能够联合处理不同模态的信息,是人类区别于动物具有更高级智能的原因之一,这也是我们致力追求Integrative AI的初衷。
——黄学东
8月17日上午,第25期AIR学术沙龙如期在线举行。本期活动荣幸地邀请到了微软技术院士、微软Azure人工智能首席技术官黄学东教授为我们作题为《A Holistic Representation Toward Integrative AI》的报告。

本次活动由清华大学讲席教授、智能产业研究院(AIR)院长张亚勤院士主持,AIR官方视频号和b站同步直播,当日线上逾2000次观看。
Dr. Xuedong Huang is a Technical Fellow in the Cloud and AI group at Microsoft and the Chief Technology Officer for Azure AI.
Huang oversees the Azure Cognitive Services team and manages researchers and engineers around the world who are building AI-based services to power intelligent applications.
In 1993, Huang joined Microsoft to establish the company's speech technology group, where he led Microsoft’s spoken language efforts for over a decade. In addition to bringing speech recognition to the mass market, Huang led his team in achieving historical human parity milestones in speech recognition, machine translation, conversational question answering, machine reading comprehension and image captioning. Huang’s team provides AI-based Azure Vision, Speech, Language and Decision services that power popular world-wide applications from Microsoft like, Office 365, Dynamics, Xbox and Teams to numerous 3rd party services and applications.
Huang is a recognized executive and scientific leader from his contributions in the software and AI industry. He is an Institute of Electrical and Electronics (IEEE) and Association for Computer Machinery (ACM) Fellow. Huang was named Asian American Engineer of the Year (2011), Wired Magazine's 25 Geniuses Who Are Creating the Future of Business (2016), and AI World's Top 10 (2017). Huang holds over 100 patents and has published over 100 papers and two books.
