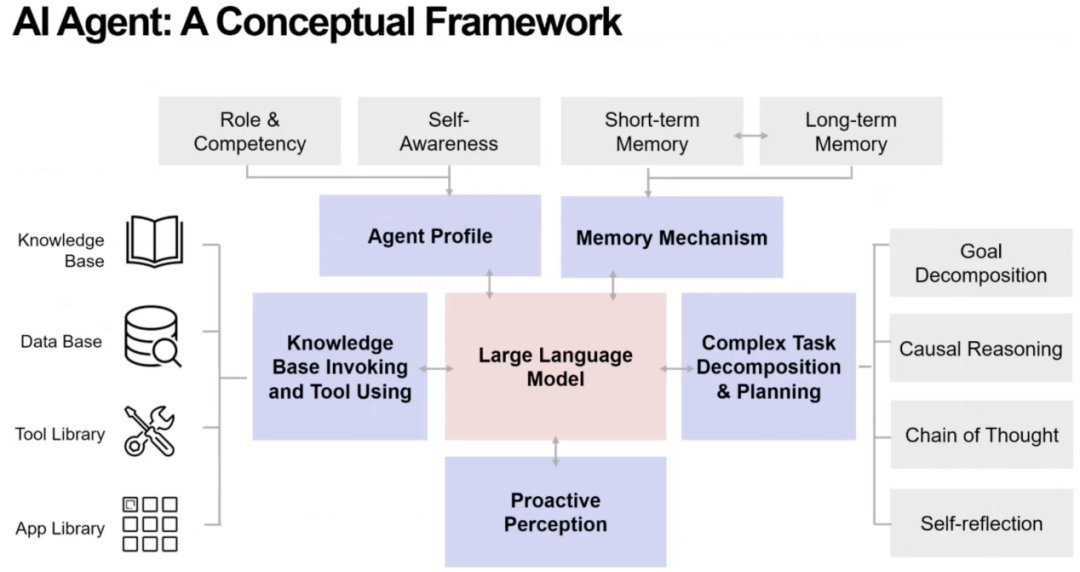
然而,拥有一个宏观框架是不够的,更重要的是:如何真正把 Agent 做出来?
接下来,芮勇博士将对AI Agent的落地和发展进行深刻思考,提出九个重要的问题。
第一问:控制论能否启发AI Agent的设计?
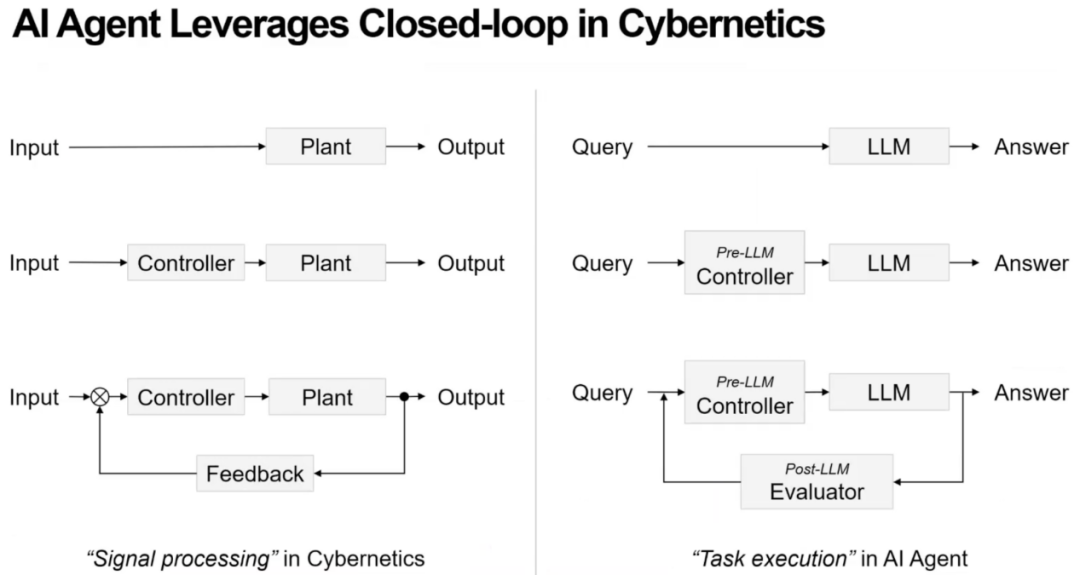
芮勇博士首先提出“第一个问题”:控制论在过去半个多世纪取得巨大成功,其中的思维方式与体系结构,是否能够启发我们今天设计 AI Agents?
