6月27日,由DISCOVER实验室主办的第三十二期AIR DISCOVER青年科学家论坛如期举行。本期讲座有幸邀请到上海科技大学信息学院助理教授、研究员、博导马月昕,为AIR的老师和同学们带来题为《Label-efficient Learning and Fine-grained Understanding for Large-scale Scenes》的精彩报告。

马月昕,博士毕业于香港大学,曾到法国国家信息与自动化研究所、美国北卡罗莱纳大学教堂山分校、百度研究院进行访问学习。主要研究方向为三维视觉、机器人,尤其是三维场景理解、多模态感知、自动驾驶、人机协作等。共发表相关领域国际知名会议及期刊论文60余篇,包括Science Robotics, TPAMI, CVPR, ICCV, ECCV, SIGGRAPH, AAAI等。曾获SemanticKITTI、NuScenes、Argoverse等多个自动驾驶挑战赛冠军和亚军。
本次报告主要分为三个部分:
Universal 3D Scene Understanding(通用3D场景理解),Fine-grained Understanding for Human-centric Scenes(以人为中心场景的精细理解)和Human-like Motion Generation(类人运动生成)。
在 Universal 3D Scene Understanding 部分,马博士首先系统介绍了3D视觉领域的基础传感器技术,涵盖摄像头、RGBD传感器及激光雷达等。接下来介绍了大模型在3D感知中的应用,指出了由于应用场景以及传感器的不同很难实现统一的特征提取。马博士认为在当前视觉领域的大模型框架尚未实现多任务处理的统一与真正的通用智能,进而强调了构建一个能够推动3D场景深入理解的基础模型的重要性。

针对3D视觉任务传感器模态多样性,模型需具强泛化能力。马博士及其团队通过迁移学习,聚焦多帧数据中的动态属性相似性,解决自动驾驶中不同激光雷达型号、密度及感知范围差异导致的性能下降问题。通过迁移学习方法,利用物体几何与运动属性共性解决域适应问题。显著提升UDA性能达20%-30%,展现强泛化能力。接下来马博士介绍了基于大模型如何解决这一问题,通过利用SAM将不同模态的特张拉入到同一特征空间中实现了较强的泛化能力。

在泛化性研究的进一步思考上,为了实现3d语义分割的zero-shot(零次学习),马博士及其团队基于SAM和CLIP提出了同时训练2d和3d场景理解的框架。实现了无标注3d点云的室内外场景理解。

基于以上研究再进一步,马博士提出了使用一个模型一套参数实现在不同数据集上达到sota效果的设想。基于这个设想,马博士及其团队通过多数据集多模态多任务的联合训练方法,实现了将3d感知统一在一个模型的目标。

在Fine-grained Understanding for Human-centric Scenes部分,报告首先聚焦了以人为中心的场景三维感知。马博士认为该领域的数据集应该注意场景的多样性以及任务的丰富性。通过引入基于行人和日常生活场景的两大benchmark,以此获得不同任务和标注的数据,从而深入探究以人为核心的场景。

在针对数据较少的问题,马博士及其团队探讨了如何将参数化模型与三维场景的背景数据相结合,实现不受限制的合成数据生成。这种方法不仅减轻了对真实数据的依赖,还显著提高了模型的性能。研究发现,利用这种方法生成的无限量合成数据的效果接近全监督效果,对于以人为主题的任务具有极高的应用价值。

在得到了优质数据的基础上,马博士介绍了团队在如何实现更细腻的感知研究。基于服务机器人平台,马博士提出了多模态结合的构想,来提高服务机器人的感知理解能力。同时,基于通用场景,马博士及其团队开展了细粒度的机器人视角下的motion capture,通过LiDAR,实现了自由场景下的motion capture。

最后在马博士的精彩分享中,他特别强调了正在进行的一项前沿工作——Human-like Motion Generation(类人运动生成)。这一工作旨在为人形机器人平台实现端到端的控制,直接通过视觉信息来生成机器人的控制信号,从而推动服务型机器人技术的革新。
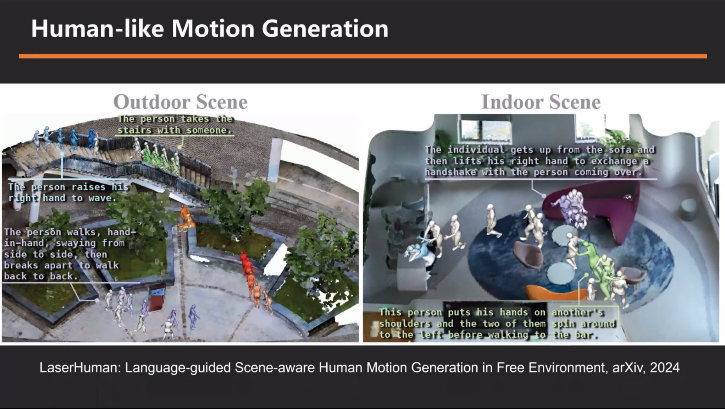
马博士指出,尽管在环境感知和人体建模方面已经取得了显著进展,但要真正实现机器人递水等复杂任务,还需要解决控制信号生成的问题。传统的研究范式往往将感知、预测和控制模块分开处理,但这种方式在应对复杂动态场景时显得力不从心。因此,马博士及其团队正致力于探索一种全新的端到端控制范式,希望通过视觉信息直接生成机器人的控制信号。
为了实现这一目标,马博士团队借鉴了自动驾驶领域端到端技术的发展经验,并结合人形机器人的特性进行了创新。他们提出,将语言指令与多帧点云信息作为输入,通过深度学习模型直接生成人形机器人各关节的旋转信息和三维位置信息,即长时序的控制信号。这一方法不仅简化了系统架构,还有望提高机器人在动态场景下的响应速度和交互能力。

尽管目前的工作仍处于初步探索阶段,但已展现出令人鼓舞的成果。马博士展示了一些测试场景,包括机器人在动态环境中与人打招呼、握手以及上下楼梯等复杂动作。