Before Microsoft, Huang received his PhD in Electrical Engineering from University of Edinburgh and was on the faculty at Carnegie Mellon University. He is a recipient of the Allen Newell Award for Research Excellence.
基础模型(Foundation Models)的时代
基础模型是人工智能领域近几年来里程碑式的突破。基础模型首先利用海量的各种模态的数据,包括文本、图片、语音、结构化数据、3D 信号等进行预训练,预训练好的模型可以被应用到各式各样的下游任务上,如问答、信息抽取、物体识别等。相比于传统的处理单任务的模型,基础模型的部署速度更快、性能更好。
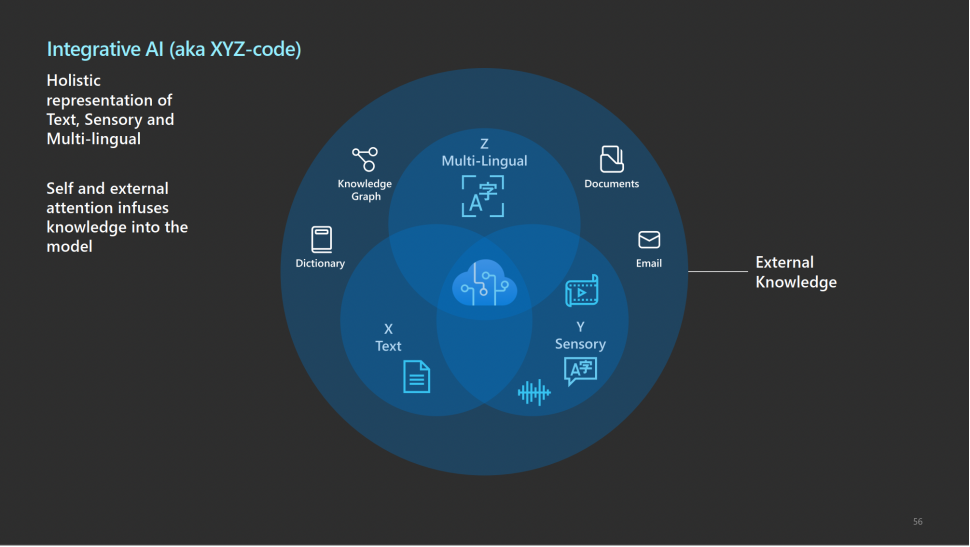
基于基础模型的Integrative AI是黄学东教授团队的追求目标和前进方向。他认为,能够对于不同模态的信息进行联合处理,是让人类区别于动物,具有更高级智能的原因。因此需要对于不同模态的任务,如图像、语音、语言的联合优化。此外,他还认为需要引入外部知识来对基础模型进行调整。多模态多任务联合优化、外部知识的引入是黄教授研究团队聚焦的两大重点。
接下来,黄学东教授将从语音、语言、视觉三个方面介绍Azure AI团队所取得的进展。
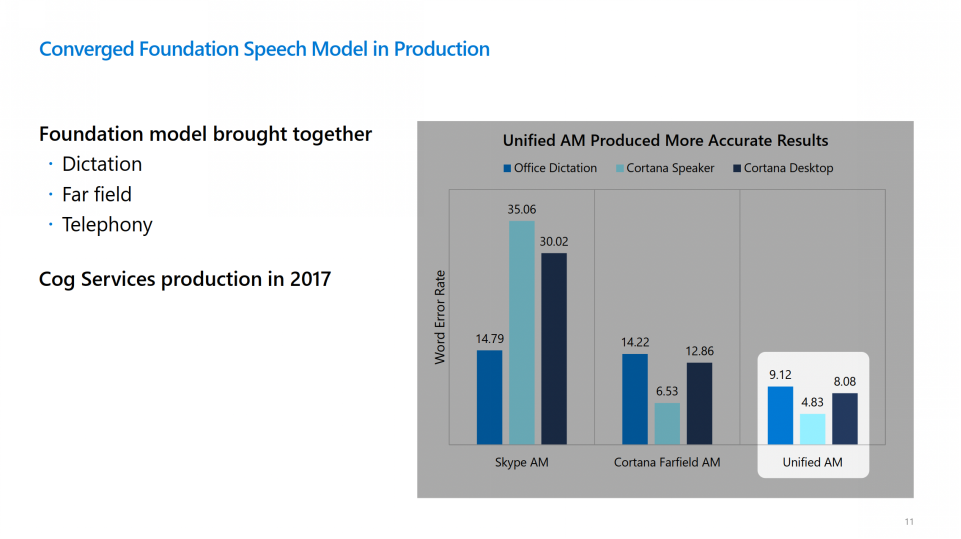
自2017年,微软就将基础模型投入到语音产品中使用。微软最初使用孤立的模型去完成不同的语音任务,例如一个模型去完成办公室听写任务、另一个独立的模型作为Cortana Speaker等。当时黄教授团队就提出使用一个统一的语音模型,来同时处理所有任务,这一创新不仅减少了大量的工程劳动,还提升了模型在各个任务上的性能(下图 Unified AM v.s. Skype AM),展现了使用统一基础模型、整合大量数据进行多任务训练的优越性。