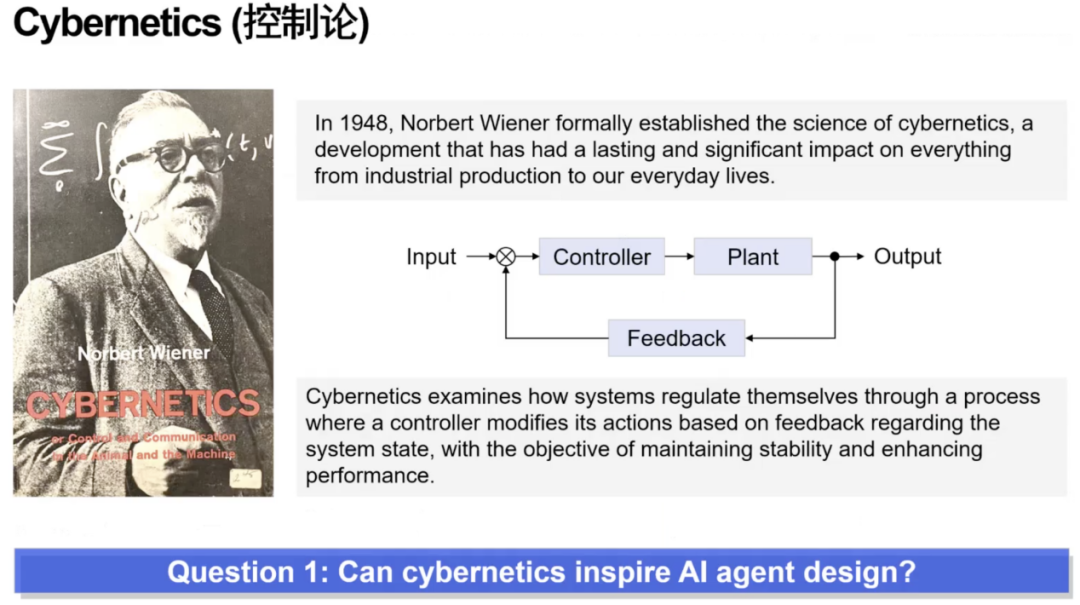
芮勇博士指出,控制论中的经典框架包括:前置控制器(Controller),后置反馈系(Feedback)和被控对象(Plant),而这套结构与当前LLM Agent 架构之间存在高度相似性。
首先前馈控制器对应prompt优化,让大模型输出更准确、更稳定、更可控。例如在数学推理和具身智能的任务中,未加入前馈控制器的情况下,大模型直接接收任务,输出质量往往不稳定,出现遗漏步骤、产生偏差等问题。如果在前面加入一个可学习的小模型作为控制器,将任务自动分解成多个可执行步骤,再将这些结构化信息喂给大模型,则正确率会显著提升。
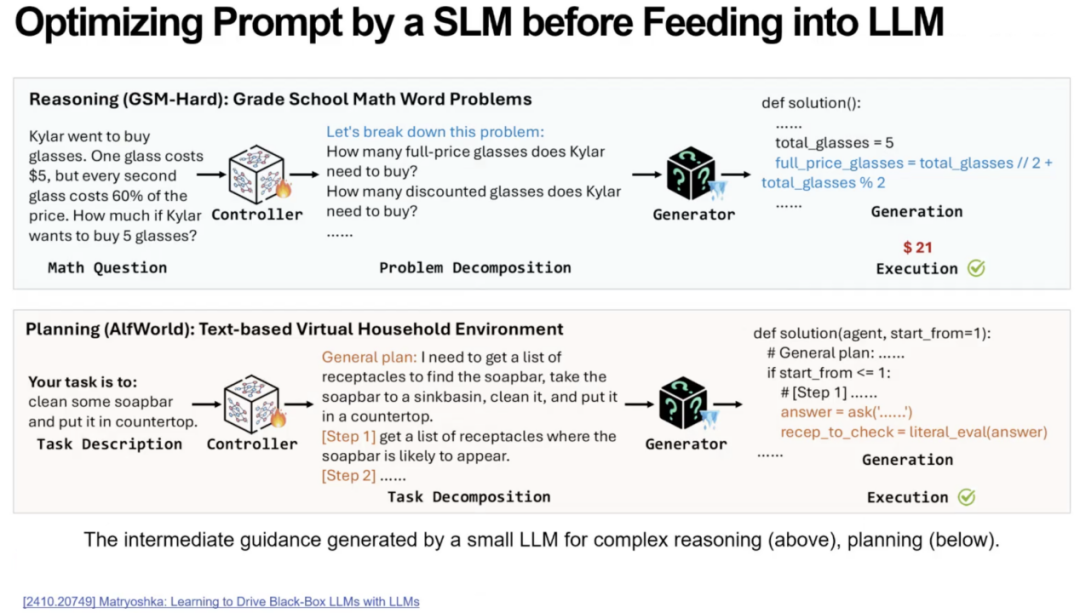
其次反馈机制在 AI Agent 中同样极为关键,而且目前行业已经出现明显趋势——由人类反馈(RLHF)向 AI 反馈(RLAIF)转变。例如OpenAI 的CriticGPT,用 GPT-4 生成程序代码,再用另一个 GPT-4 模型进行代码审查。结果非常显著,错误检查效率提升 60%。系统形成了“模型纠模型”的自循环反馈,不再依赖大量人工注释。
