李鹏飞是AIR的博士生,据ICRA 2023大会官方资料统计,在本次大会上,他是ICRA 2023全球中稿论文最多的学生作者。本次学术工作坊,他将着重为大家介绍其中的一篇研究工作LODE: Locally Conditioned Eikonal Implicit Scene Completion from Sparse LiDAR。在这项研究中,课题组提出了一种新颖的Eikonal补全范式,展示了现有Eikonal方法的优缺点,并广泛验证了其方法,证明所提出的公式对于实现超参数的鲁棒性。接下来,他详细地介绍了该项工作。

场景补全指从对复杂3D场景的不完整感知中获得密集的场景表示,这一过程这有助于机器人在自动驾驶等场景中检测多尺度障碍物并分析物体的遮挡关系。
在最近一些工作中,研究人员利用隐式表征学习的方式进行连续的场景补全,并通过如Eikonal方程这样的物理约束来实现场景表征的构建,其中比较著名的方法如SIREN。具体来说,这种方式利用场景表面三维点的位置信息和法向信息作为边界条件,通过求解特定的Eikonal微分方程获取场景的符号距离函数,该函数表达了场景中每个点到最近表面的距离值。然而,这些现有的Eikonal补全方法只在少量密集点云数据上展示了结果,难以成功地应用于数以千计的稀疏LiDAR点云的大型开放场景。其原因主要有三方面。首先,表面点的稀疏性导致边界条件稀疏,同时放大了非表面采样点在优化过程中的负面影响。其次,稀疏表面点难以进行表面的法向量估计。最后,在两部分不精确边界条件下,求解微分方程将给出不符合预期的结果。
为了解决这一问题,课题组对Eikonal补全方法进行了拓展,提出了一种新的局部条件化的Eikonal范式。此外,课题组针对道路场景对该方法进行了算法实现,并在公开数据集SemanticKITTI和SemanticPOSS上取得了最优结果。

具体来说,课题组将待学习的符号距离函数转换为两阶段过程,首先将三维欧氏空间映射到高维形状嵌入空间,而后再将形状嵌入空间映射到符号距离空间。为实现上述过程,课题组利用多帧拼接后的密集点云作为拟合符号距离函数过程中的额外数据输入,利用其对场景准确密集的表达学习高维形状嵌入,以作为密集的微分方程边界条件。
基于重构的Eikonal方法,课题组针对道路场景进行了神经网络的设计。主要包括五个部分:判别式模型基于稀疏卷积神经网络从输入稀疏点云中提取形状先验信息;生成式模型预测场景符号距离函数值;可导三线性插值弥补形状嵌入空间的不连续性,并连接两部分网络;位置编码模块将三维坐标映射为高维特征,帮助提取场景高维细节;两种可选的语义拓展提供了进行语义场景补全的方式建议,体现了框架的灵活可拓展性。

