7月2日上午,第39期AIR学术沙龙如期举行。本期活动荣幸第邀请到了匹兹堡大学电气与计算机工程系副教授高伟,为我们作题为On-Device AI with Full Runtime Adaptability的报告。本次活动由清华大学智能产业研究院(AIR)国强教授刘云新主持。


Wei Gao is currently an Associate Professor in the Department of Electrical and Computer Engineering, University of Pittsburgh. His research interests lie in the intersection between AI and computer systems, with a focus on the design and deployment of on-device AI models and algorithms on mobile, embedded and networked devices. He also has strong interests in applying the computationally efficient AI models into practical application domains to make societal impacts and benefit the human welfare. The integrated AI and sensing systems developed by his team have been applied to more than 400 patients at Children's Hospital of Pittsburgh and helped enormous families with low incomes during the COVID-19 pandemic. He has published more than 70 research papers at both top AI and system conference venues, including ICLR, ASPLOS, MobiCom, MobiSys, SenSys, etc, and received multiple best paper awards or nominations.
在本次报告中,高教授首先阐述了人工智能的时代下,在移动设备上本地部署 AI、并动态适应调整(runtime adaptability)的重要性与挑战;
随后向我们介绍了团队基于模型可解释性的分析,在不同的设备算力与模型复杂度场景下为实现这一目标所作的研究;
最后还以智慧医疗为例,介绍了团队在具体应用场景下的AI+感知系统搭建与数据集工作。

随着人工智能技术、尤其是最近以ChatGPT和Stable Diffusion等为代表的生成式 AI 的迅速发展,AI 正在从各方面影响着我们的日常生活,并越来越成为我们生活的一部分。为了能够在手机、智能手表等生活中距离我们最近的移动设备上使用 AI,目前的主流方案是将数据上传至云端进行处理。这样不仅造成额外的延迟与使用成本,也难以满足用户定制和隐私保护的需求。未来如果能够广泛地在这些设备本地部署AI 模型,不仅有利于实时地、低成本地支撑端侧 AI 应用,更有助于模型灵活地学习本地数据并适应环境变化。

然而,由于尺寸、成本和功耗等限制,这些移动设备上的硬件资源往往非常有限,难以匹配日益增长的模型复杂度,这为本地部署 AI 带来了巨大的挑战。因此,需要从高效 AI 算法、不同任务的适应性以及软硬件协同设计等方面入手,更好地利用已有设备,提高部署效率。
不过,目前以模型压缩为代表的高效 AI方法往往基于确定的优化策略,无法灵活地适应运行时数据特征。
高教授认为,真正实现模型的动态适应,需要根据输入数据灵活地选择或丢弃模型中的结构,并最小化这一转换开销。
为了做到这一点,需要基于模型可解释性的分析,使用可量化并且具有组合性的指标来评估模型中不同结构对模型输出的影响,并且较好地平衡模型计算开销与准确率。
基于这一思路,高教授团队面向不同的设备与模型类型开展了如下一系列工作。
ElasticTrainer: On-Device Training with Elastic Tensor Selection
ElasticTrainer主要面向嵌入式及可穿戴设备上中等大小(<1G)的模型训练,其目标是在给定训练时长(加速比)下最大化模型准确率。在具体方法上,ElasticTrainer 通过训练过程中某个权重更新与否对损失函数大小的影响来量化评估张量的重要性,并在学习率为小量的前提下(在端侧微调模型时往往能够满足)通过一阶泰勒展开确保其可加性。除此之外,基于已有的层级别时间开销模型(layer-level time model),ElasticTrainer将每个张量等效为子层(mini-layer),进而将整个计算图展开至张量级别建立时间模型,并通过动态规划算法求解。在树莓派上,ElasticTrainer能够在保持精度的前提下将训练耗时缩短至 50%,并可达最高3.2倍的加速和65% 的FLOPS 节省。