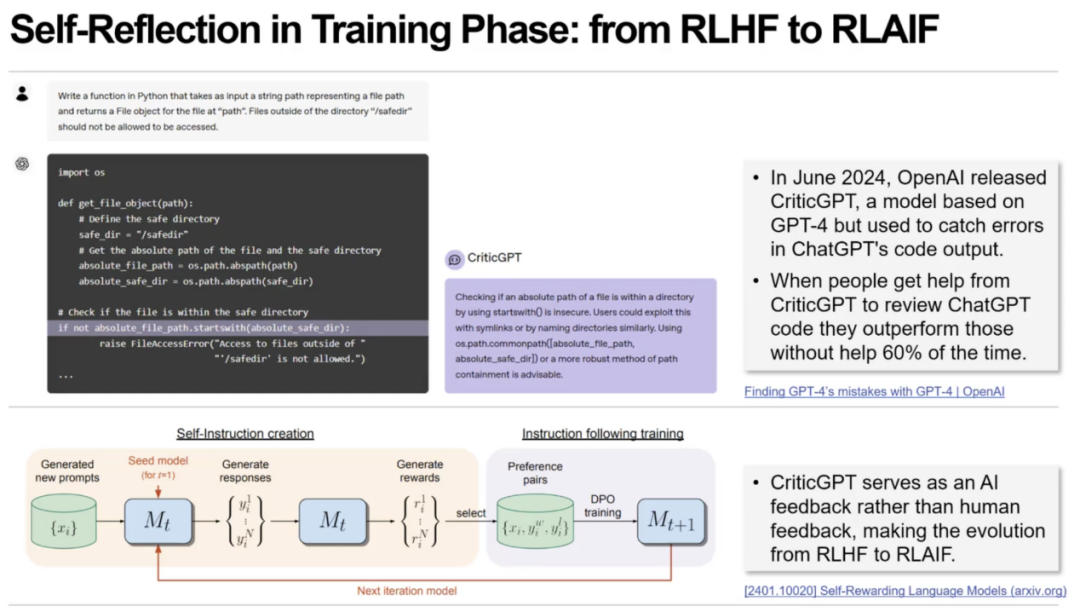
芮勇博士总结到,控制论思想正在重新启发 AI Agent 的结构设计。其中大模型是被控对象,小模型作为前馈控制器使系统更稳定、更可控,反馈机制让系统实现自我闭环。控制论的结构与 Agent 架构高度一致,启发 AI Agent 的设计与实现。并且未来的 Agent 系统很可能沿着“前馈 + 反馈”的闭环路径持续演化。
第二问:认知心理学能否启发AI Agent设计?
接着,芮勇博士将关注点转向了大模型的 记忆(Memory)机制。芮勇博士指出,当今基于 Transformer 架构的大模型在本质上存在结构性限制,缺乏真正意义上的记忆系统。这与人类认知方式存在根本差异,也可能成为未来系统能力提升的瓶颈。从而芮勇博士提出第二个问题,认知心理学能否启发AI Agent设计?
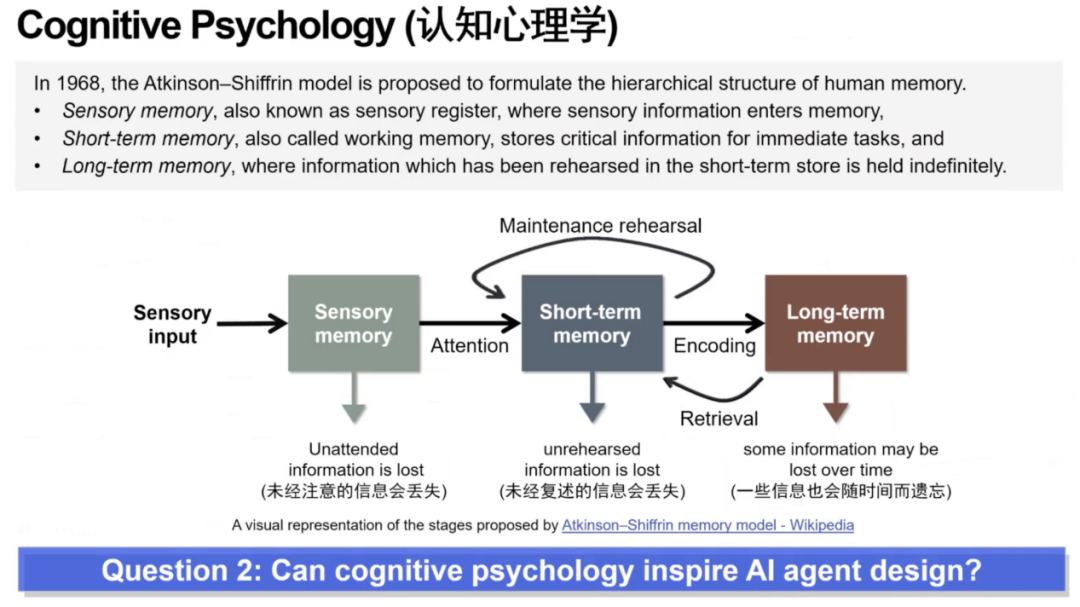
首先,在多轮对话与长链任务中,AI 系统依赖不断增长的上下文序列进行推理,导致上下文窗口迅速膨胀,从而内存与算力消耗急剧上升,推理能力显著下降。