8月18日晚,第十三期DISCOVER LAB青年科学家论坛顺利开展。本期活动有幸邀请到宾夕法尼亚大学计算机科学系助理教授刘玲洁博士,为我们线上做了题为Neural Representation and Rendering of 3D Real-world Scenes(3D真实场景中的神经表达与渲染)的精彩报告。本次活动由清华大学智能产业研究院(AIR)周谷越副教授主持。


刘玲洁博士一直从事计算机图形学、计算机视觉和机器学习的交叉领域的研究,具体聚焦于神经表达(Neural Representations),神经渲染(Neural Rendering),数字人建模(Human Performance Modeling)和三维重建(3D Reconstruction)。她尤其热衷于探索把传统图形学方法和深度学习相结合的新一代人体和普通物体的建模和渲染算法。刘玲洁博士即将入职宾大计算机信息科学系担任助理教授,并负责宾大图形学实验室团队。刘玲洁博士毕业于香港大学,在马克斯普朗克研究所进行博士后研究。她的研究成果主要发表于领域顶级学术会议 (SIGGRAPH、SIGGRAPH Asia、NeurIPS、CVPR、ICCV、ECCV、ICLR 等) 和顶级学术期刊 (TOG、TVCG 等)。她还在国际图形学顶级会议 SIGGRAPH 2022、SIGGRAPH 2023和 Pacific Graphics 2022 担任项目委员会委员。个人主页:https://lingjie0206.github.io/。
