2月11日上午,第52期由AIR DISCOVER实验室主办的AIR青年科学家论坛如期举行。本次活动有幸邀请到香港科技大学助理教授(拟入职)/蚂蚁灵波的徐英豪博士,为AIR的老师和同学们做了题为《Video World Modeling for Robot Control》的精彩报告。
徐英豪,目前在蚂蚁灵波科技担任世界模型和具身智能研究负责人。在此之前,他曾于斯坦福大学计算成像实验室担任博士后研究员,导师为 Gordon Wetzstein 教授。博士阶段就读于香港中文大学多媒体实验室(MMLab),师从周博磊教授与林达华教授。本科毕业于浙江大学信息工程系,并于大三暑期作为访问学生接受过苏昊老师的指导。他在计算机视觉顶会(CVPR、ICCV、ECCV),图形学顶会(SIGGRAPH/SIGGRAPH ASIA)和机器学习顶会(ICLR、NeurIPS、ICML)等都多篇论文发表,其中十几篇文章获得Oral/Spotlight presentation,其中一篇被选为CVPR 2021 best paper candidate。在本科与博士期间,他曾先后在微软亚洲研究院、字节跳动研究院、蚂蚁研究院,Snap Research 和 Adobe Research 进行研究实习,积累了丰富的工业界研究经验。曾荣获 2024 年世界人工智能大会(WAIC)云帆奖,并于 2022 年获得 Snap Fellowship 提名。
报告分四个板块展开,分别从四个工作:Lingbot-Depth,Lingbot-VLA, Lingbot-World和Lingbot-VA逐步讲解复杂人类世界中的world modeling问题。
机器人和人类一样,必须理解物理世界才能在其中行动。人类智能依赖于一个紧密的“感知–模拟–行动”闭环:我们感知环境,在脑海中模拟其未来的演化,并据此执行动作。本报告探讨如何通过视频世界模型在机器人系统中实现这一范式。
徐英豪博士首先介绍感知方面的进展,重点讨论深度估计作为物理场景理解的基础,并以LingBot-Depth 为例进行说明,同时介绍一种由深度引导的 LingBot-VLA,它利用几何线索来提升视觉-语言-动作之间的对齐效果。随后,他将介绍视频世界建模作为一种模拟机制,使机器人能够捕捉环境动态,并从视觉观测中想象合理的近期未来状态,这一点以 LingBot-World 为代表。
在此基础上,报告的核心将聚焦于用于机器人控制的视频-动作建模,通过 LingBot-VA 展示,该方法将视频预测与动作推断统一起来,实现闭环的机器人操作控制。最后,徐博士展望了视频世界模型如何作为通用机器人智能的可扩展基础,使机器人能够在开放的物理环境中进行稳健的推理、规划与行动。
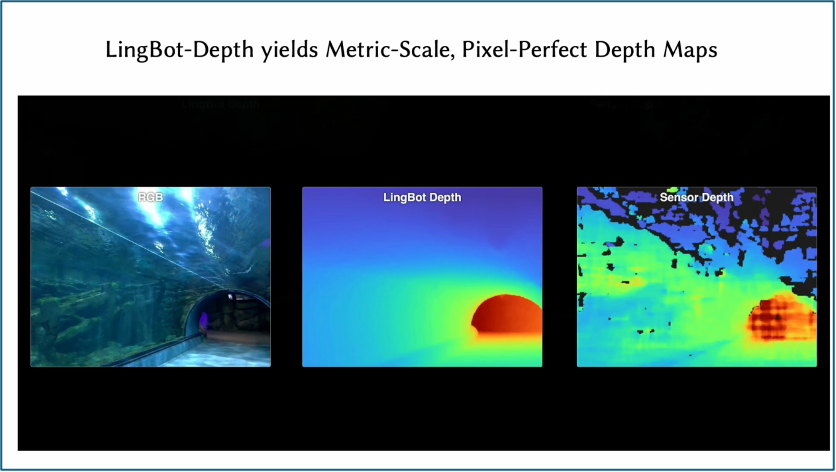
徐博士指出如今RGBD相机被广泛应用在Robot perception中用于采集数据(例如DROID Robot Platform),但是其中的Sensor depth perception非常不稳定,体现在1) Glossy surface; 2) Transparent objects; 3) Non-texture regions等等几个问题。

为此,徐英豪博士提出将sensor depth视为对原始depth进行mask modeling的思路,他认为这本质上与MAE训练类似,因为ZED depth本身就包含不连续区域,类似于加了mask的gt depth。他建议利用大规模MAE的方法来学习general depth,进而完成depth补全任务。