相比之下,人类会自动对大量冗余内容进行压缩,将过去的对话或任务归纳成简洁的要点,从而节省工作记忆资源。芮勇博士指出,将人类这种摘要式记忆机制应用于 Agent 的短期记忆,可以显著降低计算负担并提升长序列任务稳定性。
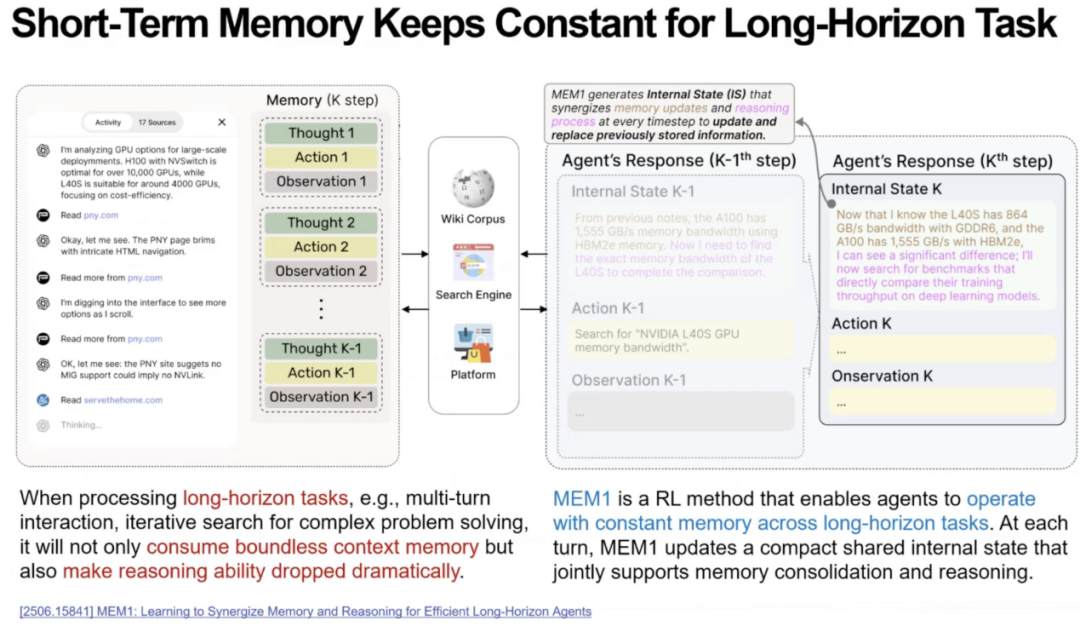
接着芮勇博士指出,长期的记忆能够让Agent持续积累经验,使记忆不断迭代优化,体现出与人类学习方式高度相似的逻辑。芮勇博士以Reasoning Bank为例,说明Agent模拟人类长期记忆与工作记忆的相互作用。Reasoning Bank首先根据当前任务从长期记忆中提取最相关的内容,填充到工作记忆中。接着针对任务执行情况进行结构化总结。这些结构化结果再被更新到长期记忆,从而实现类似人类“学习—固化—提取”的循环。
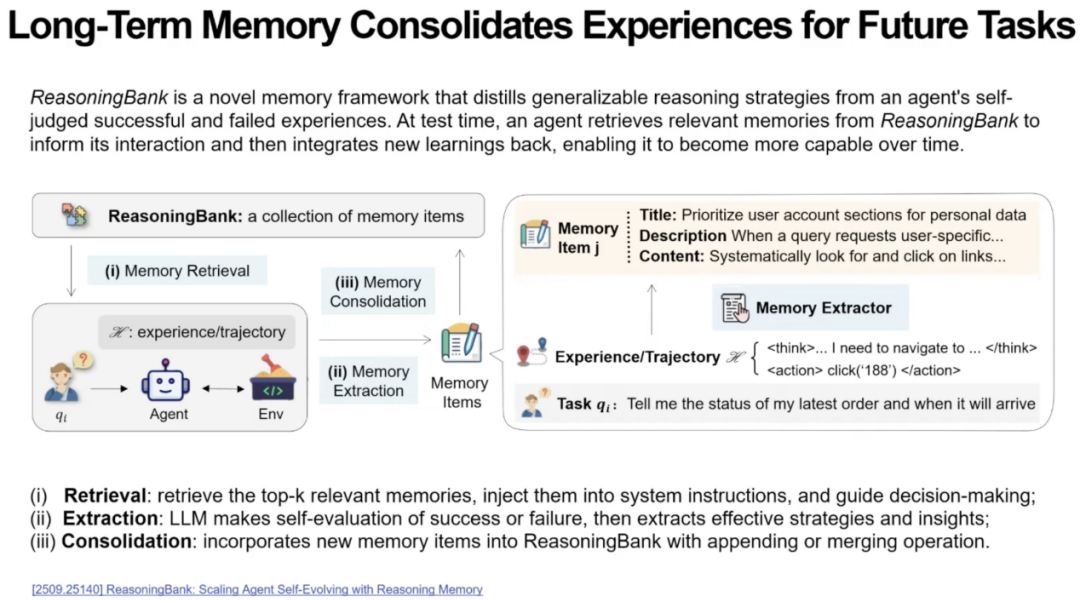
芮勇博士总结到,人类认知心理学关于记忆结构与记忆流动的研究,能够为 AI Agent 的体系化设计提供关键启发。无论是短期记忆的压缩方式,还是短期与长期记忆之间的动态交互,都将是构建更智能、更可持续进化的 Agent 系统的核心方向。
第三问:计算机网络能否启发AI Agent的设计?
