AIR实习生田倍闻所在课题组在ICRA 2023上发表了题为以语言为锚点的无监督道路场景异常检测算法的论文,研究无监督条件下的异常检测方法,不依赖从封闭训练集中学到的权重作为逻辑生成锚点,而是使用从大量配对的视觉和语言数据中学到的语言锚点。接下来,田倍闻详细地介绍了该项工作。

道路异常检测任务对于提升自动驾驶的安全性至关重要,因为当前的道路场景理解算法通常以闭集,也即在固定有限的语义类别上进行训练,在场景中出现未知物体(异常)时难以进行准确的理解,错误、不可信的语义分割结果可能导致灾难性的决策行为并造成交通事故。这个问题难以通过增加训练数据的方式解决,因为在一方面道路场景放置异常物体存在安全风险,另一方面对异常物体进行准确像素级别的标注需要耗费大量资源。驾驶场景中物体呈现长尾分布,枚举全部物体进行数据采集和标注也是不现实的。
图1 闭集方式训练语义分割时在未知物体(异常)的区域产生不可信的结果
为此,本工作提出通过语言锚点,基于语义分割模型进行异常区域的理解与分割。由于语言锚点中包含了丰富的开放集语义信息,本方法在不额外使用分布外数据进行训练的约束下,比以往的同约束的无监督方法表现更好。进一步地,本工作深入探讨了这种新的范式,并确定了使用多组二进制分类能够获得更高的性能。另外,本工作探索发现,对语义标签的前top-1选择存在问题,而一种新的混合标准化策略对我们的解决方案带来了明显的改进。在同等条件的方法中,本方法在FS LostAndFound、LostAndFound和RoadAnomaly数据集上汇报了最高性能。
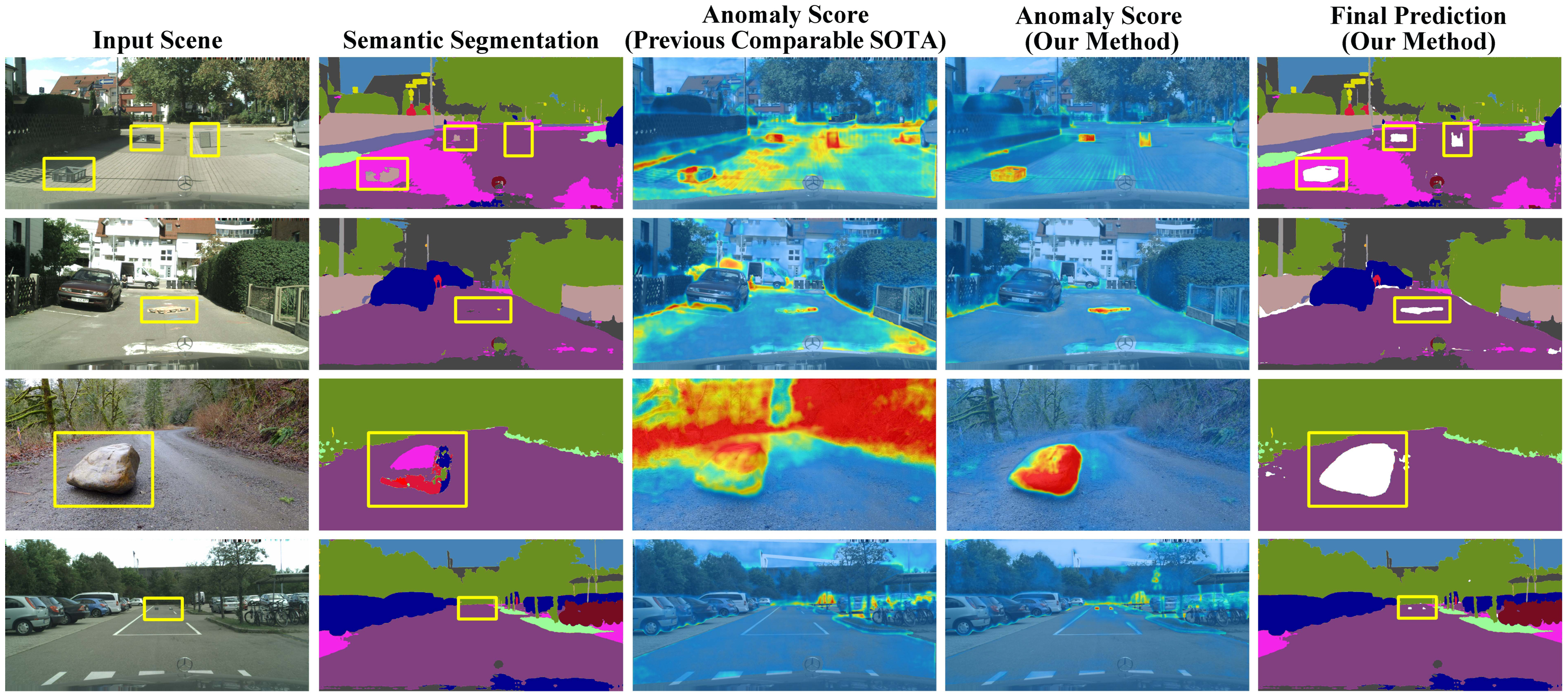
图2 闭集方式训练语义分割时在未知物体(异常)的区域产生不可信的结果
第一列:输入RGB图像,第二列:语义分割结果,第三列:前人工作输出的异常值,第四列:本文工作输出的异常值,第五列:本文工作的异常检测结果
目前的无监督异常检测算法仅从确定有限的训练集中学习,仅取得较低性能。这些方法的关键问题是缺乏开放领域的先验知识,而课题组认为可以通过视觉-语言预训练模型的先验知识(例如CLIP )来缓解这个问题。在本工作中,我们利用视觉-语言预训练模型的特征空间,将输入图像嵌入在这个空间中,并将已知类别的文本描述转化为语言嵌入并作为分类优化目标,如图3左侧所示。
图3 本工作算法流程框图
进一步地,采用具有否定词“others”的词嵌入作为否定语言锚点,并从逐像素的多类别分类转变成为多个二分类的组合,将多个二分类的logit作为多分类的logits以从成对的锚点嵌入中构建了一个更好的表征空间。该过程如图3中间部分所示。
得到logits后,课题组参考前人工作按照类别对logits进行归一化:
公式1