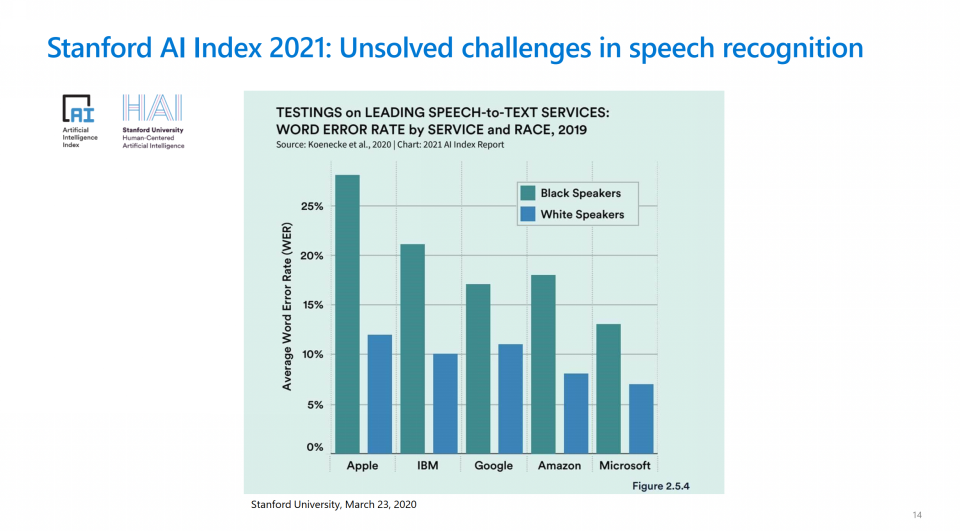
斯坦福发布的AI Index 2021中列出了语音识别领域面临的挑战:各语音识别系统对于黑人和白人的语音识别准确率上存在较大差距。而微软公司近两年一直致力于缩小此差距,并取得了不错的进展:微软的语音识别准确率远高于同类型竞品。
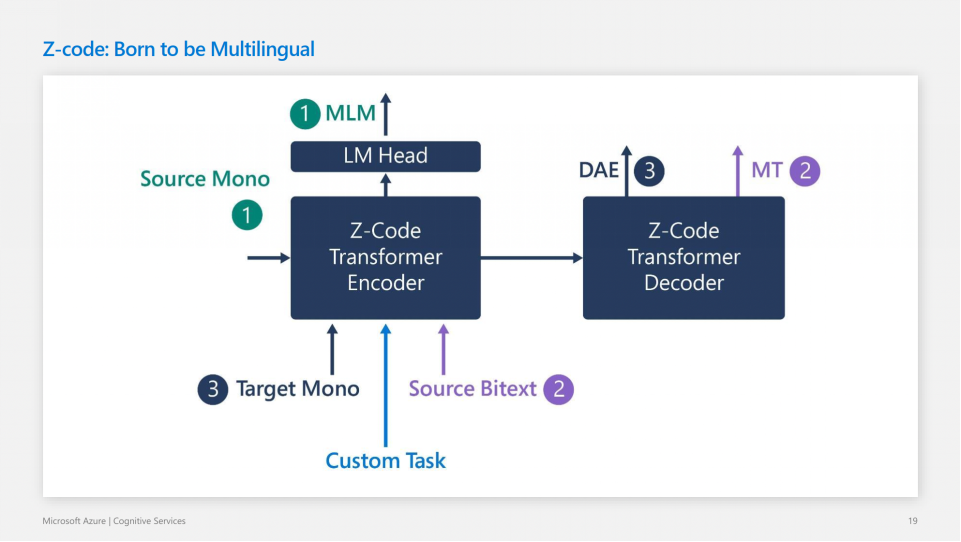
接下来黄教授介绍了Azure AI 团队在语言方面的进展,其中着重介绍了机器翻译模型Z-Code。
Z-Code的基本思想很直观:与传统的神经机器翻译方法不同,Z-Code不仅使用多语言的数据在机器翻译任务上进行训练,同时使用单语言数据作为补充,在掩码语言模型(MLM)任务上训练。使用多任务学习,同时优化多个目标函数。模型结构使用标准Transformer的编码器和解码器。
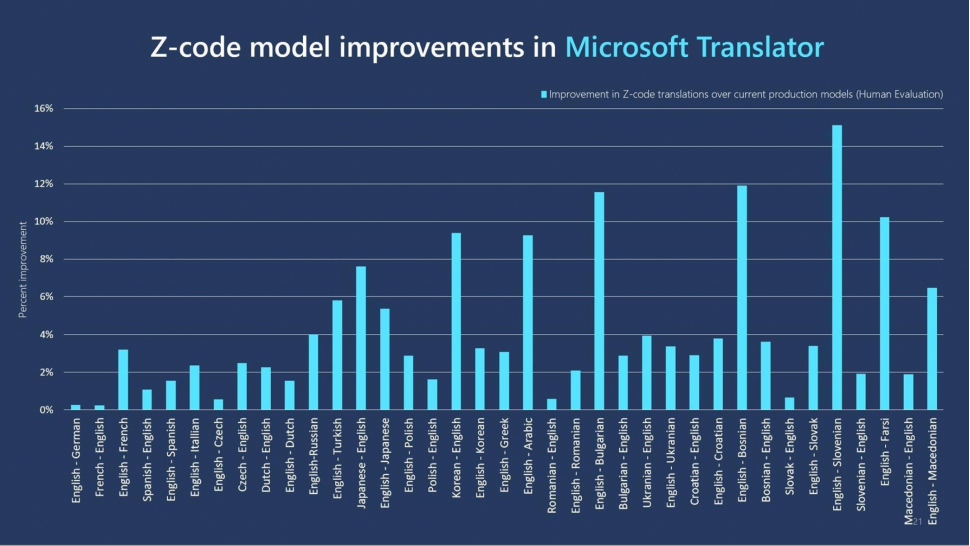
Z-Code的翻译效果非常好,也被应用到微软的各项产品中,帮助提高机器翻译的质量,如下图所示。下图的横轴为翻译的源语言和目标语言,纵轴为性能提升的幅度,可以看到在一些语料相对缺乏的小语种翻译场景,如English-Slovenian,Z-Code对翻译质量提升显著,而在语料库丰富的语种翻译场景,如English-German,Z-Code也能带来翻译质的提升。
鉴于Z-Code不俗的表现,黄教授团队又进一步将Z-Code升级拓展为Z-Code++,使其可以完成文本摘要任务,并在GENIE benchmark上取得了第一名的好成绩。

接下来黄学东教授介绍了团队过去两年里在计算机视觉方面取得的进展,主要是提出了计算机视觉领域的新基础模型Florence。
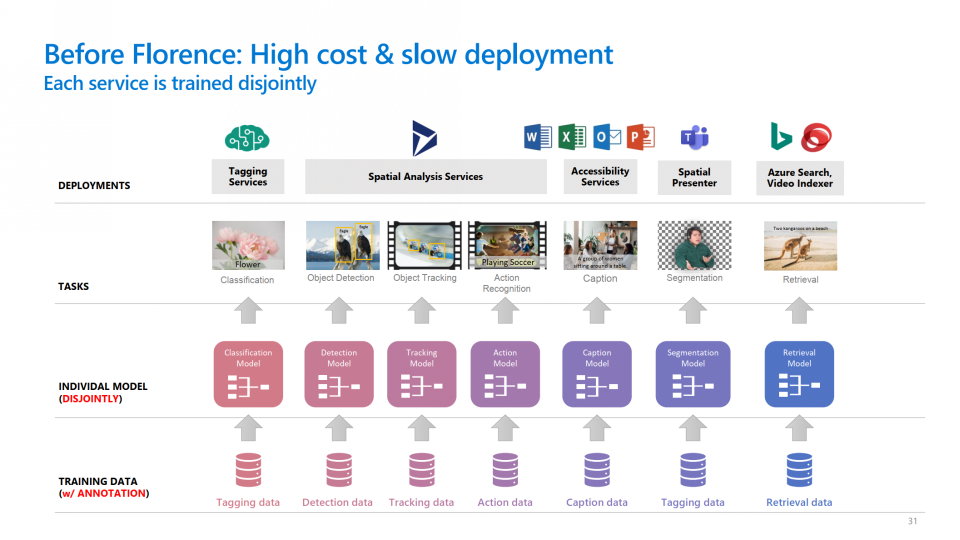