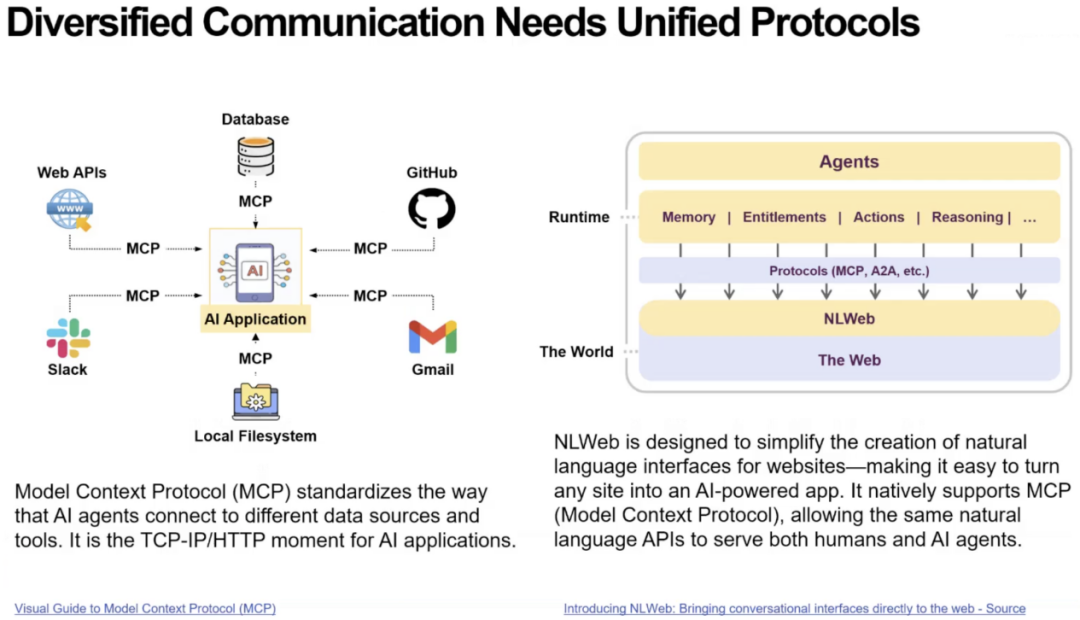
接着,芮勇博士指出,对于支持 AI Agent 运行的“工具”体系,无论是互联网、工具库、应用程序,还是知识库,大模型本身都无法直接调用这些外部对象,必须借助外挂式的工具接口。但这些工具应当如何构建?这一问题可以从计算机网络的设计中获得启发。
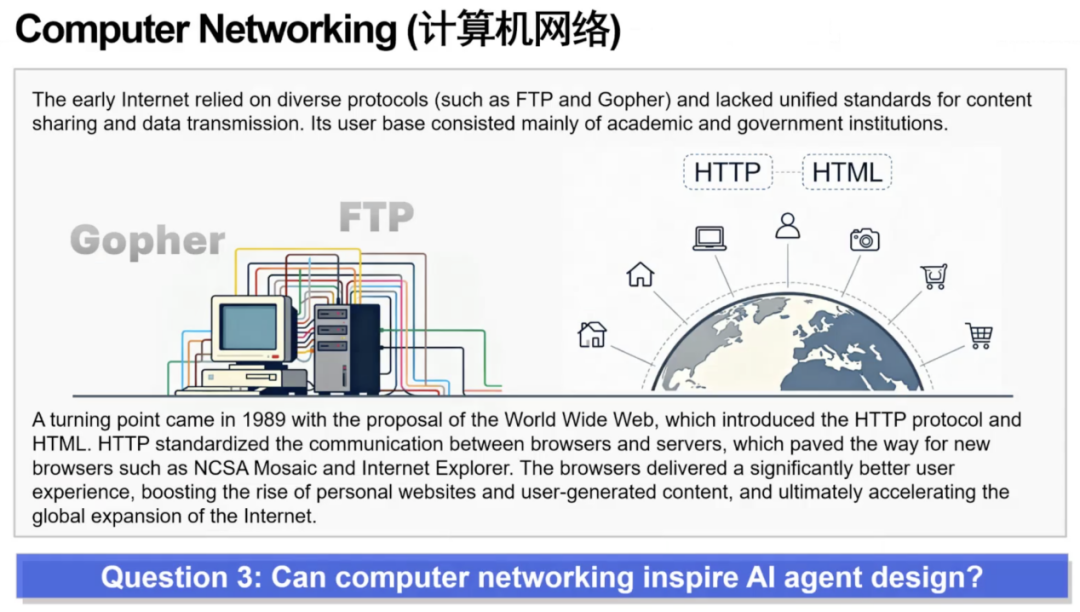
芮勇博士指出AI Agent 如今面临与 1990 年代互联网相同的瓶颈,即缺乏统一协议来访问外部服务。芮勇博士认为,Meta 的 MCP、轻量级的 Skills 以及微软的 NLWeb,正在构建类似“Agent 时代的 HTTP”的基础通信层,使传统服务重新对大模型可访问,并可能像 Mosaic 之于互联网一样,推动 Agent 生态产生爆发式发展。
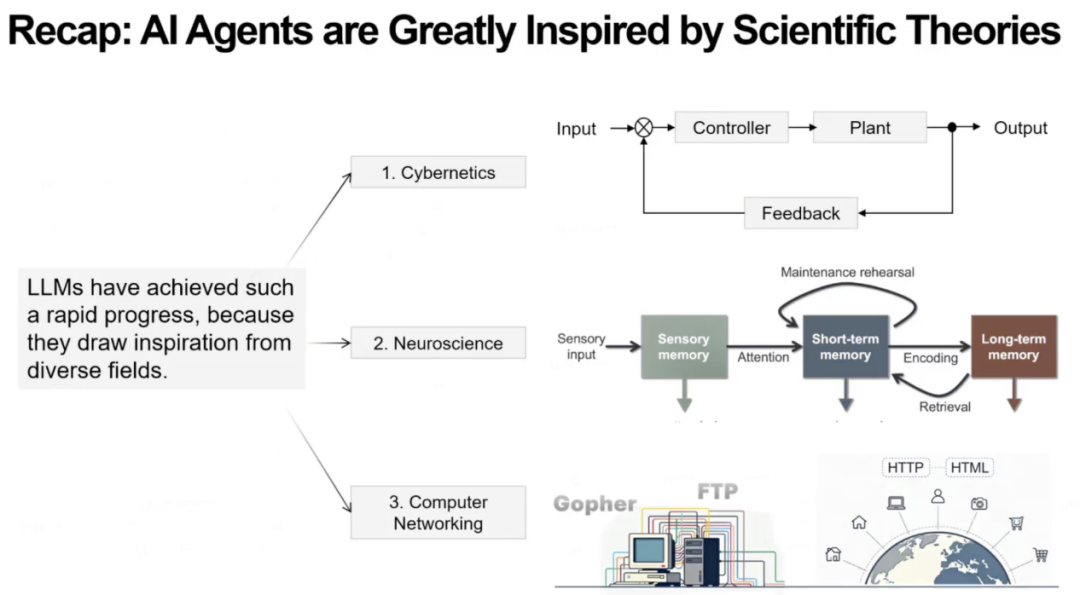
上述三个关于科学理论如何启发AI Agent设计的问题,芮勇博士都为我们指明了答案,其中控制论帮助解决任务分解与系统稳定性;认知心理学帮助设计短期与长期记忆机制;计算机网络理论提供 Agent 访问外部工具的基础设施,推动生态爆发。