本次报告中,刘玲洁博士从快速渲染、三维重建、人体建模、三维生成模型和物理仿真模型几个方向分别介绍了个人及所在团队的研究,其中,刘博士重点阐述了使用稀疏体素的神经隐式表达加速渲染方法、高质量多视角的三维重建方法以及高保真的人体建模与渲染的研究成果。最后,刘博士也与我们分享了她对神经场景表达在未来的发展方向的想法并与同学们就报告中的内容展开了热烈的讨论。
刘玲洁博士首先介绍了神经场景表达的背景。我们生活在一个充满了变化的三维世界中,当下的人工智能领域正朝向高质量的三维感知发展,而其中的关键就是要对我们周围的环境进行高质量的场景表示。传统的方法通常由基于图像的三维建模和基于图形学的渲染方法构建管线,而在这两个步骤之间,往往存在着较大的差距,即三维重建中得到的3D模型质量使后续的渲染管线输出高质量的渲染图像变得非常困难。神经表达通过使用可微渲染,将原来的两个步骤合并为一个,利用渲染图片和真实图片之间的误差来优化神经模型。这样的表达方式废弃了传统方法中手工创建的特征,更有利于下游任务(如语义特征的抽取,等)的构建。

左图为COLMAP生成的3D模型,右图为图形学渲染框架中为了达到高质量的渲染结果所需要高质量3D模型
由于神经表达方法的渲染过程通常耗时较长,刘博士团队提出了首个基于神经稀疏体素网络的隐式表达加速方法 "Neural Sparse Voxel Fields"(NSVF)。此方法是NeurIPS 2020的spotlight的工作。通过观察现有方法的采样过程,刘博士团队发现他们通常在空白区域中采样了过多不必要的点,因此如果可以尽量避免在这些区域进行采样,即可大大缩减渲染所需要的时间。根据这个想法,刘博士团队提出了一种基于稀疏体素网格的场景表达,即只在物体的表面及其内部的体素进行采样,通过三线性插值计算采样点的特征,使得网络渲染的速度可以得到非常大的提升。
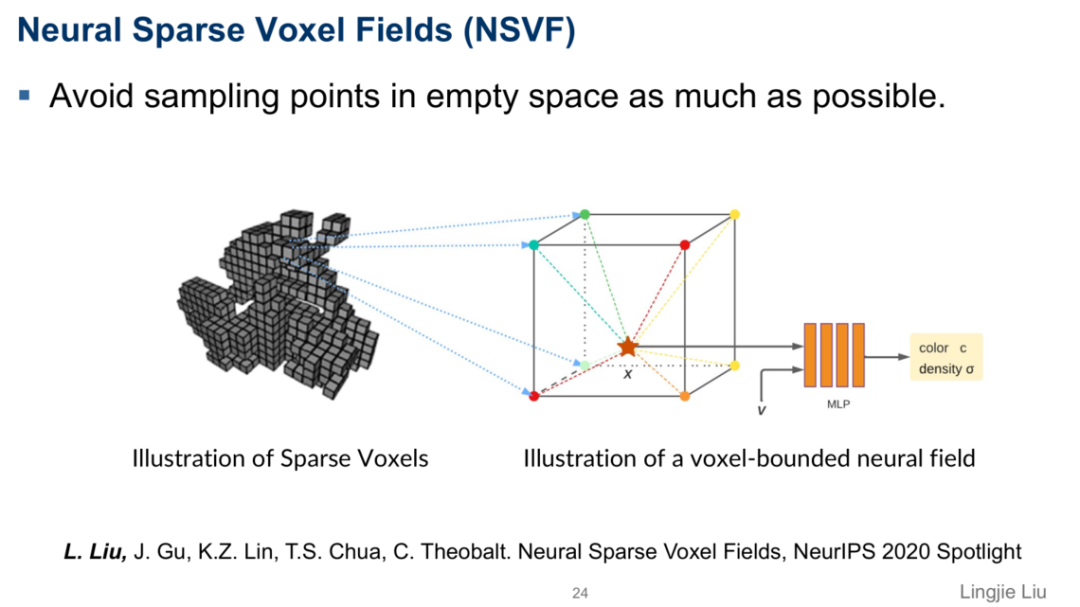