另外,徐博士还强调了数据对模型性能的关键作用,他指出当前研究趋势已从结构优化转向数据驱动的性能证明。他提到通过自建数据pipeline和仿真技术来弥补真实数据不足,例如通过上图中的Scalable Data Curation Pipeline来为模型训练提供重要的复杂场景仿真数据。
下图展示了Lingbot-Depth在海底观赏通道场景下的测试结果,对于透明、反光等物体,Lingbot-Depth都能输出高质量深度图,显著优于Sensor Depth。
Lingbot-VLA被认为是国内首个系统化进行了Pretraining的VLA项目,解决了在工程实施中遇到的诸多挑战。

值得注意的是,徐英豪博士团队于上海交大李永露老师合作开发了GM100评测体系(下图中的实验Benchmark),他强调真机测试比仿真更可信。因为真机部署存在实际误差。他提到李永露老师曾设计过RobotOlympics评测协议,当前机器人策略领域仍然缺乏可靠的评估标准。
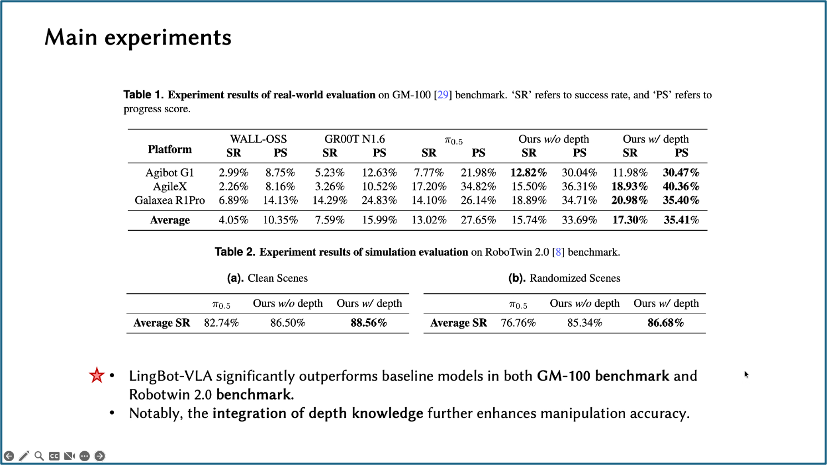
在Lingbot-VLA的实验讲解中,徐博士强调了对模型进行全面评估的重要性,他提到当前实验规模庞大且资源消耗惊人——目前约已完成2万多组实验,涉及高昂的金钱和时间成本。他特别提到深度信息(depth)的加入显著提升了模型性能,但同时也暴露出任务难度极高,整体成功率仅17%。
生成式视频模型的关键突破在于数据规模和质量,徐博士指出从10秒到1分钟的视频生成长度跃迁是行业重要里程碑。他以Sora和Genie3为例,说明数据驱动的平民化路径正在重塑行业认知。他提到Google内部对Genie3的成功也感到意外,因为前两代反响平平且资源投入有限。他认为Genie3的成功在于展示了高保真仿真和复杂动态交互的未来潜力,这远超之前简单场景的预期。

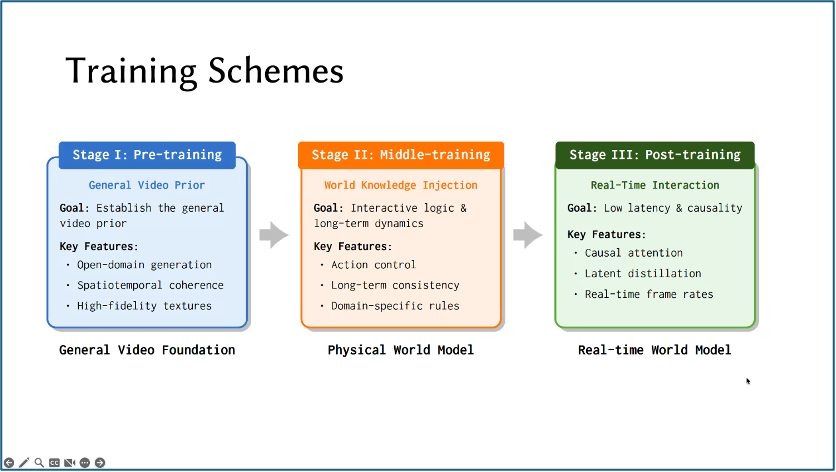
Lingbot-World包含了视频生成模型训练的几个关键阶段:第一阶段聚焦开放域泛化和纹理逼真度,徐英豪博士特别提到直接生成一分钟视频的self-forcing方法本质存在缺陷,因此才在Wan等基础模型上再次注入General Video Prior;第二阶段重点是通过middle training注入world knowledge和long-term dynamics,尤其是不同物理场景下交互逻辑的差异性。他提到目前的Infra框架已支持长视频训练,从技术路径来看,团队正在尝试突破现有14B模型在复杂运动处理和文本联想方面的局限性。最后是Post-training,实现最终的用户级部署。
上图中的测试展示了Lingbot-World强大的综合能力:高保真以及复杂纹理的场景生成、精确的视角以及位姿控制以及长时序生成。
针对现有基于VLM的VLA模型存在的“只会记忆、不懂逻辑”以及静态图像训练导致的动态因果缺失问题,徐博士指出了当前范式的核心痛点:单一稀疏动作信号难以同时承担场景感知、动态理解和动作推断的三重重任 。
为此,团队提出了"Video-Action Policy"的创新思路。徐博士对利用世界模型生成下游数据再训练VLA的传统做法表示质疑,认为这如同“用教师模型迁就学生模型” 。Lingbot-VA转而采用自回归(Autoregressive)范式结合逆动力学模型(IDM),通过高频的“预测-执行”循环,有效解决了传统开环控制中状态与动作不匹配导致的系统崩溃问题 。
