AIR实习生郑宇鹏所在课题组在ICRA 2023上发表了题为首个联合暗光增强和深度估计的自监督方法STEPS的论文,在该项研究中,课题组提出了一种联合学习夜间图像增强和深度估计的方法,使用一种新提出的不确定像素掩蔽策略将两个自监督任务紧密联系在一起。接下来,郑宇鹏详细地介绍了该项工作。

近年来,基于图像的自监督深度估计方法不仅所需的硬件成本低,而且不需要真值的标注,因此受到了广泛的关注。该类方法本质上依赖于相邻帧光度一致性的假设,通过合成图和目标图的光度误差进行模型的训练。
然而在夜间环境下,图像中包含了大量的欠曝和过曝区域,它们在相邻帧之间有较明显的差异,同时掩盖了对应区域的有效信息,如图1(a)的第一行所示。课题组在nuScenes数据集的测试集上评测了基线方法RNW预测的深度值和真值的均方根误差值(RMSE),同时课题组人工挑选了其中100多个过曝和欠曝的场景,做了如图1(b)所示的统计结果。可以看出,在这两种特殊场景下,RNW的表现要低于平均水平,可视化效果如图1(a)的第二行所示
(a)第一行,nuScenes数据集中过曝和欠曝的场景;第二行,RNW预测的深度;第三行,STEPS预测的深度图。(b)过曝(Overexposed),欠曝(Underexposed)和测试集平均(Avg)的RMSE
针对欠曝的区域,前人提出了先进行图像增强再做深度估计的方法。虽然他们提出了各种有监督的夜间图像增强方法,但在具有挑战性的驾驶场景中的泛化性能并不令人满意,而且需要一定量的人工标注。针对过曝区域对深度估计的影响的研究还较少。为此,课题组提出了STEPS,第一个自监督联合学习夜间图像增强和深度估计的方法,同时不使用任何ground truth。此外,课题组提出了不确定像素掩膜策略。它基于图像增强的中间产物来过滤影响深度估计的图像区域,从而将两个自监督任务紧密地结合在一起。对比图1(a)的第二行和第三行可以明显发现,受益于课题组的框架和策略,STEPS在欠曝和过曝区域的表现要优于基线方法。最后,课题组还提出了CARLA-EPE,一个基于CARLA仿真器的增强到现实风格的夜间数据集。它具有密集的深度图的标注,且更接近现实的图像风格,为深度估计任务带来更多的可能性。
论文:https://arxiv.org/abs/2302.01334
代码:https://github.com/ucaszyp/STEPS
如前所述,夜间图像增强可以提高输入图像的质量,以帮助进行深度估计。但是有监督的夜间图像增强在本质上受到数据集自身分布的限制。因此,课题组提出了一个以自监督的方式联合训练深度估计和图像增强的框架,如图2所示。它包含自监督图像增强模块(SIE),夜间自监督深度估计模块,由目标帧经过SIE生成的光照图将两个模块联系在一起。输入的原始图像首先经过SIE得到增强图像,随后对增强图像做自监督深度估计。联合训练的损失函数是每一模块的加权求和。
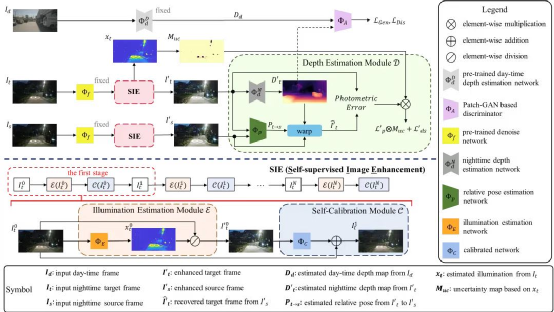
如文章开头所描述,夜间图像通常包含欠曝和过曝的区域,这些区域会丢失重要的细节信息,导致估计的深度值不准确。而且,过曝区域往往与汽车的运动(如车灯)相关联,这也违反了自监督深度估计中的光照一致性假设。因此,课题组需要设计某种机制来滤除这些区域去训练的影响。经研究发现,SIE可以预测一个光照图 ,以确定每个像素的颜色的增强比。如图3所示,欠曝区域的比值较大,过曝区域的比值较小。如果课题组用这个来衡量每个像素在光度损失中的重要性,则可以最大可能减小这两个区域对训练的影响。在实现时,课题组给不确定区域每个像素点一个置信度,希望它们能参与到训练中,而非直接强硬地全部遮盖掉。
图3 不确定mask的原理
(a)光照图 。(b) mask函数,该函数可以屏蔽过曝和弱曝区域。(C) 不确定mask的可视化
课题组在nuScence数据集和RobotCar数据集上和其他方法做了比较。此外,针对真实数据集成本高、深度图稀疏以及仿真器数据域与现实数据域差异大的痛点,课题组提出了增强到现实风格的仿真数据集CARLA-EPE。
nuScenes-Night:nuScenes是一个大规模的自动驾驶数据集。它包含多种天气环境下复杂的道路场景,十分具有挑战性。
RobotCar-Night:RobotCar数据来源于RobotCar团队一年的时间内在各种天气下频繁地穿越牛津市中心的同一条路线时的驾驶记录,包括车辆上的6个摄像头数据以及激光雷达、GPS和INS数据。
CARLA-EPE:上述两个数据集的真实深度均来自激光雷达,然而,激光雷达数据的采集是昂贵的,并且只能提供稀疏的深度图。为此,课题组将目光放在了仿真数据上。RGB图像和相应的密集深度图可以很容易地在仿真器(例如CARLA)中收集,但仿真图像和真实图像之间的分布差异极大地影响了训练模型在真实场景中的应用。因此,课题组提出了一个基于CARLA和增强图片真实感的网络EPE的夜间深度估计数据集CARLA-EPE,它可以提供密集的深度真值和迁移到真实风格的图像,如图4所示。
图4 EPE增强后的图像(CRALA-EPE)与增强前(CRALA)的对比
如表1所示,课题组在nuScenes数据集和RobotCar数据集上均达到了SOTA,在准确率和误差上均有显著的提升。在更具挑战性的nuScenes数据集上,课题组的a1相较于baseline提升了16.2%,abs_rel相较于baseline降低了10.4%。
表1 nuScenes数据集和Oxford数据集的定量结果
如图5所示,蓝色方框展示了基线方法受到过曝的影响,预测了错误的深度。红色方框还表明基线方法在欠曝区域错误地估计物体深度。由于我们的方法提出了新的框架和自适应掩膜的策略,因此可以使模型在这两种区域中预测出更合理的深度
图5 可视化结果
关注AIR公众号并回
复“AIR学术工作坊第4期”