计算机视觉的任务有很多,如图像分类、图像检索、目标检测、分割、动作识别等,比语言和语音领域的任务更加多样化。在Florence出现之前,要完成这些视觉任务成本是很高的:首先需要为每一个任务收集、标注大量的训练数据,再为不同的任务设计各自的模型,最后分别对每个模型进行训练。
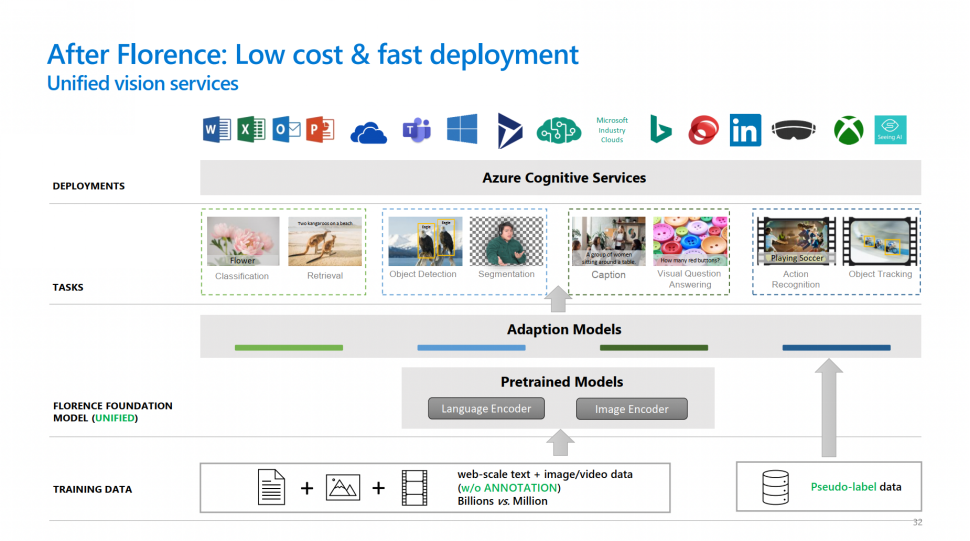
经过两年的研究,黄教授团队提出了Florence,一个应用于计算机视觉任务的预训练模型。Florence通过在预训练阶段引入文本语义信息来辅助处理计算机视觉的任务,预训练完成后,在模型后面接一些自适应的模块,即可将Florence模型适配到各式各样的视觉下游任务中。Florence不仅降低了完成这些视觉任务的成本,并且能够更快地被部署到不同任务上。
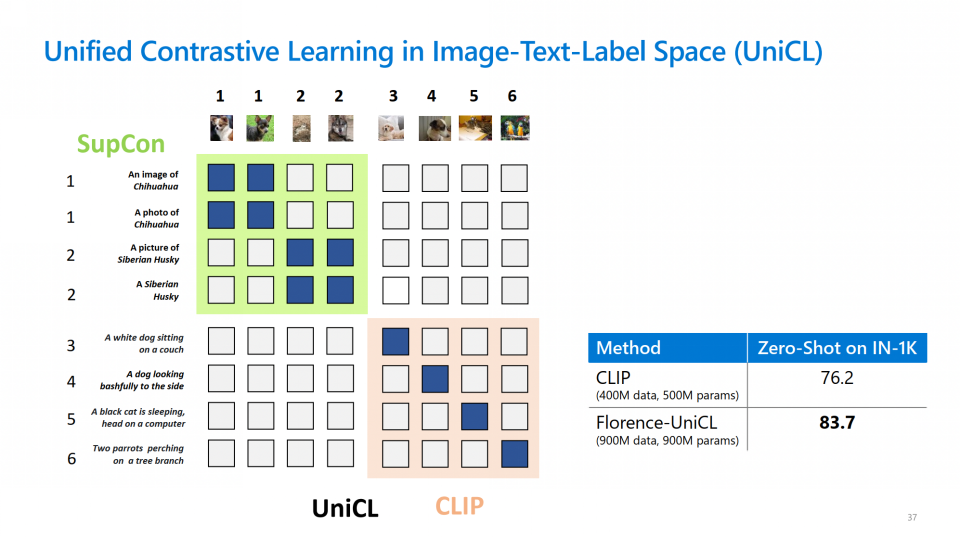
Florence的图像编码器使用的是最先进的Swin Transformer,文本编码器则使用传统的Transformer编码器。预训练任务方面,Florence提出了一种新的多模态对比学习方法UniCL:不同于CLIP在进行跨模态对比时仅将Image-Text pair视作正例,UniCL首先提取出语义相似的图片,让他们共享相同的标签,再借鉴Supervised Contrastive Learning的思想,让具有相同标签的Image-Text pairs的所有图片和文本都互为正例(下图的蓝色方块),标签不同的才互为负例(下图的白色方块)。在性能上,UniCL远超CLIP(下图83.7% v.s. 76.2%)。
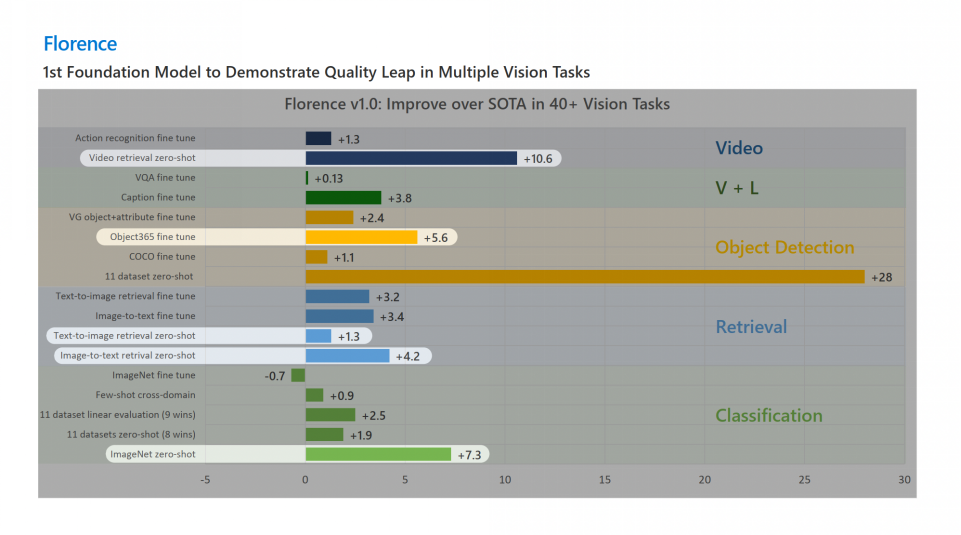
Florence模型在40多项视觉任务的评价基准中都取得了最先进的性能,涉及视频、视觉语言多模态、目标检测、检索、分类等领域。
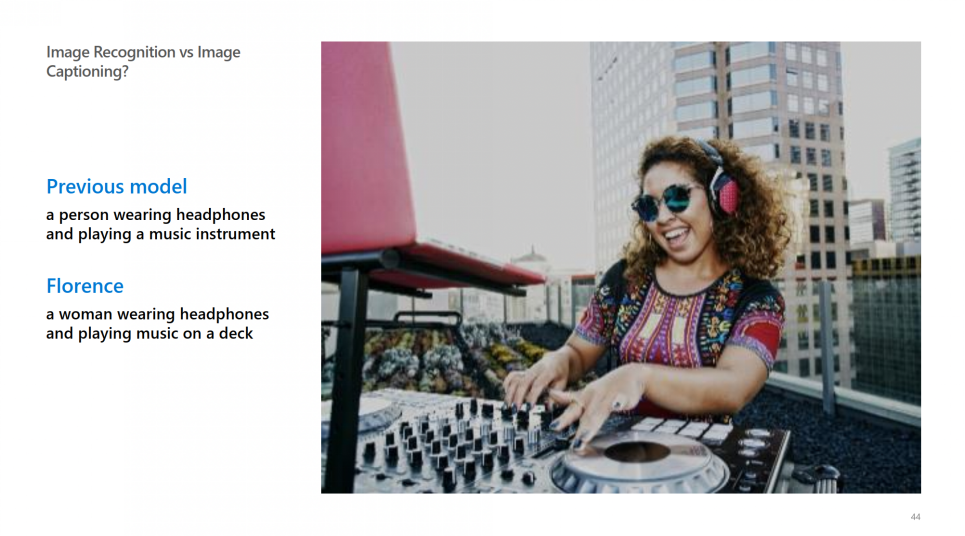
