11月28日,由清华大学智能产业研究院(AIR)与万国数据联合举办的慈善公益AI主题分享会暨 AIR 学术沙龙第48期顺利举行。清华大学计算机科学与技术系万国数据教授、智能产业研究院执行院长、人工智能医院联席执行院长刘洋教授以《大模型驱动的可进化智能体》为题作报告,从大模型与智能体的发展态势谈起,系统介绍了团队在可进化智能体方向的最新研究进展与人工智能医院等实践探索,围绕“智能体能否像人一样在真实环境中持续进化”等问题展开了深入分享。
刘洋,清华大学万国数据教授、智能产业研究院执行院长、计算机科学与技术系副系主任、人工智能研究院副院长,国家杰出青年基金获得者。研究方向为人工智能、自然语言处理、AI for Science,主持科技创新2030“新一代人工智能”重大项目、国家自然科学基金委国际合作项目等重要科研项目,获得国家科技进步二等奖1项、省部级与一级学会科技奖励5项、重要国际会议优秀论文奖4项。主要学术兼职包括中国人工智能学会组织工作委员会秘书长、中国中文信息学会计算语言学专委会主任等。曾担任ACL亚太分会创始执委兼秘书长、Computational Linguistics编委、中国中文信息学会青年工作委员会主任。
大语言模型近年来发展迅速,人工智能进入新的历史发展阶段。当前呈现的态势是:大模型作为智能“灵魂”,提供内部核心能力支撑;智能体作为智能“载体”,承接外部应用场景赋能。在真实、复杂、动态的环境下,自主智能体有望像人类一样具备可进化性,在持续交互中不断自我提升,且其进化速度呈现出超过人类的潜力与趋势。围绕这一判断,刘洋教授提出智能体进化的基本准则——人类、环境与智能体的统一对齐,并分别从单智能体的“智商”进化、单智能体的“情商”进化以及多智能体的“组织”进化三个层面,介绍团队近期的一系列研究工作,展示了可进化智能体的技术可行性和应用前景。未来,随着智能体群体在大规模环境中持续协作、不断进化,我们或将迎来第二次智能涌现,推动人工智能迈向更高层级的发展。