神经稀疏体素表示方法
为了得到这样的稀疏模型,刘博士团队采用一种逐渐精化的训练方法,使得场景表达可以从最开始的粗糙表示一步步细化得到精确的模型。

NSVF的训练过程
NSVF可以将神经表示的渲染速度从Baseline模型 NeRF的30s/帧提升到0.6s/帧,达到50倍的性能提升。除却渲染速度的提升,NSVF的局部表示方法也使得我们可以完成如模型编辑等的下游任务。NSVF方法一经发表便得到了学术界的广泛认可,后续的许多工作基于NSVF进行了如快速渲染、快速网络优化以及大规模场景的建模和编辑等的改进。
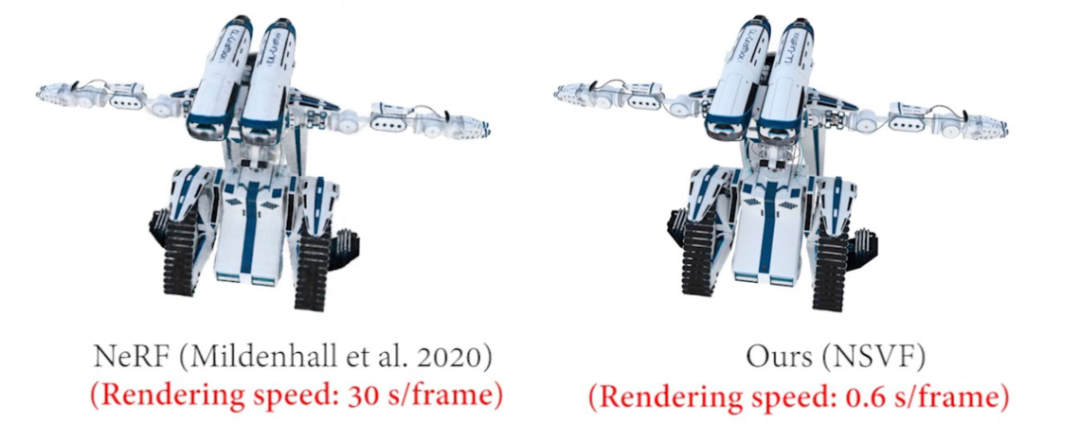
NSVF与NeRF的渲染效果和速度对比
由于以NeRF为代表的基于体密度的场景表达中缺少对物体表面的约束,因此我们经常可以在重建的模型中观察到明显的缺陷,而在2020年Yariv等人提出的IDR方法中,使用了一种基于符号距离场(SDF)的表达来优化重建出来的几何模型,然而在这一方法重建的结果中也能观察到明显的缺陷,其训练过程也需要人为提供额外的Masks作为输入来维持稳定。刘博士团队在2021年将上述的两种方法进行了有机的结合,提出了一种高质量的表面重建方法——NeuS。此工作是NeurIPS 2021的spotlight的工作。
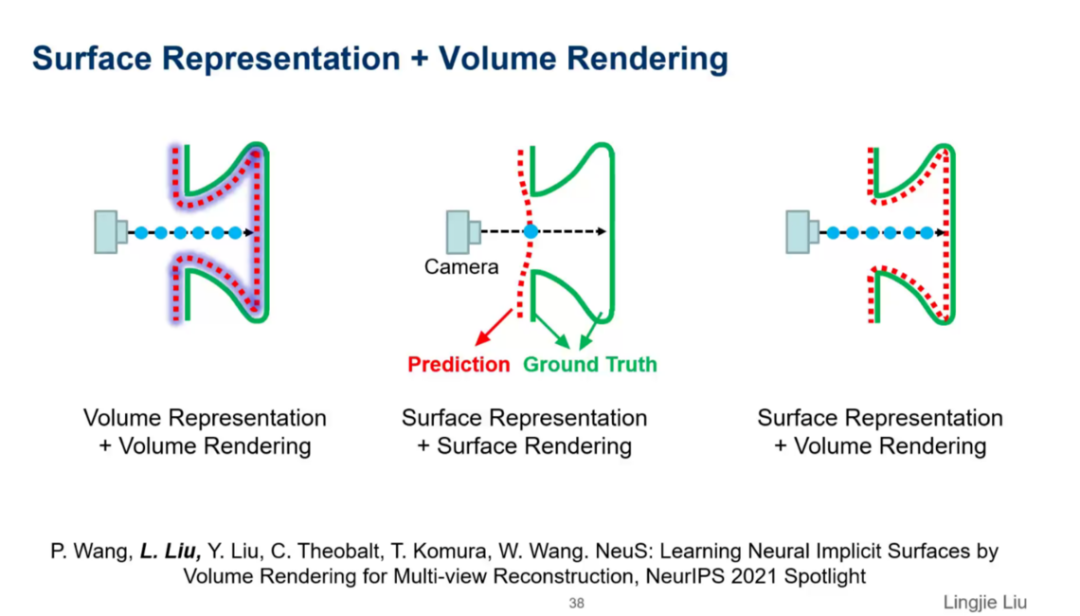
三维重建的相关工作中体渲染和表面重建的两种不同模式,NeuS将表面重建和体渲染结合来完成三维重建任务