接下来芮勇博士继续为AI Agent的开放性问题和未来发展提出深刻的思考和见解。
第四问:语言生成是否能达到人类水平的推理能力?
从 1943 年最早的神经元模型开始,人们逐步发展出人工神经网络与深度学习体系。基于这一视角,芮勇博士指出一个耐人寻味的现象,人类大脑的新皮层中负责语言的区域,与负责推理的区域是分离的。但现代大模型仅通过预测下一 token的语言建模方式训练,却意外表现出一定程度的推理与思考能力。这就引出了第四个问题:仅依靠语言生成的训练范式,是否可能通向类人级推理?这一路径是否科学可行?
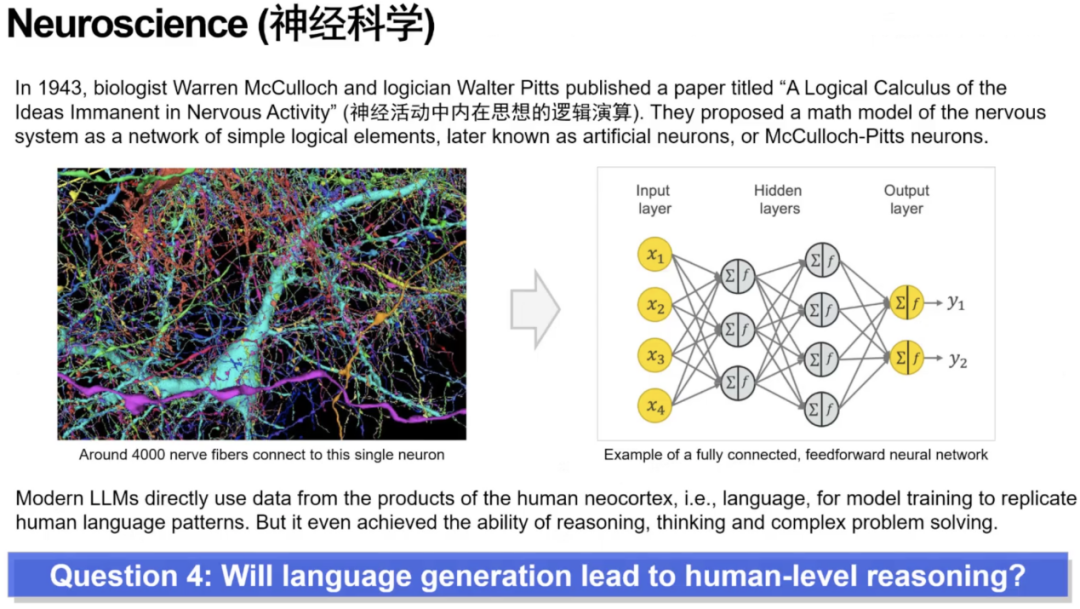
芮勇博士引用 MIT 的脑区激活实验指出,人在进行语言表达、逻辑推理、社会推理时分别激活大脑中完全不同的区域。这些区块功能高度区分,说明语言与推理在人类生理上并没有共用的基础机制。相比之下,大模型却试图依托“语言区域的模拟”(即纯语言建模)去实现推理功能,这在生物学意义上显得不合常理。因此,芮勇博士强调:我们仍无法确定这条路径是否能走通,语言生成是否能真正导向人类级推理仍是一个未解之谜。