一、大模型为“灵魂”,智能体为“载体”:AI发展的新阶段
刘洋教授首先回顾了自 2022 年底 ChatGPT 问世以来大模型技术的快速演进:大模型能力迭代几乎以“加倍”的速度在推进——过去需要二三十年才能完成的积累,现在往往在几年甚至几个月内就能实现。伴随这股浪潮,人工智能正在形成两个愈发清晰的技术态势:大模型成为智能系统的“灵魂”,智能体成为智能落地的“载体”。
首先,大模型正逐渐成为各类智能系统的“通用大脑”,为机器人、金融、医疗等场景提供理解、推理与生成能力,其发展路径也从早期的单模态、专用模型,快速转向能够同时处理文本、图像、音频、视频等的多模态通用模型。
与此同时,智能体(Agent)这一概念迅速兴起,成为推动智能真正落地的关键。智能体本质上是以大模型为内核,更像是“能工作的人”,而不仅是“回答问题的模型”。智能体具备记忆、工具使用、环境感知、规划决策与协同合作等能力,能够下沉到千行百业的具体场景中。单个智能体通过调用工具(如搜索引擎、计算器、专业系统等)可以显著扩展自身边界;多个智能体协同工作,则能完成远超单个模型复杂度的复杂流程。
值得注意的是,这一趋势并不仅仅源于技术堆叠。过去几年,学界和工业界一度沉迷于“规模崇拜”:从十亿、百亿、千亿到万亿参数,普遍认为模型越大越聪明。然而实践发现,当参数规模超过一定阈值后,仅靠“堆参数”难以获得质的突破。与人类文明类似,人类的脑容量几千年来几乎没有显著变化,但技术、社会与产业体系的跃迁却从未停止。真正推动文明飞跃的,是更强大的工具能力与更复杂的组织方式。人工智能的发展也正在走向这样的路径:通过工具,扩展单体智能体的能力;通过组织,让多智能体涌现协作智能。