在NeuS研究的过程中, 刘博士团队发现如果仅仅简单地用高斯分布建立起符号距离场到体渲染方法的桥梁,会在渲染权重的分布和实际表面之间引入一个不可避免的系统性误差,并会影响最终建立的模型质量。经过进一步观察,刘博士团队提出了两个为了建立高质量三维重建模型所必须的条件:首先,生成的权重分布的对称轴应与表面位置完全重合,即“无偏性”;其次,当光线先后穿过两个表面时,距离光线原点更近的表面理应对最终的渲染结果有更大的贡献。

其中,NeRF的渲染模型可以满足遮挡感知的要求,但无法达到无偏,而将符号距离场通过一个参数化的 Logistic分布计算权重的方法则只能满足无偏。刘博士团队通过将两种方式进行结合,提出了一种可以同时满足上述两种要求的权重计算方法来重建高质量的表面。

NeuS的三维重建结果与其相关工作的对比

NeuS方法在复杂几何表面上的高质量建模效果
虽然NeuS可以在许多复杂场景中重建高质量的表面,然而在室内的一些缺少纹理的场景下, NeuS的建模能力受到了较大的限制。因此在后续的研究中,刘博士团队进一步在室内场景中引入法向量的先验作为额外的监督来解决这一问题,提出了NeuRIS方法,并将这一工作发表在了ECCV 2022会议上。
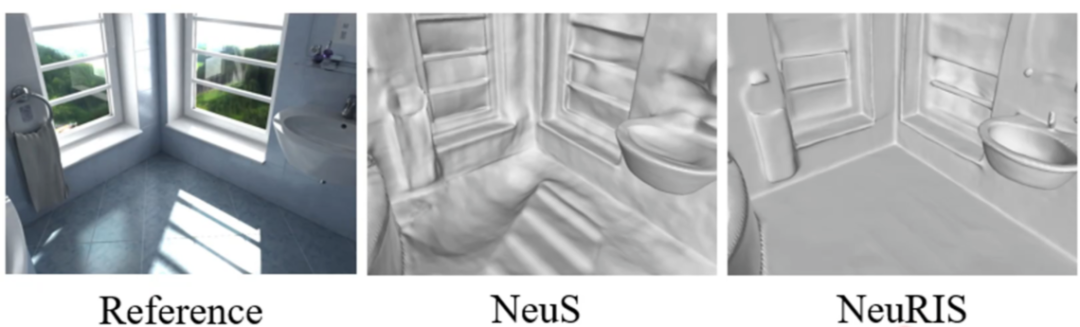
NeuRIS在特征较少的场景中的重建效果与NeuS的对比
接下来,刘博士为我们介绍了她和团队在人体建模及渲染上的Real-time Deep Dynamic Characters,该工作发表在SIGGRAPH 2021。刘博士团队通过对输入的多视角下的图片和相机参数估计对应的人体姿态,并结合可微渲染的方法,将渲染图片和真实图片的误差用于模型的优化。该方法可以可以对不同的人分别训练一个网格用于表示对应的几何和材质信息。通过直接对中间的人体姿态进行编辑,该方法可以直接输出对应姿态下的高质量渲染结果,从而实现在渲染画面上的编辑操作。
