9月17日,第44期AIR学术沙龙如期举行。本期活动荣幸邀请到了上海人工智能实验室大模型中心负责人陈恺博士,为师生带来了一场题为《书生科学多模态大模型Intern-S1及关键技术分享》的深度分享。
陈恺博士是清华大学自动化系的校友,上海市青年领军科学家,长期致力于人工智能领域的前沿研究。他在国际顶级会议和期刊上发表论文60余篇,谷歌学术引用超过2.5万次,曾获上海市东方英才计划领军项目、上海市青年学术带头人等荣誉。他是开源视觉框架OpenMMLab的主要负责人,对国际开源社区作出过重要贡献。在上海AI Lab,他主导研发了“书生”大模型系列,承担核心技术攻关任务,并建立了广泛应用于科研机构和产业界的司南评测体系。
陈恺博士首先为我们介绍了书生大模型的整体布局和家族成员:
·整体布局
书生大模型体系自2021年底启动,逐步形成了覆盖语言、多模态、推理等多方向的完整布局。代表性成果包括语言模型“书生·浦语”、多模态模型“书生·万象”、推理模型“书生·思客”等,并在2025年发布了具有全球领先水平的科学多模态大模型Intern-S1。
·书生·浦语
轻量级语言模型,通过更高的数据思维密度提升效果,并首次实现“混合推理模式”,能够在不同任务中灵活切换推理方式。
·书生·万象
国内最具影响力的开源多模态模型系列之一,支持从1B到百B量级的全覆盖,性能在社区长期保持领先。最新的InternVL3.5展现了更强的多模态理解与推理能力。
·书生·思客
面向复杂推理任务,结合推理范式的研究成果,已融入整体体系,推动大模型的推理能力进一步提升。
·科学多模态大模型 Intern-S1