刘洋教授还强调,在智能体方向上,国内外大致处于同一起跑线,而中国在网络基础设施、应用生态和数据体量方面具有明显优势,有机会在这一新赛道实现“从并跑到领跑”。
二、可进化智能体的核心理念:智能体-人类-环境统一对齐原则
在上述判断基础上,刘洋教授团队提出了“可进化智能体”的总体构想:不再将智能体视作一次性训练好的静态系统,而是把它看成一个在环境中长期进化的动态个体——通过不断交互、吸收反馈、总结经验,实现类似达尔文进化的“适应—调整—提升”闭环。
要让这种进化可持续且可控,团队提出了智能体-人类-环境统一对齐原则的要求:1)与人类意图对齐:智能体在真实环境中会不断与人交互,必须理解人的目标与意图,使其行为和经验积累始终朝着人类可接受的方向发展;2)与客观环境规律对齐:智能体要能适应并遵循任务环境中的动态变化,例如电商系统的页面更新、实时推荐机制或医疗流程的时序约束,确保策略在真实世界中的有效性;3)与自身资源约束对齐:智能体在任务执行过程中受时间、费用、算力等约束,需要追求效率和性价比最优。
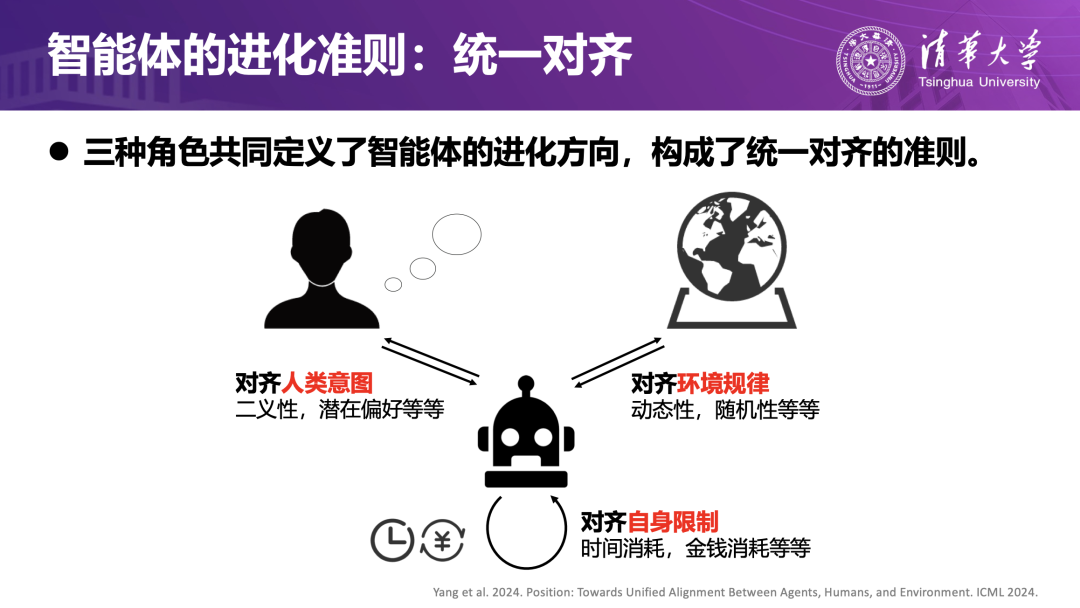
围绕这一原则,团队把智能体进化拆分为三个互相关联的层面:1)单智能体的 “智商”进化:单智能体能否完成设定的目标;2)单智能体的 “情商”进化:单智能体能否在群体博弈中作出恰当策略选择;3)多智能体的 “组织”进化:能否形成高效团队协作完成复杂任务。
三、“智商进化”:从错误与自标注中持续学习
在智商进化层面,团队关注的问题是:如何让智能体像人一样“吃一堑、长一智”,在任务中不断学习和成长。
(1)错误反馈驱动的经验学习