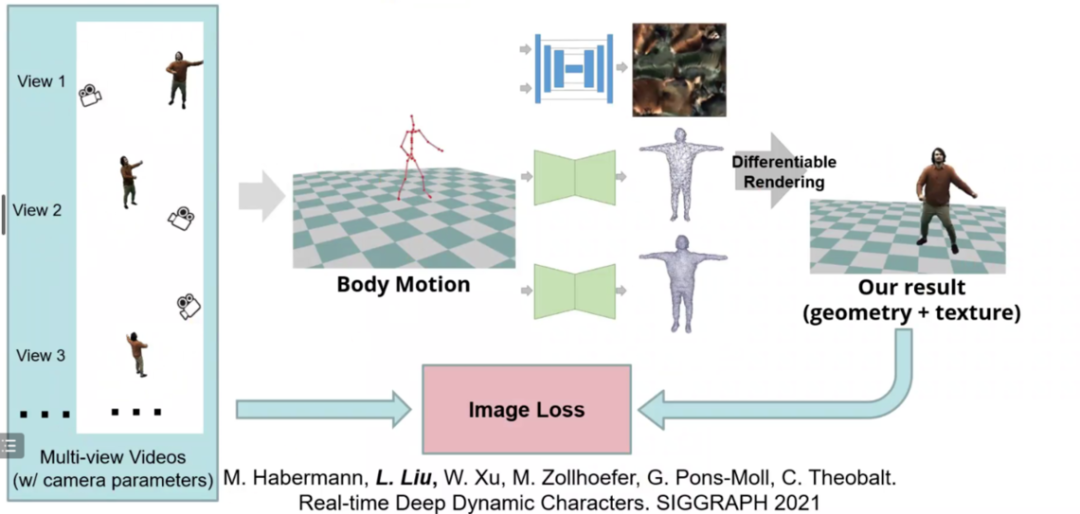
刘博士团队提出的DDC模型
然而,该方法也存在着一定的局限性,如需要对每个人单独优化一个模型,不能泛化到其他个体,以及这种基于网格的表示的分辨率受限,难以渲染高分辨率的结果。为了解决这样的缺陷,刘博士团队进一步将SMPL人体姿态模型与神经表示相结合,提出了Neural Actor方法,渲染高分辨,高清晰度的人体模型并提供了姿态控制的方法。Neural Actor发表在SIGGRAPH Asia 2021。
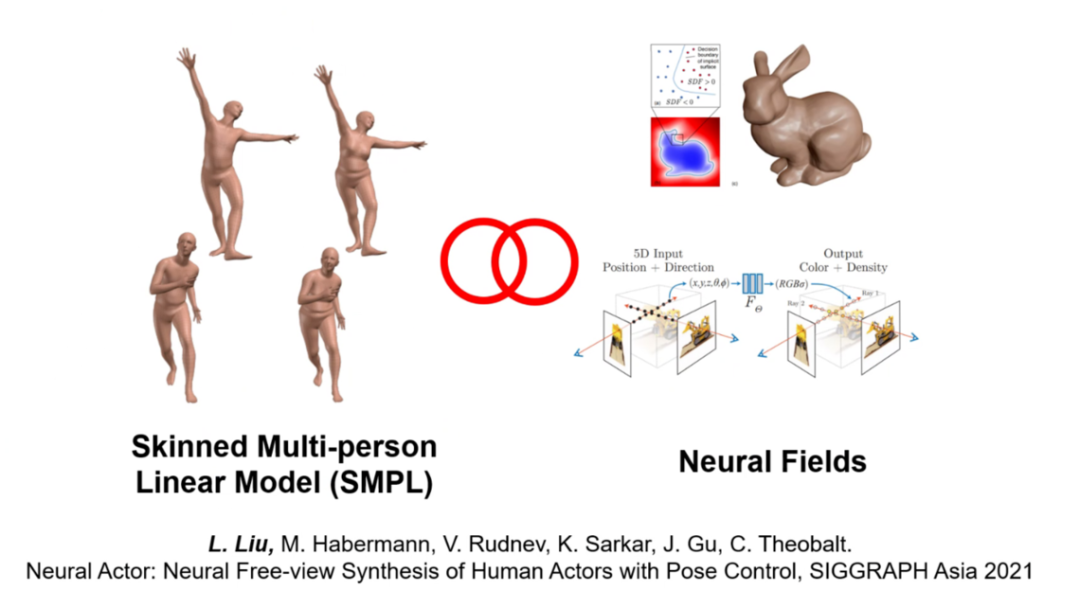
Neural Actor 方法结合SMPL表示和神经隐式表达
在此前的方法中通常存在渲染结果模糊的问题,这是由于在人体姿态和真实的几何、外观之间并不是一对一的映射关系,刘博士团队通过引入一个用纹理表示的隐变量解决了这一难题。Neural Actor的渲染结果中,我们可以看到清晰的纹理材质。

Neural Actor 与相关工作的效果对比
在Neural Actor中,我们甚至可以通过人体建模和另一位舞者的姿态序列信息,让一个完全不会跳舞的人在神经渲染的帮助下,录制一段优美的舞蹈视频。
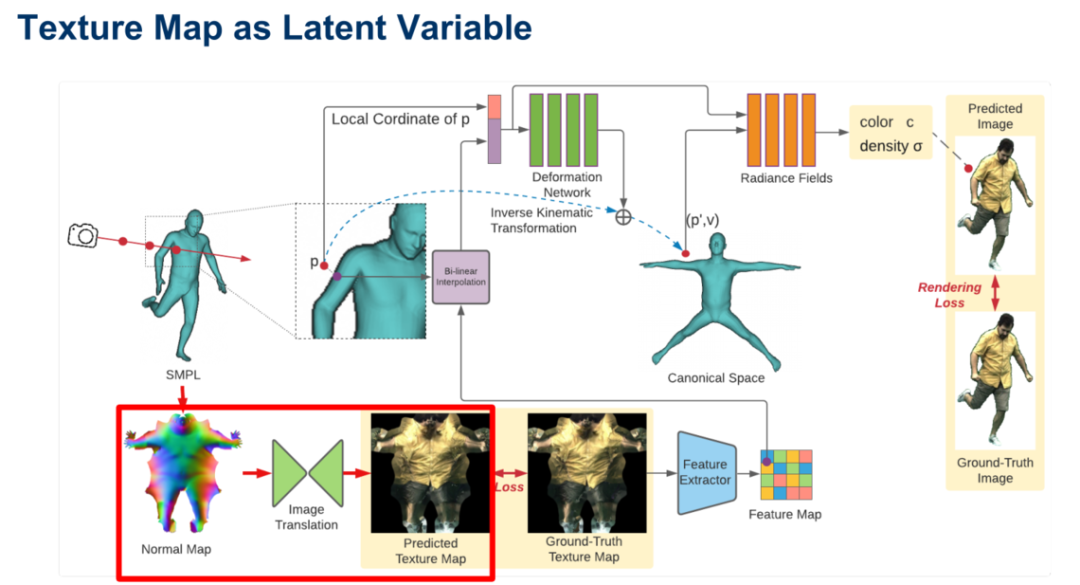
Neural Actor 使用材质图作为中间表示,承接人体姿态和渲染图之间的连接关系
近年来,我们看到了对抗生成网络(GAN)在人脸合成等任务上的优秀表现,根据这一思路,刘博士团队将二维大规模数据集成功地迁移到了三维多视角数据的合成上。通过一个三维的GAN模型,他们设计了一个三维的GAN 模型,StyleNeRF。StyleNeRF可以训练在单视角的人脸、汽车等二维数据集上,训练好的模型可以用来生成新的三维模型的多视角渲染图片。此工作发表在ICLR 2022上。