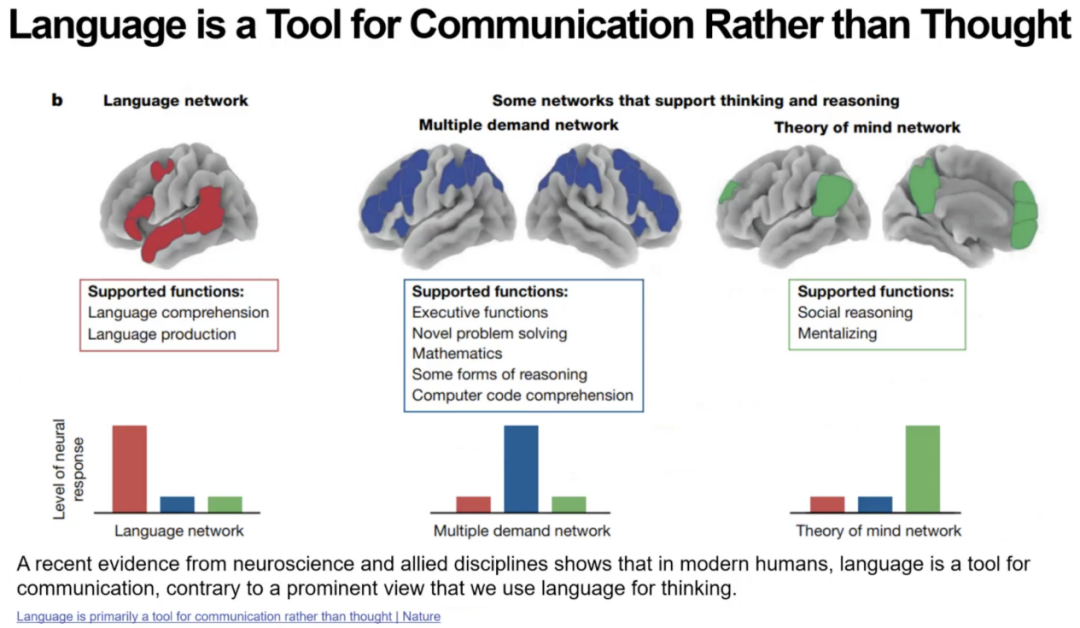
第五问:LLM和人类是否以同样方式压缩信息?
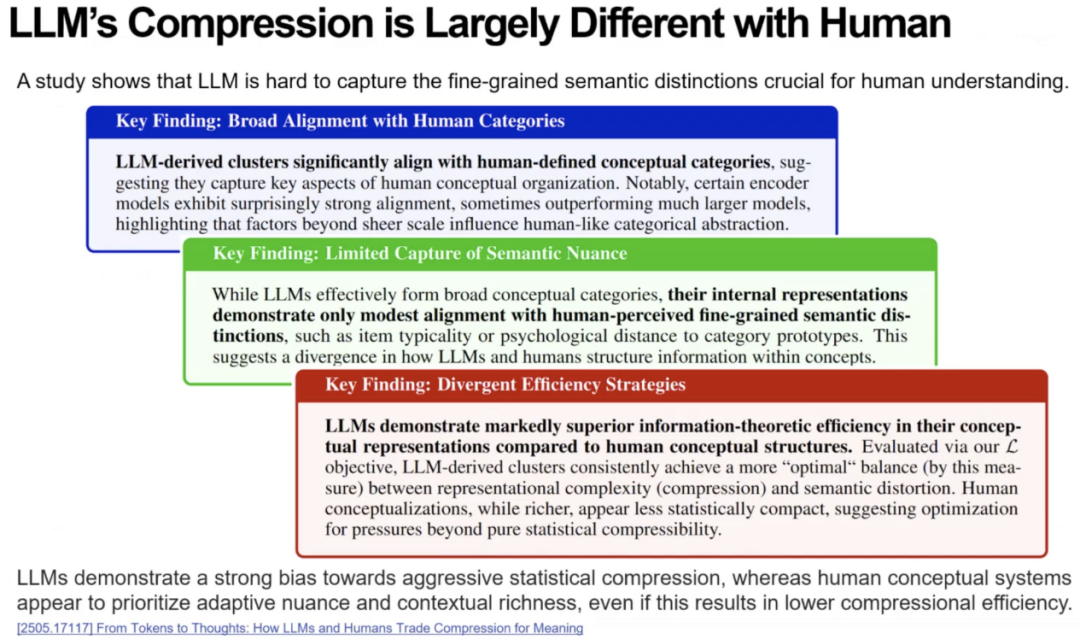
接着芮勇博士指出,在信息论框架下,一个流行观点认为“智能本质上就是信息压缩”。如果能以恰当方式压缩世界的信息,智能便随之涌现。于是芮勇博士提出第五个问题:大模型的压缩方式是否与人类大脑的压缩方式一致?

芮勇博士引用近期Yann LeCun的研究工作,提出有关“大模型压缩对比人类大脑压缩”的三条重要观察。首先,外部分类高度相似,大模型在压缩后形成的语义聚类与人类定义的概念类别有超过 90% 的一致性。其次,内部表征显著不同,虽然分类类似,但大模型内部的表征结构与人类认知机制在细节层面存在巨大差异。最后,大模型压缩效率更强但未必认知更优,大模型的压缩在信噪比方面甚至优于人类,但这种压缩方式可能并非最符合认知规律。
因此,芮勇博士强调。如果大模型的压缩与人类截然不同,我们是否仍然走在通向真正智能的正确道路上?