在实际部署中,大模型的参数基本是固定的,难以像传统机器学习那样通过再训练来更新知识。这意味着:当智能体遇到新问题时,即使曾在类似场景中犯过错误,也往往无法自动吸取教训,容易在后续任务中重复出错。
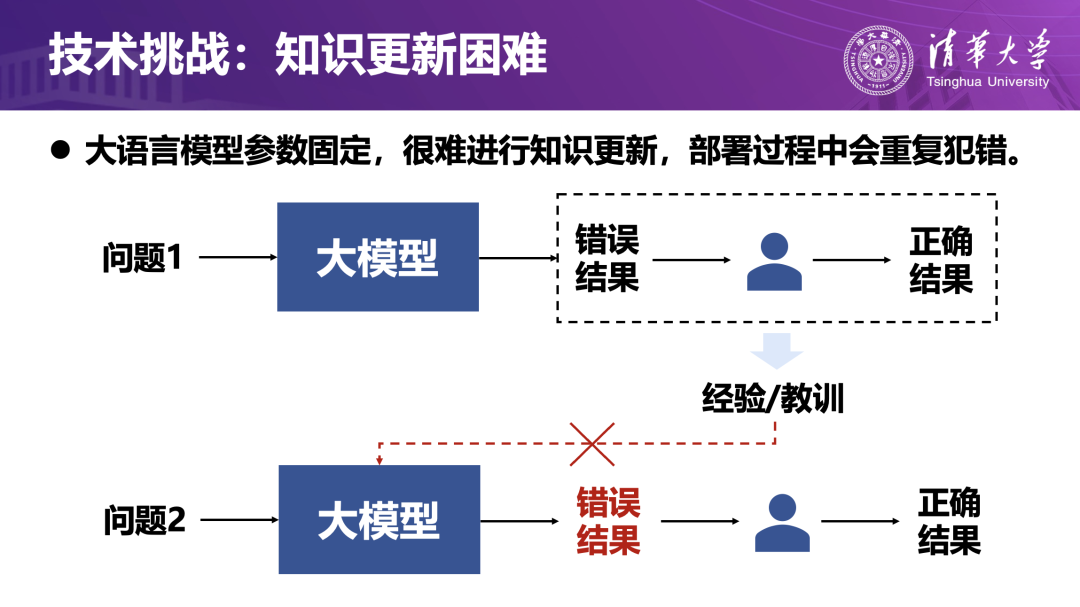
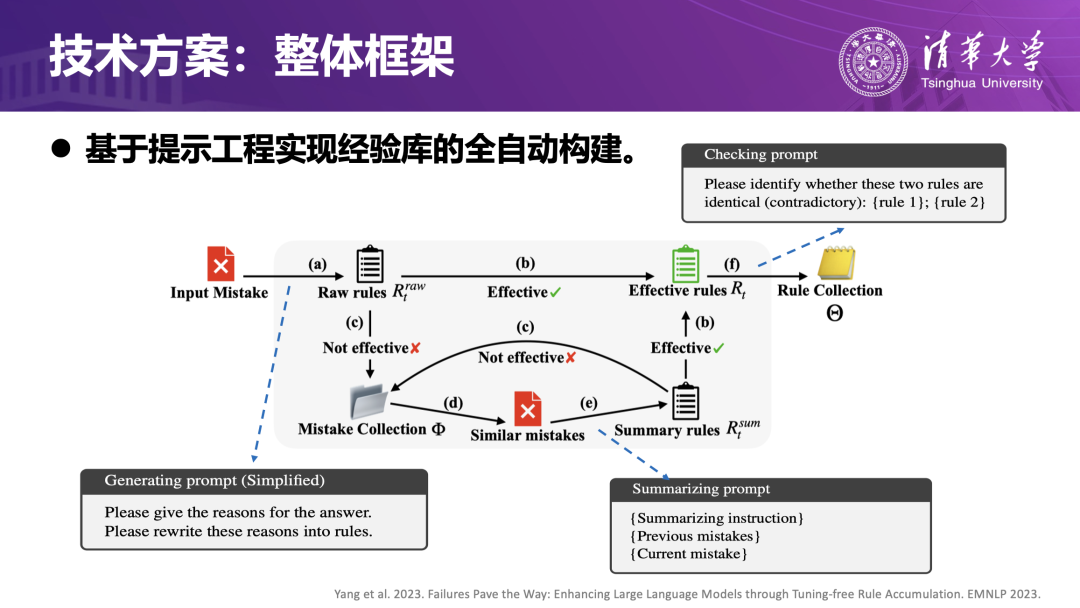
为打破这种“错误无法被记住、经验无法沉淀”的局限,团队设计了基于错误反馈的经验学习框架。当智能体在任务中出现明显错误时,系统会回放上下文,分析“为什么错”;引导大模型自己总结“在什么条件下,应该采用什么更合适的策略”,形成经验规则;再用当前案例和更多未见过的案例检验这些规则的有效性,只有通过检验的规则才会写入长期记忆的经验库;此后在类似场景中,智能体可以调用这些经验,从而减少重复犯错。
相关实验结果表明:随着经验库的不断扩充,智能体在多类任务上的错误率持续下降,而且许多经验具有跨任务可迁移性——在A任务中学到的经验,可以在B任务中帮助其做出更好的决策。
(2)基于自主数据标注的自我训练
智能体的策略学习高度依赖高质量的“交互轨迹”,即其在特定状态下的观察、推理、行动及结果所构成的因果链条。这类轨迹是策略更新与环境适应的关键数据,但传统方法往往依赖人工构造或标注,成本高昂且难以覆盖真实环境的复杂性,从而限制了智能体能力的持续提升。
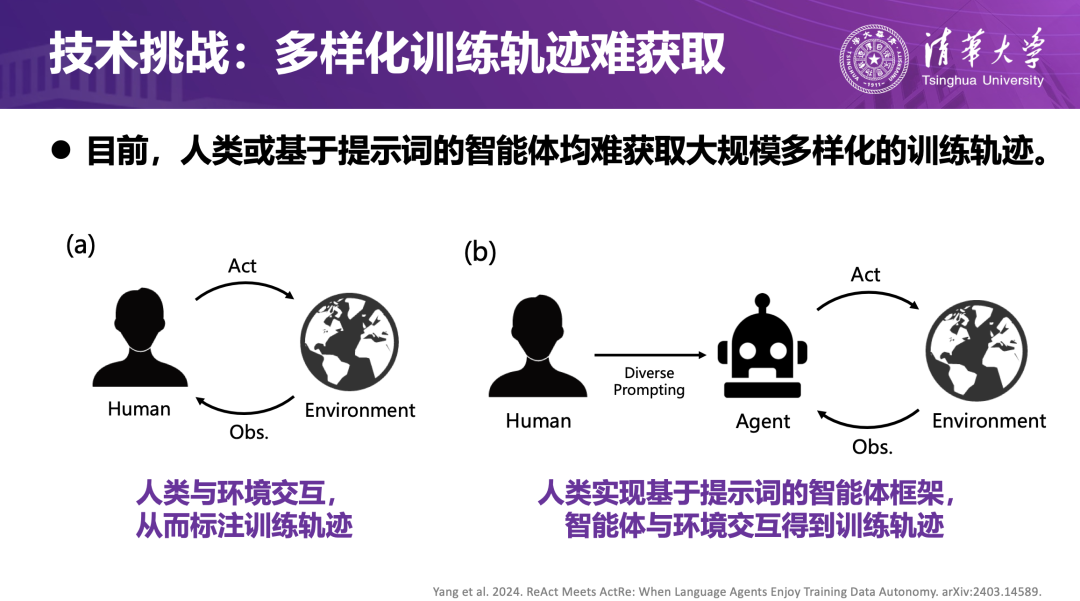
为了解决高质量交互轨迹难以获取的问题,团队在ReAct算法基础上提出ActRe框架,使智能体在执行任务的过程中自动生成可学习的数据。传统 ReAct 虽然能在推理阶段给出“思考—行动”链条,但其动作(Action)的合理性并未得到系统性的标注与校准,难以直接作为训练样本使用。ActRe 的引入,使智能体能够在采样新动作时由模型生成动作背后的“原因”(Reason),将“观察—思考—动作”的过程打包成可学习的交互轨迹;再利用这些自标注轨迹进行对比学习,强调成功轨迹,弱化失败轨迹,不断优化策略。
