3月5日下午,第42期AIR学术沙龙如期举行。本期活动荣幸邀请到了字节跳动李航博士,为我们作题为
《
推进人工智能新前沿》的报告。本次活动由中国工程院院士、清华大学智能产业研究院(AIR)院长张亚勤主持。

Hang Li is the Head of Research at ByteDance Technology. He is an ACM Fellow, ACL Fellow, and IEEE Fellow. He graduated from Kyoto University and received his Ph.D. from the University of Tokyo. Prior to ByteDance, he worked at NEC Research, Microsoft Research Asia, and Huawei Noah's Ark Lab. His areas of research include natural language processing, information retrieval, machine learning, and data mining.
李航博士分享了2024年在AI领域的诸多研究进展,涵盖基础场景研究、多个重点方向的探索,以及在产品中的应用实践。
字节跳动的AI研究定位聚焦于AI基础场景,研究领域广泛,涉及机器人、负责任AI、AI大模型和agent等基础技术。在全球范围内,字节跳动组建了多个研发团队,分布于北京、上海等地,并且积极与像清华大学智能产业研究院这样的顶级学术团体展开合作,共同推动AI技术的进步。
李航博士认为,根据技术特点和应用场景,AI的研究主要分为四个大方向,分别是AI on Computers,AI for Arts,AI for Science和AI in Physical World。前两个更贴近目前的产品,后两个是未来的探索方向。
Protein Modeling and Design
蛋白质的建模和设计是AI for science领域的研究重点,AI蛋白质结构预测模型AlphaFold2赢得了1/2的诺贝尔化学奖。字节跳动在这方面开展了深入探索。一方面,团队致力于蛋白质动态结构预测,当前的蛋白质研究多为静态结构预测,即Folding,而实际蛋白质是动态的,其动态3D结构在蛋白质相互作用中意义重大,因此动态结构预测成为研究关键方向。另一方面,团队还在进行蛋白质Co-design研究,即同时设计结构和序列,以实现特定功能。
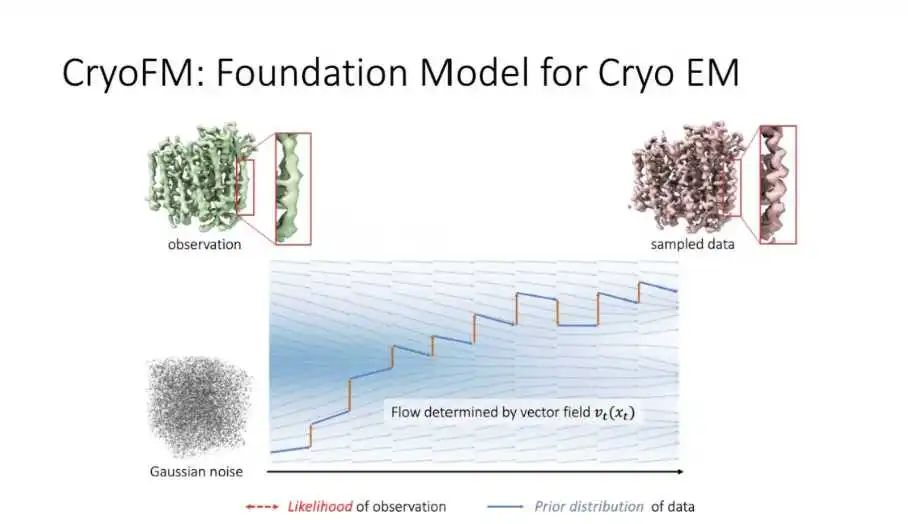
CryoFM:Foundation Model for CryoEM
CryoFM是字节跳动研发的冷冻电镜基础模型。冷冻电镜是用于窥探蛋白质动态结构的电子显微技术,能获取蛋白质的2D图像。CryoFM能用于任何冷冻电镜数据处理的任务,将大量2D图像还原为3D动态电影,生成蛋白质3D结构。该模型核心方法是以3D蛋白质动态结构数据为训练数据,使用flow matching技术学习高斯噪声到具体 3D动态结构数据的过程,建模先验分布。对给定的任意冷冻电镜观测数据,通过计算似然函数得到后验分布,以此处理下游任务。对于冷冻电镜数据的各类下游任务,CryoFM是目前最优的方法。
DPLM-2: Diffusion Protein Language Model
同时,团队还开发了DPLM-2(Diffusion Protein Language Model),用于蛋白质Co-design,即同时建模序列和结构。DPLM-2首先离散化蛋白质3D结构,和蛋白质氨基酸序列构成对。接着使用Transformer模型建模离散扩散过程,学习任意从序列到结构,从结构到序列,从部分结构和序列复原完全结构和序列的建模,从而实现各种蛋白质设计任务,例如给定预期功能,同时生成蛋白质的结构和序列;或者给定序列生成蛋白质3D结构。DPLM使用650M大小的模型就取得超过1.4B大模型(ESM-3)的效果。