课题组在公开数据集SemanticKITTI和SemanticPOSS上对比了课题组的方法和现有的Eikonal方法。由于现有的方法针对密集点云进行设计,在面临稀疏激光雷达点云时,效果普遍较差,具体反映在重建结果的IoU指标上。而课题组的方法由于通过数据驱动的方式学习了场景的形状嵌入信息,能够借助密集边界条件学得更好的场景符号距离场。
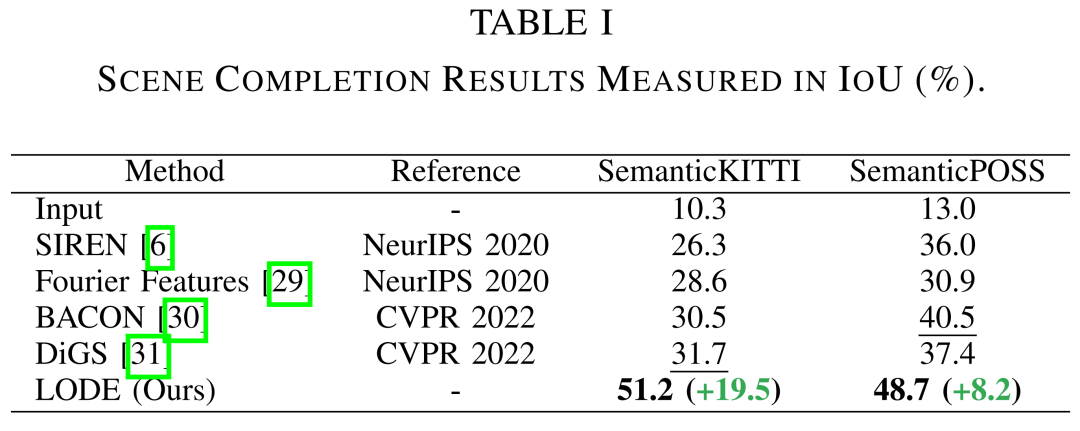
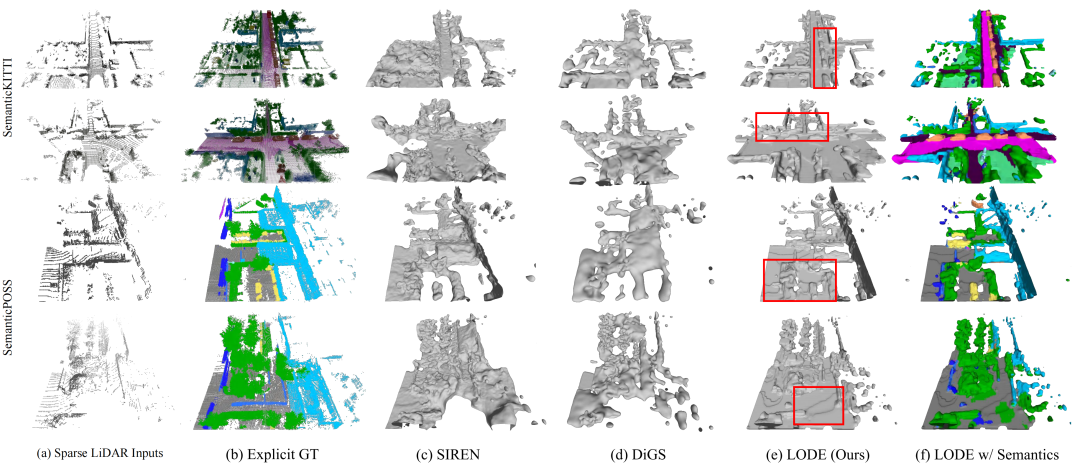
下图展示了课题组的算法与现有算法的对比效果。如红框标注部分所示,现有方法无法基于稀疏或被遮挡的点云进行场景重建,结果较为混乱,而课题组的方法能够较好地对场景进行表征,同时语义拓展给出了更易于分辨的场景类别信息。
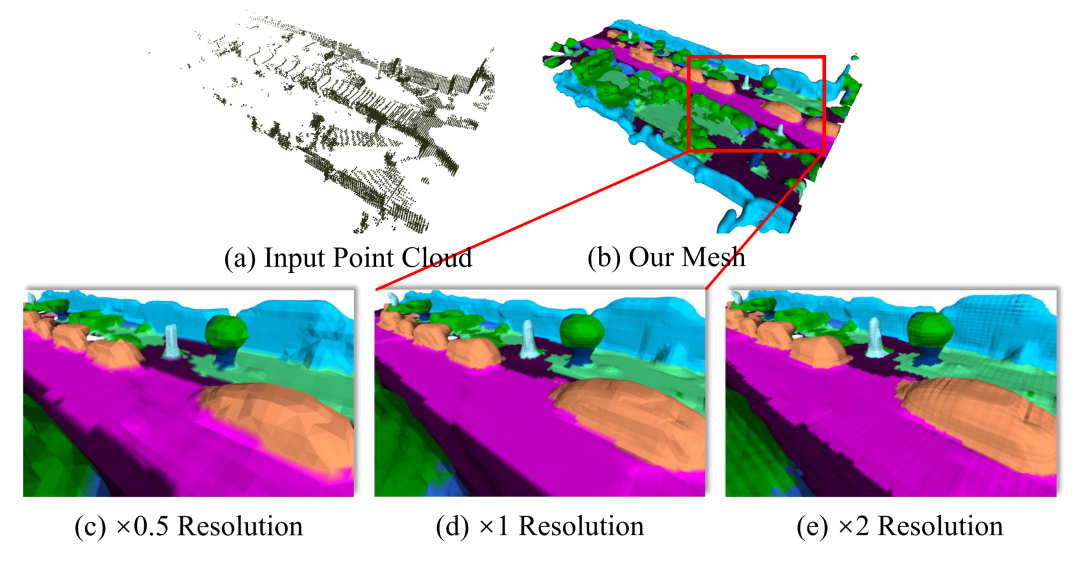
此外,由于对场景进行了基于神经网络的隐式表达,算法能够对场景中任意坐标点的符号距离函数值进行索引,从而支持在任意分辨率下对场景占据情况进行解析,有助于自动驾驶车辆在各个尺度下判断道路情况,进而高效实现避障等操作。
关注AIR公众号并回
复“AIR学术工作坊第4期”