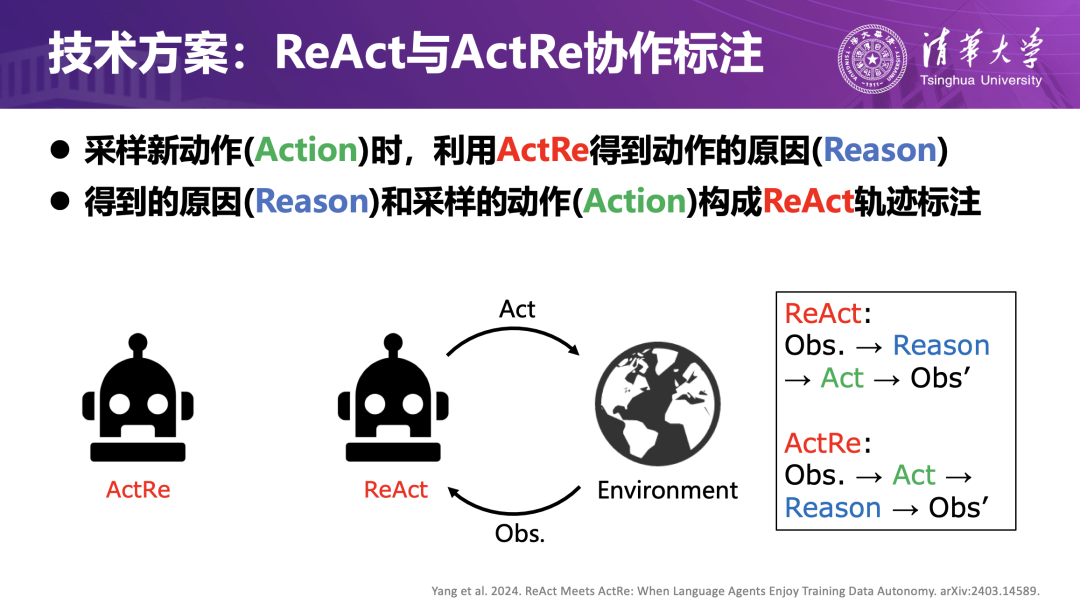
在文本具身平台AlfWorld、在线购物平台WebShop上的实验表明,在无需人工标注的前提下,智能体可以在少数几轮迭代中从“接近普通用户”提升到“接近甚至超过领域专家”的水平,体现了合成数据+自监督学习在可进化智能体训练中的潜力。
由此,错误反馈驱动的经验学习与基于 ActRe 的自主数据标注机制共同构成了智能体“智商进化” 的核心路径:前者使智能体能够从失误中提炼可泛化的策略经验,后者赋予其在真实交互中生成可学习轨迹的能力。二者协同作用,使智能体在多任务环境中表现出持续改进与跨场景迁移的潜力,为打造可进化的自主智能体提供了关键技术支撑。
四、“情商进化”:在语言博弈中习得策略和互动能力
在单智能体任务之外,团队将目光投向多主体语言博弈场景,探索智能体在复杂互动中如何积累策略与表达经验,即所谓的“情商进化”。在德州扑克、外交游戏、狼人杀等多轮语言博弈中,信息往往高度不完全,参与者之间既有合作也有对抗,许多关键决策都依赖发言、判断与博弈策略的综合作用,是研究这类能力的理想平台。
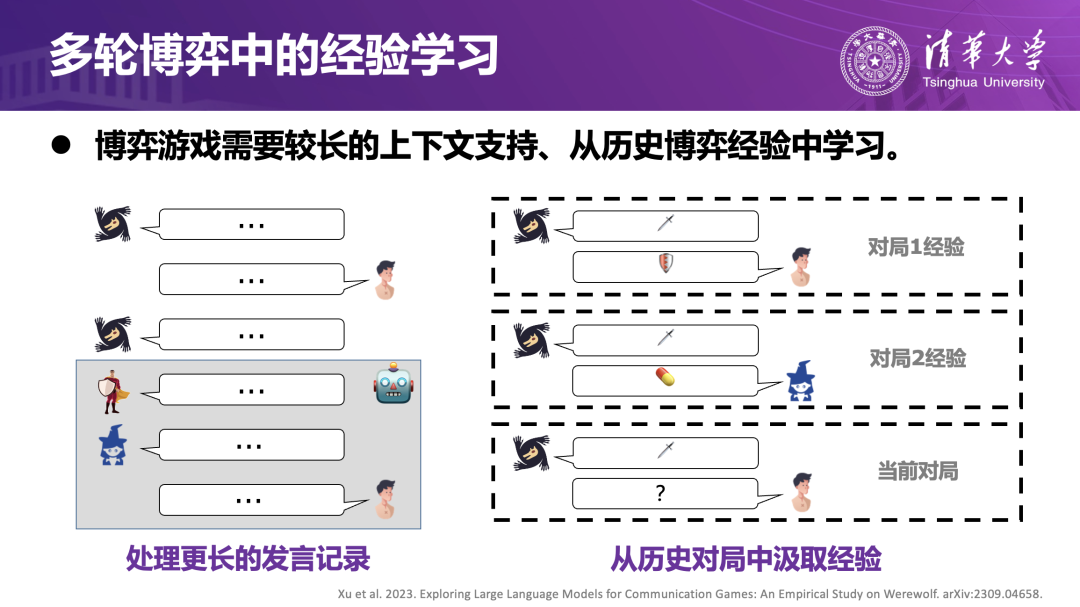
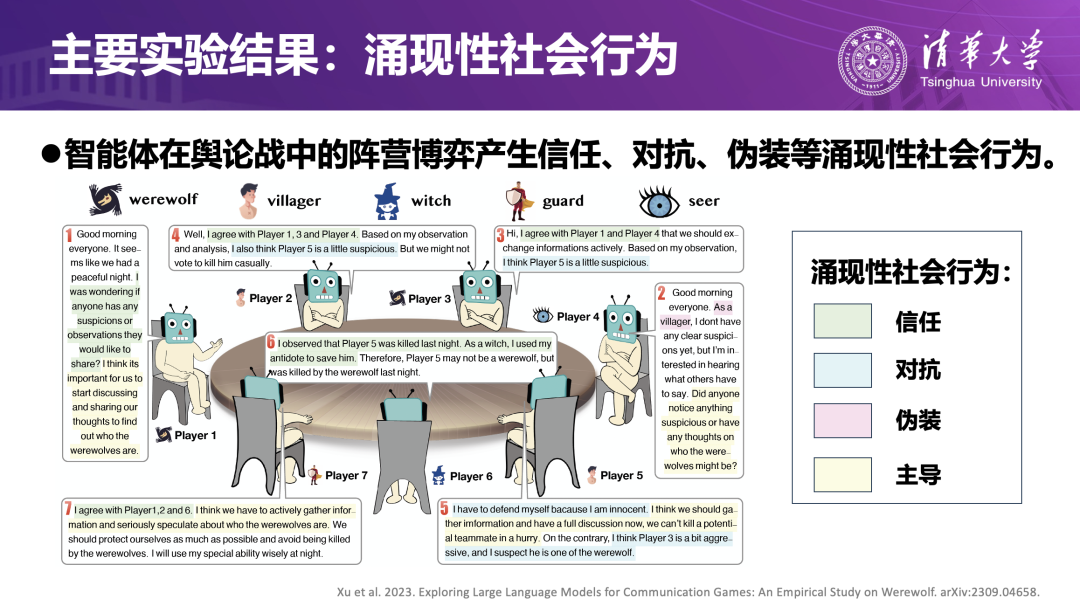
以狼人杀为例,几乎所有信息都通过发言传递。团队构建的系统会:从长对局记录中自动抽取关键发言和关键局面,而不是简单将全部对话塞进上下文;分析不同发言模式与最终胜负结果的对应关系,挖掘“在什么局势下、哪种发言更容易被相信或支持”;将“营造信任”“伪装身份”“主导讨论”等策略沉淀为可复用的社会经验。