GreenTrainer: LLM Fine-Tuning with Adaptive Backpropagation
GreenTrainer主要面向智能手机和NVIDIA Jetson系列等算力更强的边缘设备上 LLM 的微调。已有的工作往往采用确定的微调策略,无法较好地平衡准确率与训练开销。而GreenTrainer基于前述思路,对LLM中不同模块训练的耗时进行测试与建模,并在重要性分析中采用提前终止策略,从而提升训练速度。在实验结果中,GreenTrainer可在同样的模型准确率下实现高达30% 的训练提速,并且对不同大小的模型具有泛化性。

mPnP-LLM: Runtime Modality Adaptation in Multimodal LLMs
mPnP-LLM主要面向具身智能等场景下对多种模态输入的动态适应。在实际应用中,由于环境的动态性和复杂性,不同模态的输入所能提供的信息量及其可靠性也会动态变化,甚至有些时候某些模态的输入会起反作用,这就使得对于输入模态的灵活适应和选择非常重要。为了减少编码器训练开销,已有工作的做法是保持输入编码器不变,并在每个模态的输入编码后增加投影模块(projection module)进行训练,同时微调解码器。为了尽可能降低解码器部分训练开销并保持准确率,同样需要对解码器中的LLM模块进行恰当的选择。mPnP-LLM 在训练中加入 trainable latent connection,来学习不同模态下编码器投影到解码器的连接关系,并实现高效的模态切换与适应。实验结果显示,mPnP-LLM能够实现3.7倍的FLOPs降低和30% 的内存减少,且仅需约 500 个数据样本。

AgileNN: Agile Offloading on Extremely Weak Devices
主要面向 MCU 等资源极度受限的设备上小模型(<100M)的推理。这些设备上的内存和存储(<1MB)往往无法支持完整的模型推理,需要部分卸载(Offload)到边缘服务器上处理,而这会带来很大的数据传输开销,并显著增加推理延时。事实上,这些模型的输入数据特征中往往只有很少一部分是重要的,而大部分重要性较低,并且更易被压缩。基于这一观察,AgileNN基于特征的重要性分析,有选择地在本地或远端处理不同特征,从而有效提高推理速度,和baseline相比实现2~2.5倍的端到端延时降低。

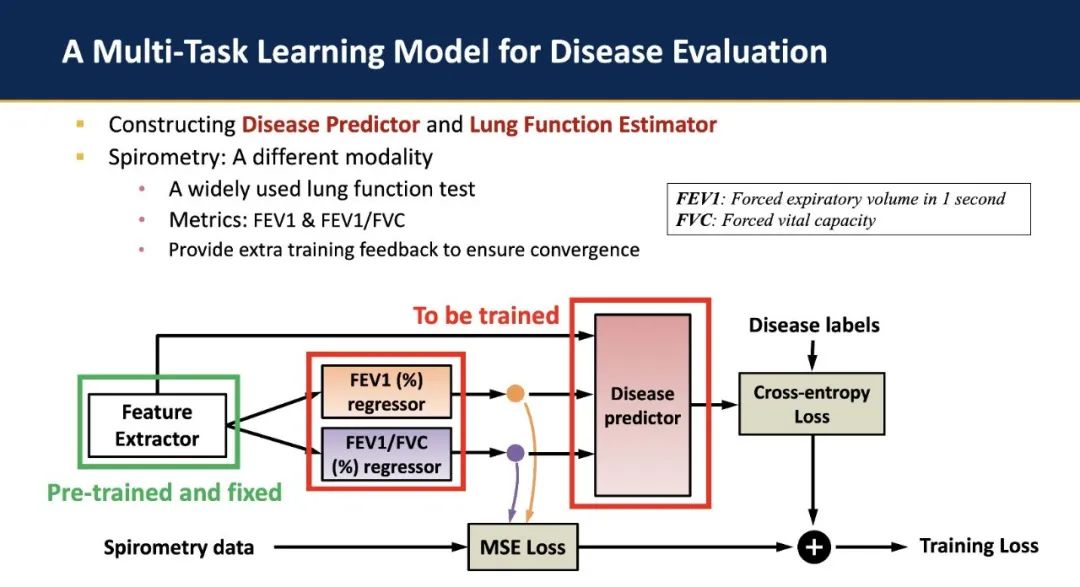
除了以上论文发表外,高教授团队也在智慧医疗的具体场景需求下,将前述的多模态感知与端侧 AI 部署技术进行应用,搭建了集成的AI 与感知系统,用于呼吸道疾病的诊断。为了解决实际应用中采集的数据高度模糊且异质(ambiguity and heterogeneity)的问题,除了模型推理阶段实际使用的声学信号外,该工作还引入了额外的肺功能测试结果用于辅助模型训练阶段的收敛。该工作与 Children’s Hospital of Pittsburgh 合作,采集了包含 382 个样本的数据集,并已公开于 Hugging Face (https://huggingface.co/datasets/ericyxy98/pulmonary-disease-airway-lung-function-dataset).