GR2: VLA Model for Robot Manipulation
机器人领域也是字节跳动的研究重点。李航博士预测未来三年,第一代实用人形机器人有望落地,完成简单重复性的工作。目前机器人的行走等简单运动控制技术逐渐成熟,未来核心技术主要聚焦于vision language action model(视觉语言动作模型),使机器人灵活的完成复杂操作任务,达到机器人的AGI(即具备基本的操作能力)。Google发布的RT-2模型是最早的vision language action model,该模型在传统视觉语言模型基础上增加了动作预测功能。
李航博士的团队在学界首次提出GR-2模型,关注点不是未来一个时刻的动作,而是未来几个时刻的动作序列。GR-2首先使用语言和视觉的数据做预训练,以此为基础加上机器人动作序列的轨迹数据和视觉变化做微调,从而对机器人进行行为规划和控制。GR-2对多种任务具有强泛化性,到达90%的准确率。目前核心挑战在于需要采集大量的action数据进行scaling up规模化。
Agent智能体是以大模型为基础,具有记忆功能,并且能够使用各种不同工具,更加智能化。字节跳动团队开发了Agile,学术界首个端到端Agent训练的强化学习框架。具有双层结构,以LLM为核心构建记忆模块和工具模块,用强化学习训练LLM的思维能力,使其生成所需要的特殊命令和动作,让agent具备类似人类的思维结构,能够使用工具、拥有记忆并与人交互。
基于Agile端到端的强化学习训练框架,团队开发了论文搜索Agent,PaSa(PAper Search Agent)。PaSa具有两个Agent,分别是Crawler和Selector。Crawler用于重写查询,接着使用重写的查询去搜索论文,不断的找到所有的相关论文。Selector用于比较查询到的论文是否和原始查询论文相关,最后将相关结果返回。PaSa 的论文搜索准确度远远高于传统搜索引擎Google Scholar以及其他大语言模型,包括GPT-4o和GPT-o1。
CLASI: Simultaneous Speech Translation System
同传翻译是具有挑战的项目,传统的同传翻译是级联系统,先语音识别后翻译,存在语音识别错误和环境干扰大时翻译效果差,以及翻译时间节点难以控制,专业性翻译需要专业材料准备等问题。字节跳动团队将大模型和agent技术结合起来,搭建端到端的语音文本翻译模型CLASI,能有效判断需要翻译的内容和翻译的时间节点,应对环境和噪音的干扰,并且对缺失的内容进行有意义的补全,大幅提升翻译效果。目前,该技术已在字节跳动内部广泛应用,翻译水平接近人类同声传译,未来还将应用于豆包产品。
Pixel Dance: Video Generation
在视频生成领域,字节跳动开发的Pixel Dance系统取得了显著进展。该系统旨在用语言控制视频生成内容,包括人物表情、动作、物体交互和摄像头运动等。尽管在生成高质量视频方面面临真实性、一致性和遵循物理规律等挑战,但Pixel Dance在一些功能上已处于业界领先,如实现一句话生成多帧视频、复杂多物体运动生成等,目前已在字节跳动的即梦产品上线。
字节跳动在AI领域的研究成果丰硕,从基础科学研究到应用技术开发,多方向的探索与创新不仅推动了AI技术的进步,还为未来产品的升级和新应用场景的拓展奠定了坚实基础,在AI发展的浪潮中展现出强大的研发实力和创新活力。