Florence模型的应用场景丰富:例如针对下图生成文字描述,之前的模型只能生成“playing a music instrument”(正在演奏一个乐器),Florence模型却可以生成更加具体的内容“playing music on a deck”(在调音台上演奏音乐)。
此外,Florence还可以为视障人士提供帮助。视障人士拍下图片,基于Florence的Azure Cognitive Services可以更加准确地识别图片里的内容,再通过文本到语音生成技术来生成语音帮助视障人士。

英国在神经科学方面有一项研究,探索为何人类比其他动物更加智能。其主要结论是,对于不同模态的信息,我们人类使用一组相同的神经元进行处理,因而可以更有效地融合这些信息。而动物则是采用一种“模式分离”(pattern separation)的机制,使用不同的神经元来处理不同模态的信息。人类有联合处理存储各式各样信息的能力,动物则没有,这种能力让人类具有了更高级的智能,这也是动物没有语言、人类有语言的原因之一。
这也正是Azure AI大力推动Integrative AI的原因。自黄学东教授成为Azure AI的CTO以来,Integrative AI就是整个团队的追求目标和前进方向,致力于对于不同模态的任务的联合优化。目前,人工智能公司所提供的API接口还都是独立分离的,在Integrative AI的驱动下,是否可以提供一个统一的用户界面和接口,让用户仅通过一个接口即可完成各种任务,实现进一步的智能,这是当下一个不小的挑战。
Azure AI研究团队已经取得了重大的进展,尤其是Z-Code,在机器翻译和文本摘要任务上都取得了不错的进展。此外,他认为还需要给模型引入外部知识,目前的深度学习Transformer模型是缺乏外部知识的,仅使用自注意力机制在训练语料中挖掘信息。多模态多任务联合优化、外部知识的引入是团队聚焦的两大重点,也是很有潜力的AI未来的方向。
文稿撰写 / 禹棋赢
排版编辑 / 蒲睿熙
校对责编 / 黄 妍