这是浦江实验室在世界人工智能大会上发布的重点成果。它融合了此前语言、多模态和推理方向的积累,强化了科学领域的能力。Intern-S1被定位为“全能高手中的科学明星”,不仅在通用任务上保持领先,更在化学、材料、生命科学、地球科学等学科任务上远超同类开源模型。该模型提供了241B MOE版本和更便于开发者使用的8B Mini版本。
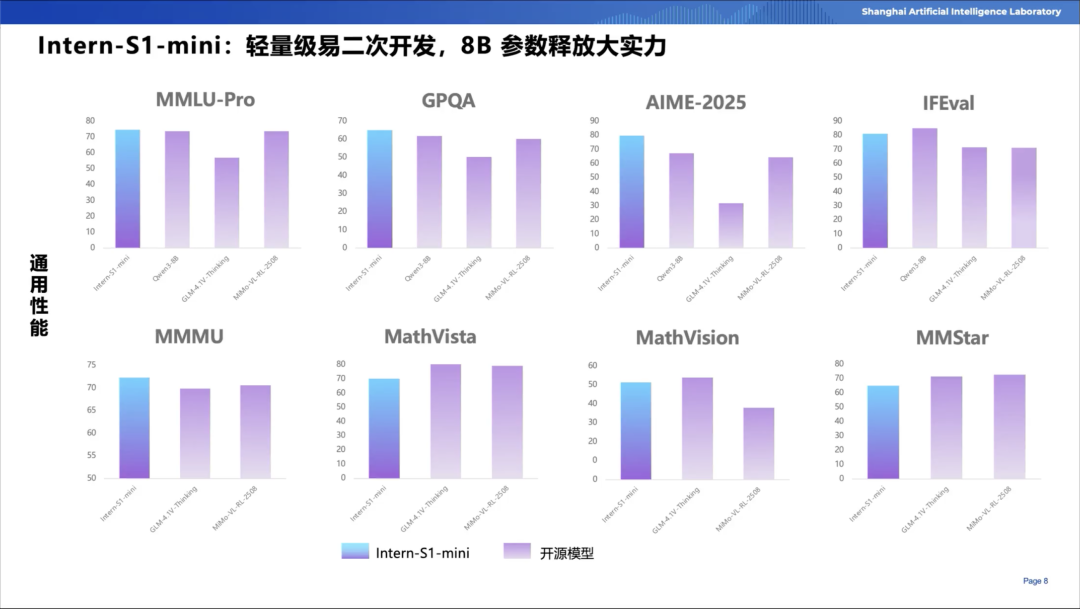
陈恺博士还向我们展示了Intern-S1在通用与科学任务中的双重领先地位:
·通用性能
在MMLU-Pro、GPQA、MMMU等文本与多模态基准测试上,Intern-S1的综合能力处于开源模型第一梯队,接近国际最先进的闭源模型水平。
·科学性能
在科学任务上大幅领先现有模型,特别是在跨学科问题处理方面展现了卓越表现,突出其“科学特长”。
·Mini版本
Intern-S1 Mini作为轻量化模型,兼顾开发便利性与科学能力提升,较同量级模型拥有明显优势。
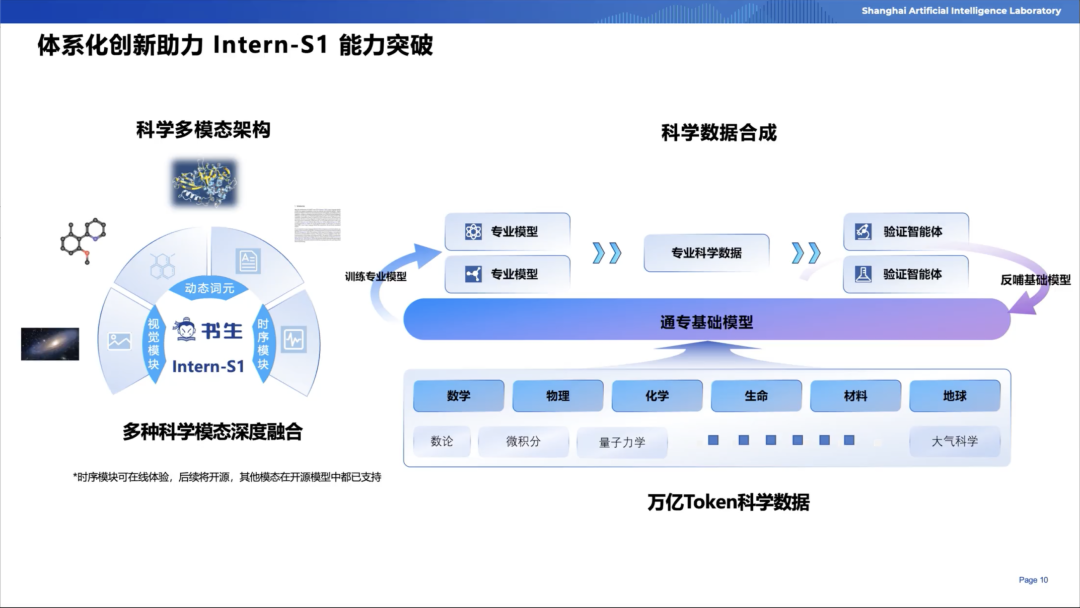
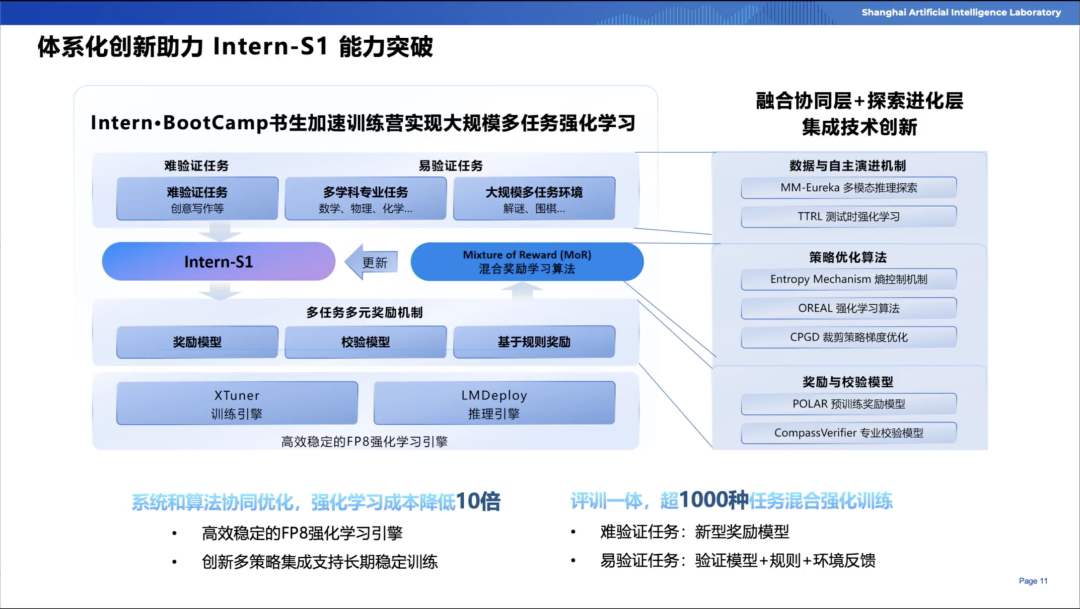
陈恺博士将Intern-S1系列中的技术创新分为以下三类:
·科学多模态架构
·科学数据合成
·多任务强化学习(Intern·BootCamp训练营)
使用Mixture of Reward (MoR)机制,融合Reward Model、基于规则的奖励等多种方式,实现多任务多模态的联合训练。
支持超过1000种交互环境任务,涵盖数学、推理、棋类、逻辑谜题等场景。
实现了高效稳定的FP8混合精度训练,首次将其稳定应用于强化学习环节,降低训练成本并保持收敛稳定性。
Intern-S1在各种场景中展现出了实际应用价值:
·数学能力
Intern-S1衍生版本在IMO 2025真题验证中,表现出优秀水平。与传统语言模型相比,具备更强的解题推理与公式处理能力。