在大量对局实验中,研究者观察到多种涌现出的社会行为:稳定的信任链条、针对性的对抗关系、花式伪装策略,以及试图控制舆论走向的“话语领袖”等,说明智能体在长期语言互动中逐步获得理解他人意图、调整自身表达、建立协作或对抗策略的能力,为其向更复杂的多智能体系统迈进奠定了基础。
五、“组织进化”:智能体精英团队组建
如果说“智商进化”关注智能体能否胜任任务本身,“情商进化”关注其在多主体互动中的沟通和博弈能力,那么“组织进化”关注的是:多智能体如何形成精英团队共同完成单个智能体难以独立承担的复杂任务。在现实中,人类组织在面对复杂任务时往往会临时抽调不同部门的成员组建项目组,再在实践中不断磨合角色分工;多智能体系统同样需要在任务协作中演化出稳定而高效的组织机制。
由此,刘洋教授团队提出以数据驱动的“组织进化”机制:从智能体库中随机抽取若干智能体组成临时团队,完成给定任务;根据任务结果,度量每个智能体在本次任务中的贡献度,进行 credit assignment(信用分配);将高贡献成员抽出,组成新的精英团队,并在此基础上探索更合适的组织结构与角色分工;在不同任务重复上述过程,让团队结构在多次迭代中“进化”到更高效的状态。
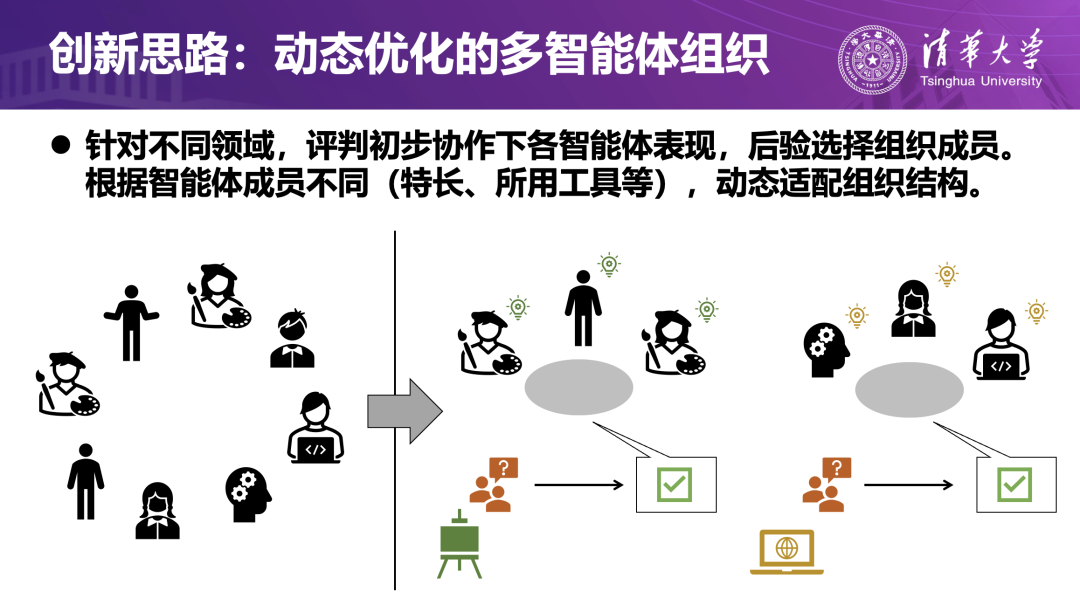
实验发现,在管理学、大学数学、临床医疗等多个领域中,这种组织进化机制能够显著提升整体任务表现。一个颇有趣的现象是:在不同任务上的最优组合虽然不尽相同,但“程序员”形象的智能体几乎总会出现,体现了具备抽象建模与逻辑推理能力的角色,在多学科团队中的关键价值。