公式2
然而,该异常值计算方式对逐像素的分类(也即语义分割)准确性要求较高,如图4所示:

图4 不同的异常值计算方式差异
图4中(b), (c), (d), (e), (f)中的左右框均表示某像素。(b)表示两个像素的真实类别均为A,(a)表示两个像素分别被预测成为类A和类B。在这种情况下,(c)通过二进制分类得到的logits数值范围相似,但是观察经过上述归一化过程后得到的logits (展现在(d)中)计算得到的异常值(e)可发现,对相同标签的像素产生了差异较大的异常值。
因此课题组对公式2中的异常值计算方式提出改进,得到公式3:
公式3
与公式2中只选取logit最大的一类(即预测的分类)的logit作为异常值不同,公式3的计算方式综合考虑了不同类别的归一化logit,能够尽可能地避免错误的语义分割结果对异常检测性能的影响。
课题组在Fishyscapes LostAndFound,RoadAnomaly,LostAndFound三个数据集上进行了实验,并且和前人方法进行了比较。课题组汇报AUROC,AP与FPR95三个指标上的结果。
图5 实验结果
实验结果显示,课题组的方法在无监督异常检测的任务上取得了最佳的性能。图6和图7展示了部分开展的消融实验,证明了语言锚点和二分类组合的有效性。
表格中汇报二分类组合相比多分类的性能提升,可视化结果中第一列为输入图像,第二列为多分类时的异常值可视化,第三列为使用二分类组合的异常值可视化。
表格中汇报不同的方法使用语言锚点时相比常规闭集锚点的性能提升,可视化结果中第一列为输入图像,第二列为使用常规闭集锚点时的异常值可视化,第三列为使用语言锚点时的异常值可视化。
关注AIR公众号并回
复“AIR学术工作坊第4期”