StyleNeRF在不同种类数据上的实验结果与相关工作的对比
在这一部分,刘博士首先为我们介绍了他们团队近期发表在SIGGRAPH 2022 上的工作:Neural Fluid Reconstruction,这一工作通过将Navier-Stokes等式等物理约束引入神经表示中,使得神经表示可以从稀疏的输入中学习流体的时序信息和对应的物理约束。

Neural Fluid Reconstruction中,刘博士团队引入物理约束,对三维流体进行重建和渲染
这一工作可以将场景中的静态和动态物体抽离开来,分别地进行渲染,在烟雾为代表的各类流体上得到了高清晰、高质量的渲染结果。
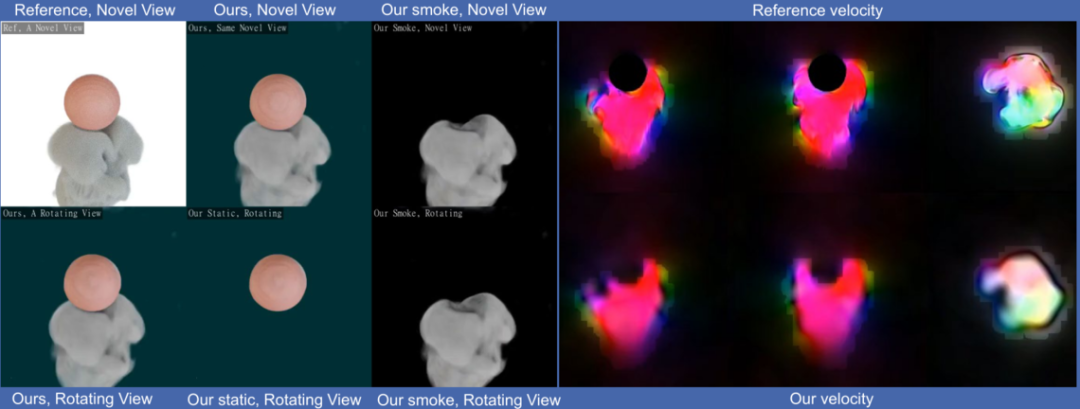
Neural Fluid Reconstruction 将静态物体和动态流体在时间序列上可以分别进行渲染
在ECCV 2022的工作NeRF-OSR中,刘博士团队首次提出了一种对户外场景同时进行新视角合成和环境光照控制的方法。该方法以NeRF为基本结构,同时结合了AlbedoNet、ShadowNet等不同方法来建模相关场景、纹理和光照。

NeRF OSR 可以在户外数据集同时合成新视角,并调整场景光照和阴影到指定的条件
在报告的最后,刘博士向我展示了神经表示在未来的几个可能的发展方向:
1. 在复杂的场景中建模人类和环境之间的交互以及其中可能存在的物理和环境约束;

2. 目前的神经表示通常表现为优化模型,在未来,我们希望能够提高神经表示的泛化能力,使得我们不需要再对每一个场景/人物优化一个单独的模型;