当前神经模拟领域正从物理基础模拟转向生成式神经网络模型,如今大多数world model已具备优秀的动态理解能力,他比较质疑用其生成下游数据再训练VLA模型的合理性,认为这相当于用教师模型去迁就学生模型。在Lingbot-VA工作中,团队采用了自回归生成video结合IDM来逆向提取Action模型的思路,即”Video-Action Policy”。
为什么要用Autoregressive范式?首先是传统视频模型的开环控制存在致命缺陷——状态与动作不匹配会导致系统崩溃,且无法实现实时纠错。徐英豪博士提到近期流行的一些世界模型方案,认为其开环设计本质上缺乏与现实交互的鲁棒性。其次是Memory的关键作用,缺少记忆会导致无法区分当前状态与历史状态。他认为自回归模型能有效解决闭环反应(close loop reactivity)和记忆问题,因其高频率的状态刷新和因果性,还能通过历史记录修正错误动作,所以综合下来自回归的模式是最符合要求的。
团队明确了hige-level思路之后,模型即框架的设计变得容易和顺畅。上图简要解释了Lingbot-VA的工作流程,通过预测下一帧状态,结合IDM解算action,并将实际观察结果反馈到系统中形成闭环。他强调该模型巧妙融合了记忆性和反应性,通过高频率的预测-执行循环解决开放性问题。值得注意的是,这个集成模型可拆分为未来预测和实际解算两个独立模块使用(例如下图展示的测试结果),展现出架构设计的灵活性。整个方案通过状态迭代和错误修正机制实现持续优化。
在高难度的真机评测中,徐英豪博士提出了异步机制的重要性,即“边想边做“”边做边想“,他认为人类思维本身就是异步的,异步推理方案更接近自然行为模式。虽然未使用算子加速,但异步方案已能大幅度解决问题。硬件方案固然是可行的,但是团队更倾向于算法研究型方向。在下图的真机测试中,机械臂完成了高精度的双臂操作任务,成功操作手工刀切开了快递盒。
分享会上进一步讨论了异步策略中预测未来action的挑战,提到训练了一个FDM模型来处理图像预测,但异步精度下降导致卡顿问题。他提出调整预测窗口来缓解精度损失,但可能仍非完美解决方案。另外,徐英豪认为模型评估是当前快速迭代的关键瓶颈,然而基于word model的自动评估器可能是解决方案。在数据收集、模型训练和评估三座大山中,评估环节的优化空间最大。
本次论坛聚焦于具身智能与世界模型的前沿交叉领域,徐英豪博士以《Video World Modeling for Robot Control》为题,系统解构了如何利用视频生成技术赋能机器人控制。报告围绕Lingbot系列的四大核心工作层层递进:从Lingbot-Depth切入,利用掩码建模思想解决了复杂场景下的深度感知缺失难题;进而介绍了国内首个系统化预训练的VLA项目Lingbot-VLA,验证了深度信息对操作精度的显著提升;随后展示了Lingbot-World在生成高保真、长时序物理世界视频方面的突破;最终落地于Lingbot-VA,通过自回归范式将视频生成与逆动力学模型结合,实现了具备“记忆”与“反应”能力的闭环控制策略。
此外,报告深入探讨了当前具身智能发展面临的关键挑战与未来路径。徐英豪博士特别强调了数据规模(Scale)在视频生成模型中的决定性作用,并指出传统的开环控制缺乏鲁棒性,而自回归模型(Autoregressive)凭借其因果推理和实时纠错能力,是实现高质量人机交互的最优解。针对真机部署中的异步推理延迟及评估难题,徐博士也分享了关于“边想边做”异步机制的工程实践,并提出了利用世界模型构建自动评估器的前瞻性构想,为解决数据收集、训练与评估的“三座大山”提供了极具价值的科研新思路。