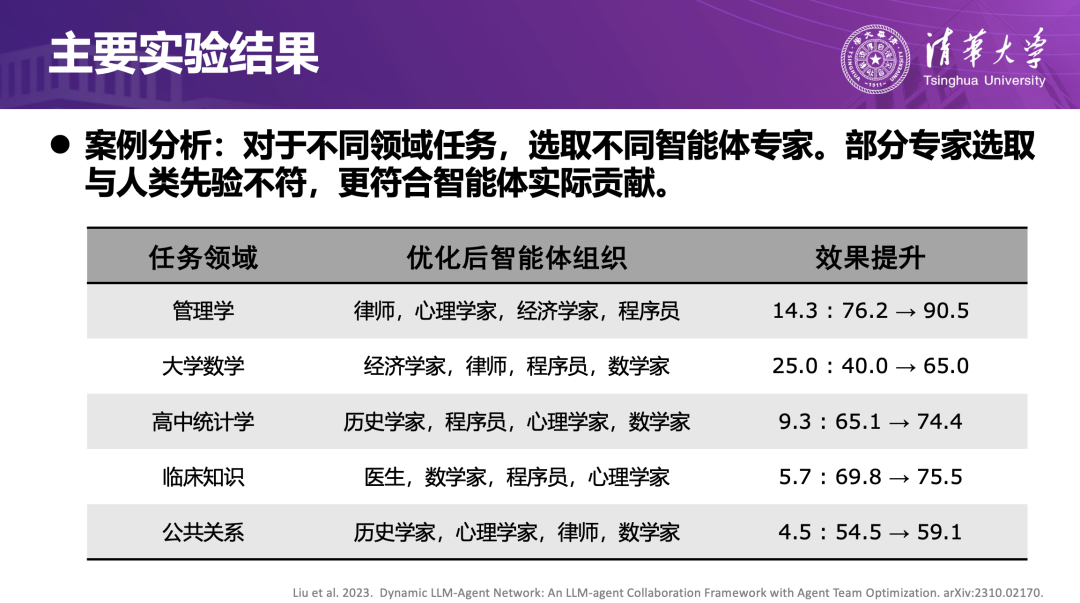
六、实践案例:人工智能医院与可进化智能体闭环
在方法研究基础上,刘洋教授团队进一步将“智商进化、情商进化、组织进化”统一到一个面向医疗场景的可进化智能体平台——Agent Hospital。这一工作受到 DeepMind 强化学习(如打砖块游戏、AlphaGo Zero)和“斯坦福小镇”多智能体社会实验的启发,但研究重点已经从游戏和社会模拟转向解决真实医疗问题。
团队在虚拟空间里构建了一座流程完整的数字医院:患者从发病、分诊、挂号、问诊、检查到康复,形成一个闭环;医院涵盖二十多个科室、上千种疾病,既有带人设的 AI 患者,也有依据不同指南训练出的多类 AI 医生;时间在虚拟世界中被大幅加速,AI 医生可以在“虚拟两年”(现实一两天)的时间里看上万名病人,在成功与失败中持续积累经验并不断演化。
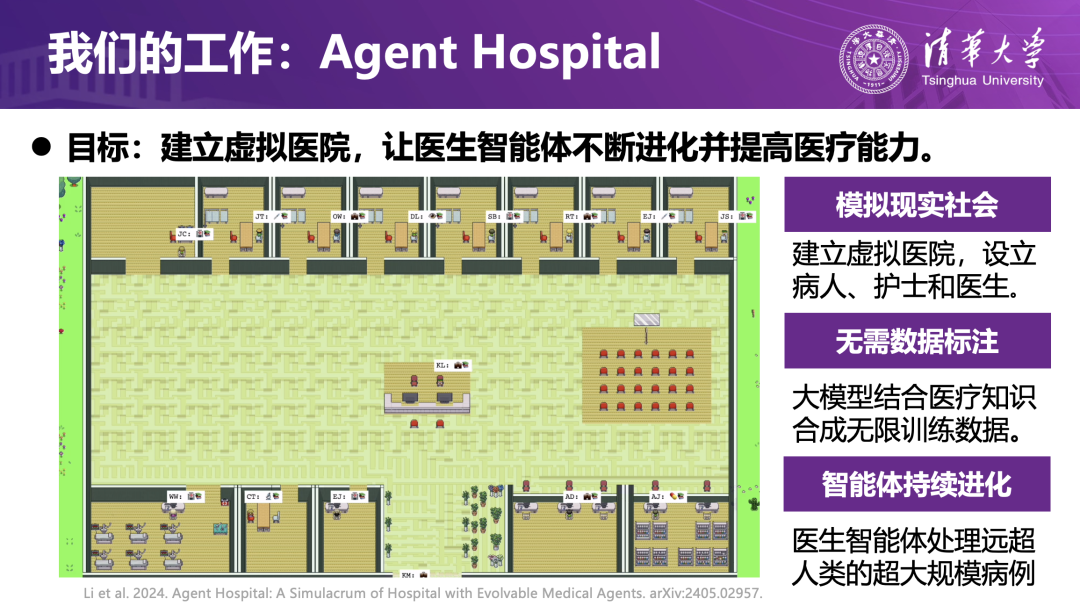
在这一框架下,前面介绍的三类进化机制实现了统一协同:智商进化:AI 医生在每一次问诊中都会积累经验;情商进化:在会诊与沟通环节中,智能体需要与其他“医生”或“患者”进行多轮语言互动,形成策略与表达方面的经验;组织进化:面对复杂病例时,系统会自动从不同“专业”中选出合适的 AI 医生,快速组建会诊团队。
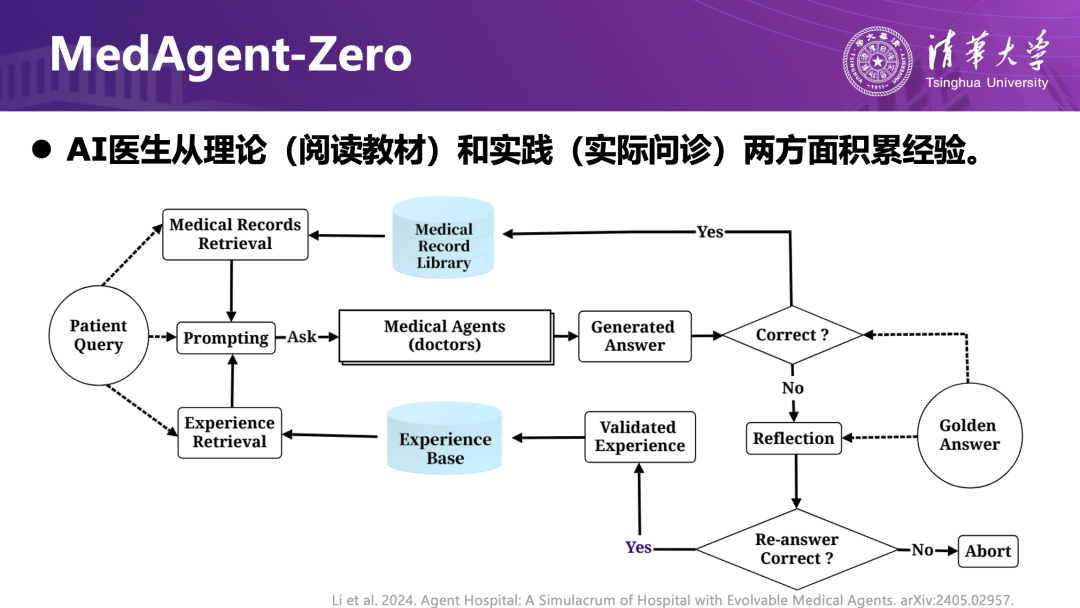
核心算法 Meta-Agent Zero 将成功病例中的正向经验与失败病例中的反思经验分别沉淀,推动 AI 医生在虚拟医院中持续“工作—复盘—进化”。实验结果表明,随着虚拟世界中问诊数量的增加,AI 医生的诊疗能力呈现明显上升趋势;在真实医疗数据集上的测试也显示出与虚拟世界相似的提升曲线,说明这种“虚拟世界进化 → 现实场景迁移”的路径是可行的。同时,基座大模型推理能力的提升也能够直接反哺整个系统,使人工智能医院具备良好的可持续升级能力。