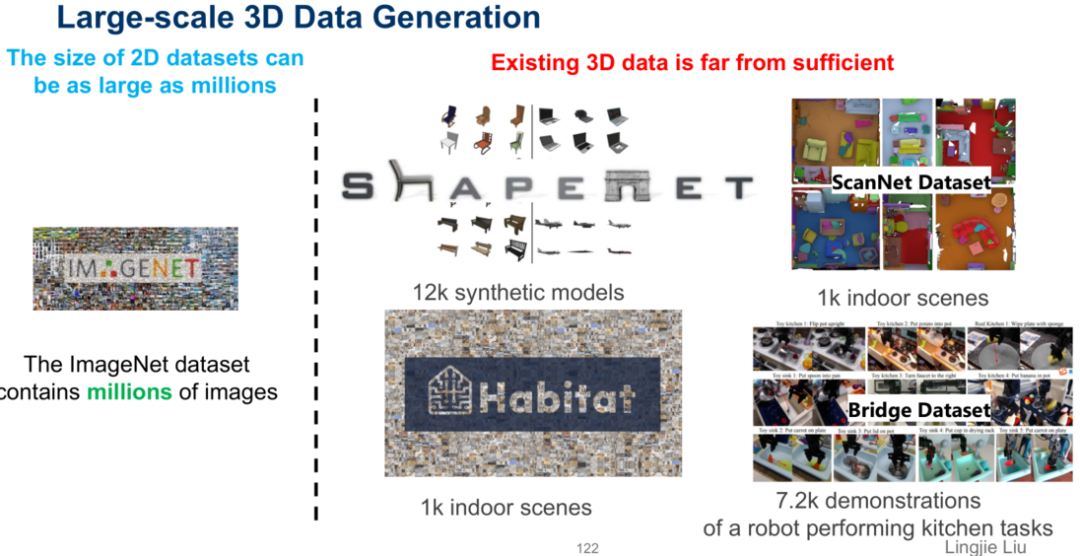
3. 在二维计算机视觉中,我们可以轻易地从ImageNet等数据集中快速地获取大量可用数据,而在三维计算机视觉中,三维建模等任务所需要的多视角数据的常用数据集相比起来要单薄许多。如果能够通过生成模型从而为数据集中获取大量的三维多视角信息,将会对该领域发展起到很大作用。
在报告结束之前,刘博士与线上线下参会的老师和同学们对报告所涉及的领域进行了热烈的探讨,针对同学们所提出的有关流体模型中的数据获取、人体建模方法中如何解决柔软材质衣服的渲染问题、NeRF-OSR中所使用的方法、三维场景表示、三维计算机视觉中的下游任务、神经表示中的时序信息利用以及该领域的未来发展方向上的问题一一给出了耐心的回答和细致的指导意见,并鼓励同学们在相关领域开展进一步的探索与研究。
DISCOVER实验室是AIR科研方向的横向支撑实验室之一,旨在利用机器学习、计算机视觉、计算机图形学、机器人学、运筹学、高性能计算与人机交互等前沿技术,围绕车路协同(V2I)、用户直连制造(C2M)、实验室自动化等各应用场景,构建以感知、规划、控制与决策为核心的智能算法平台体系,结合涵盖设计、工艺、计算与人因的智能系统架构体系,研究人-机-边-云四位一体的人在环路多智能体协同系统,开展具有创新性的算法理论与系统架构研究,紧贴以制造业为主的国家重点行业需求,攻克以人为中心的场景理解、人在环路机器学习、仿真到现实迁移与柔性制造工艺等关键技术瓶颈,与产业界深入合作探索自动驾驶与柔性制造的范式转移路径并实现关键技术验证与落地,推动我国在智慧交通和智能制造领域的产业升级。