第六问:统计学习是否实现真正的理解?
第六个问题聚焦于统计学习能否真正产生“理解”。芮勇博士指出,人类只需要极少的样本就能形成概念(例如小孩看三只猫就能认识“猫”),而机器学习尤其是深度学习往往需要百万级示例才能完成同样任务。基于这种学习方式的根本差异,芮勇博士提出疑问:大模型依赖统计学习的范式,真的能达到真正的理解吗?这一点目前仍然没有答案。

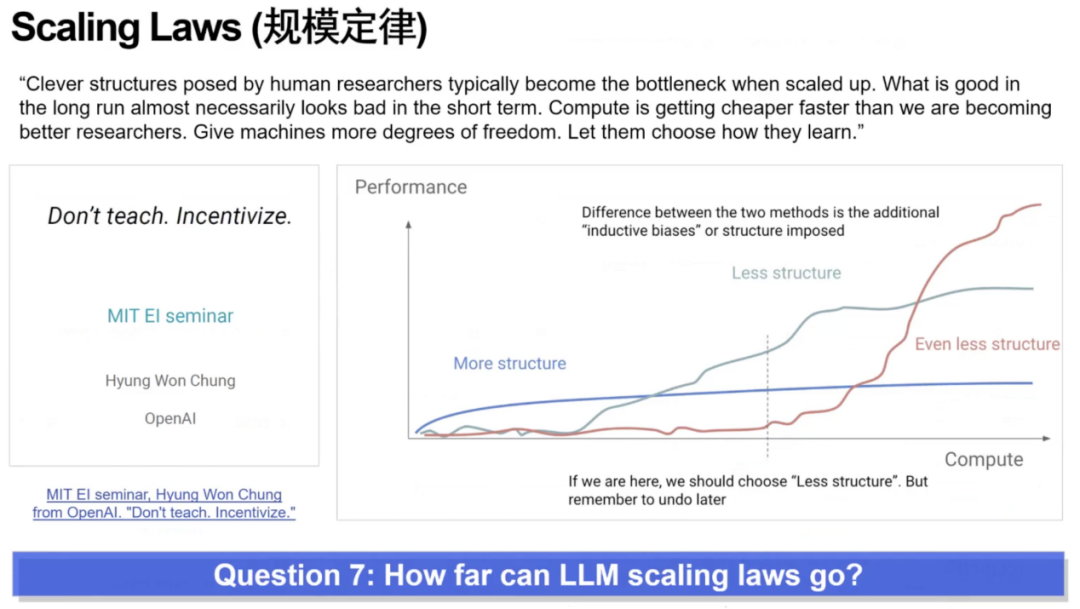
第七问:LLM的Scaling Law能走多远?
第七个问题围绕依赖 Scaling Law 的AI能走多远。芮勇博士指出,深度学习的发展历程从 FCN、CNN、RNN、LSTM 到 Transformer,一路都依赖不断设计更好的结构,因此形成了第一类观点:继续优化结构、寻找更合适的拓扑,是性能提升的关键。但另一类观点认为:许多结构是因过去算力与数据不足被迫设计的“捷径”;在数据与算力足够大时,反而是更少结构、更自由的超大模型能在规模极致后超越复杂结构。问题的核心在于:未来智能的突破究竟来自结构工程,还是来自无结构模型在极端规模下的自我涌现?
第八问:预训练对于快速演化是否必要?
芮勇博士的第八个问题讨论经验学习和进化。以图灵奖得主 Richard Sutton 为代表的一派认为人类是“无预训练”的,完全依靠 on-the-fly 学习,因此大模型依赖大规模预训练是根本错误的方向。以 Andrej Karpathy 为代表的另一派则认为人类其实拥有经过数百万年进化而积累的“DNA 预训练”,而AI没有这段漫长的演化,因此预训练反而是必要的“快速演化捷径”。由此芮勇博士总结到:预训练在没有演化时间的情况下可能是必须的,但远远不够,持续学习仍然是不可替代的关键环节。

第九问:AGI是否需要新的架构?
最后,芮勇博士提出了“理论完备性”的终极发问:当下的大模型范式究竟只是需要若干关键突破与局部增强(如 memory、tool use、task decomposition)的“可修补体系”,还是像 Hinton 所说那样在根本上走向瓶颈、必须被彻底重建?与 Hassabis 认为“或许只差一两次突破”即可抵达 AGI 的乐观态度形成鲜明对比,这个问题直指 AI 研究的根基——我们是在完善一座已成型的大厦,还是在面对一个需要重新设计的结构?芮勇博士坦言,答案目前无人知晓,这正是未来最值得探讨的不确定性。

最后,芮勇博士总结到,回到这九个问题本身,它们其实构成了一个从实践到趋势、再到前沿思辨的完整结构。前三个问题给出了可落地的方法论,中间三个问题带来了值得持续观察的趋势,而最后三个问题更是尚无定论的开放探索。也正因为未知,我们才不断走向研究的边界。
在这九个问题里,我们既看到 AI Agent发展的清晰路径,也看到通往未来的巨大不确定性;而正是这些确定与未知,共同构成了当下最迷人的时代命题。