在实践层面,人工智能医院已经形成了较为清晰的应用愿景:面向患者,它支持跨院跨域诊疗、线上线下融合问诊、健康管理与风险预测;面向医护人员,它提供自主问诊、智能分诊、辅助诊疗、个性化模型等能力,帮助提升单个医生的诊疗数量与质量,实现医疗资源的全局优化配置。
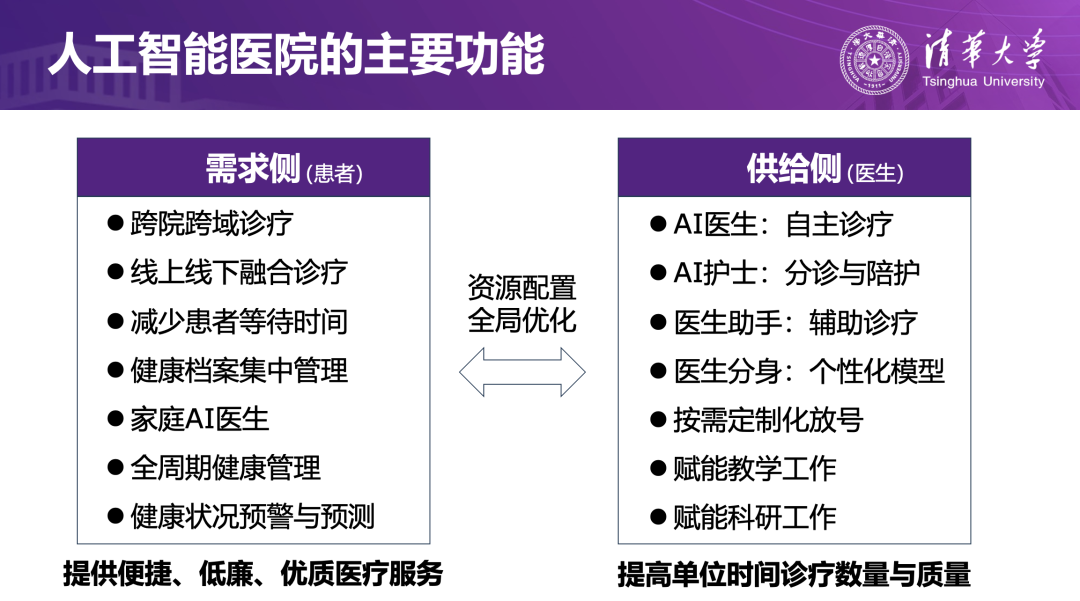
目前,该项目已进入测试阶段,并在国内外多家主流科技媒体与医学/产业媒体(如澎湃新闻网、量子位、MedTech World、China Daily 等)中受到持续关注,被广泛认为是“智能体推动医疗场景AIGC化”的代表性探索。更多细节可参考 AIR 以往官方推送(如《AIR孵化|Agent Hospital首批AI医生上线内测》《AIR孵化|紫荆智康发布Agent Hospital 1,加速推动AI医院技术落地》《AIR快讯|清华大学人工智能医院系统启动公测》)。
七、展望:迈向第二次“智能涌现”
在报告最后,刘洋教授展望了可进化智能体的未来方向。他认为:在高质量标注数据逐渐稀缺的背景下,让智能体在复杂环境中自己获取数据、自己标注、自己成长,将成为人工智能的重要趋势。
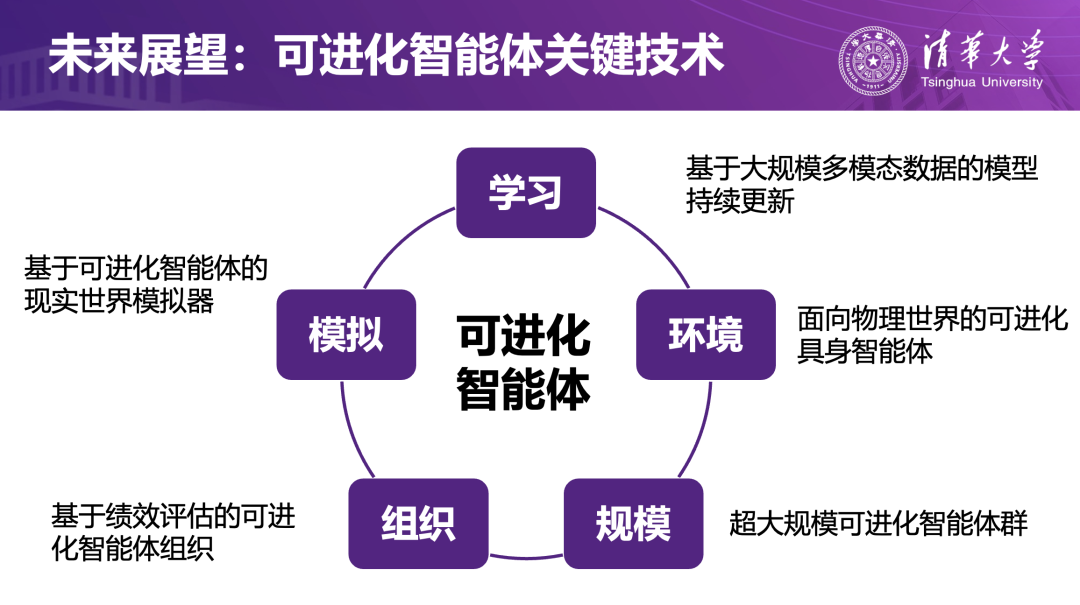
同时,刘洋教授提出了关于“第二次智能涌现”的判断。如果说第一次涌现来自大模型依托算力和数据规模实现的能力飞跃,那么第二次涌现很可能来自大规模智能体群体及其组织形态:单一模型再强,也难以独自承担登月、造芯片等系统工程,而成千上万智能体在有效组织下协同工作,或许能催生新的群体智能。