·围棋

·文档解析
在原有MinerU2.0系统基础上升级,能够解析化学分子式、数学公式等科学元素,超越传统OCR的局限。
·生活中的科学
具备科学知识与视觉理解结合的复杂推理能力,能够应对“黑洞识别”等高难度任务。
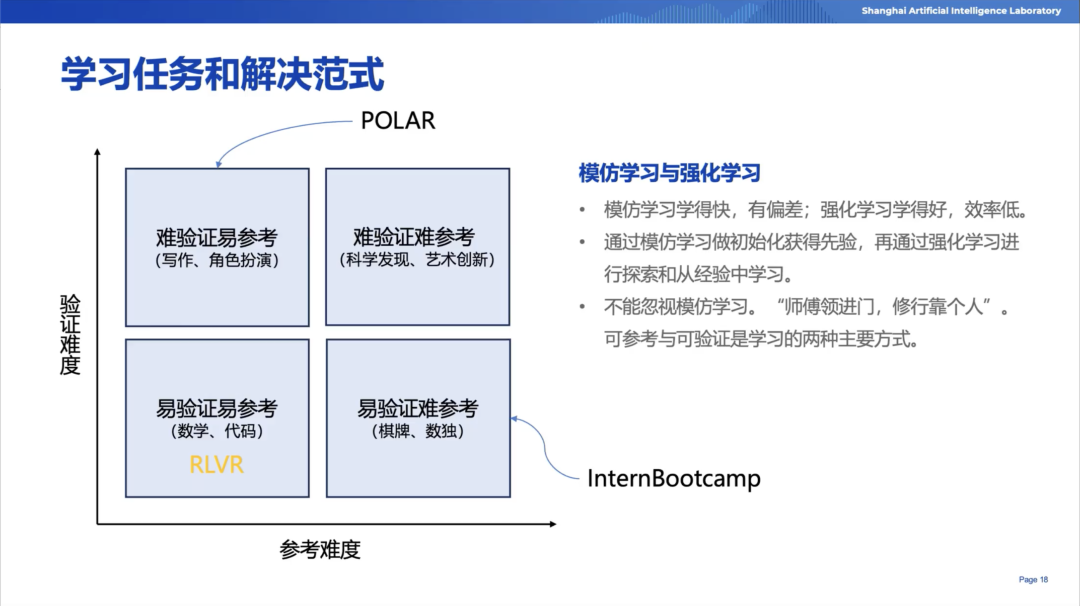
陈恺博士重点分析了团队对于强化学习任务的理解,提出了四象限区分的方法:
·四象限划分
1.易验证+易参考(数学、代码)
2.难验证+易参考(写作、角色扮演)
3.易验证+难参考(围棋、数独)
4.难验证+难参考(科学发现、艺术创新)
·研究思路
先聚焦前三类任务,通过模仿学习与强化学习结合提升模型效果。
·新的Reward建模范式(Polar框架)
传统Reward Model依赖偏好数据,受标注主观性和时代语境影响大,难以规模化。Polar提出基于对比学习的建模方法:判断两个输出是否来自同一分布,将Reward Model视作策略判别器。在预训练阶段,利用海量模型轨迹样本进行对比学习,微调阶段再引入参考答案。结果表明,即便在小规模模型上,该方法也能显著超越传统Reward Model,并在下游任务中取得更好表现。
陈恺博士的报告深入阐述了“书生”大模型系列,尤其是科学多模态大模型Intern-S1的研发思路与技术创新。他强调,科学任务对大模型提出了更高的架构与数据需求,必须通过动态Tokenizer、多模态架构、科学数据合成和强化学习新范式等多重突破才能实现。在应用层面,S1已在数学竞赛、围棋教学、科学文档解析等场景展现出实际价值,证明其科学能力的领先性。此次分享不仅展示了Intern-S1在通用与科学任务上的双重优势,也揭示了未来大模型发展的方向:通专融合、系统优化与多任务协同。






