10月14日,AIR学术工作坊第五期围绕“
探索前沿,引领未来:智能新药研发
”主题,邀请了临港实验室副主任、华东师范大学药学院院长李洪林,北京大学前沿交叉学科研究院特聘研究员、博士生导师裴剑锋,清华大学生命科学学院、清华-北大生命科学联合中心研究员、博导张强锋,西湖大学AI讲席教授、IEEE Fellow李子青,清华大学智能产业研究院(AIR)教授兰艳艳,浙江大学药学院求是特聘教授侯廷军,百图生科CTO、人工智能首席科学家宋乐,AIR首席研究员/国强教授聂再清,清华大学药学院研究员田博学,智源健康计算研究中心负责人叶启威,AIR副教授周浩,AIR副教授马剑竹等多位跨领域的科研精英,共同探讨在人工智能浪潮下新药研发的科研前瞻性及应用前景。
本次研讨会总共分为两场,本期推送我们整理了研讨会下半场的几位嘉宾报告,分别是:

“触类旁通”和“智能涌现”的能力为通用人工智能的发展揭开了新的篇章。基础大模型与行业大模型的有机融合,将开创人工智能操作系统的新纪元,引领这一创新科技链接至各行业应用,扮演着引领未来的先驱角色。
10月14日,第5期AIR学术工作坊下半场的报告嘉宾:清华大学智能产业研究院(AIR)首席研究员、国强教授聂再清,为我们做了题为《多模态生物医药大模型》的报告。
聂再清,现任清华大学国强教授、智能产业研究院首席研究员。2004年获得美国亚利桑那州立大学博士学位,师从美国人工智能学会前主席Subbarao Kambhampati教授,本科和硕士毕业于清华大学计算机科学与技术系。2017年加入阿里巴巴,任阿里巴巴人工智能实验室北京负责人和阿里巴巴天猫精灵首席科学家。此前就职于微软亚洲研究院,任首席研究员。聂再清博士发表学术论文50余篇,申请了近30项专利,已经授权的有5项全球专利、18项美国专利、和1项中国专利。聂再清博士是微软学术搜索和人立方的发起人和负责人,也是微软自然语言理解平台LUIS的技术负责人。发明的知识图谱相关技术(包括实体信息挖掘、关系抽取技术、和实体名消歧技术)、对象级别的信息搜索技术、语音语义一体化理解技术等,被广泛应用于互联网搜索引擎、聊天机器人、以及智能助手等领域。引领了业内大数据驱动的知识图谱(knowledge graph)挖掘和应用相关技术的创新,在微软期间被授予Microsoft Golden Star奖。在阿里巴巴集团达摩院期间,聂再清博士作为天猫精灵首席科学家,带领团队从无到有实现天猫精灵的所有相关算法研发和创新工作,把人工智能最前沿技术真正落地到千家万户,为千万家庭带来欢乐和陪伴。2019年他所带领的团队获得吴文俊人工智能科技进步奖。
聂再清教授在报告中着重介绍了团队在研的生物医药大模型BioMedGPT及相关研究工作的最新进展,以孵化公司水木分子自研的新一代对话式药物研发助手ChatDD。
ChatGPT或许标志着第四次工业革命的崭新起点,以其为代表的大模型拥有两个显著的能力特性:
“触类旁通”能力。在通过新的学习算法如Instruction Learning等进行训练后,模型在N个任务上获得性能提升,并在第N+1个前所未见的相关任务上同样获得性能的提升。借助于Instruction Learning,大型语言模型将人类的丰富语言与语义在模型层面上进行了紧密的连接。同时,还可以通过强化学习把任务数量N加到很大,从学到的Reward Model来产生监督信号。
“智能涌现”能力。众多科学实验已证实,当模型的参数规模增大到一定程度时,许多任务的性能可以得到急剧提升,实现了量变到质变的转换。在NLP的许多任务上,100亿参数的模型可以大幅提高性能。
聂再清教授精辟地指出:“触类旁通”和“智能涌现”的能力已经为通用人工智能的发展揭开了新的篇章,基础大模型与行业大模型的结合将成为人工智能时代的操作系统,从而链接至各行业应用。而大模型的下一站就是生物学,生物医药行业大模型将为新科学带来新范式。
在生物医药领域,分子语言和自然语言有许多相似之处。例如,蛋白质可以通过一个代表着氨基酸的字符序列表示,而这些字符序列能够决定蛋白质的结构,进而决定其功能以及与药物的结合能力。蛋白质的功能又决定了下一次基因变异产生的新蛋白的生存和遗传概率,只有真正合理的序列才会被自然法则选择产生出来,这与自然语言具有语法限制类似。
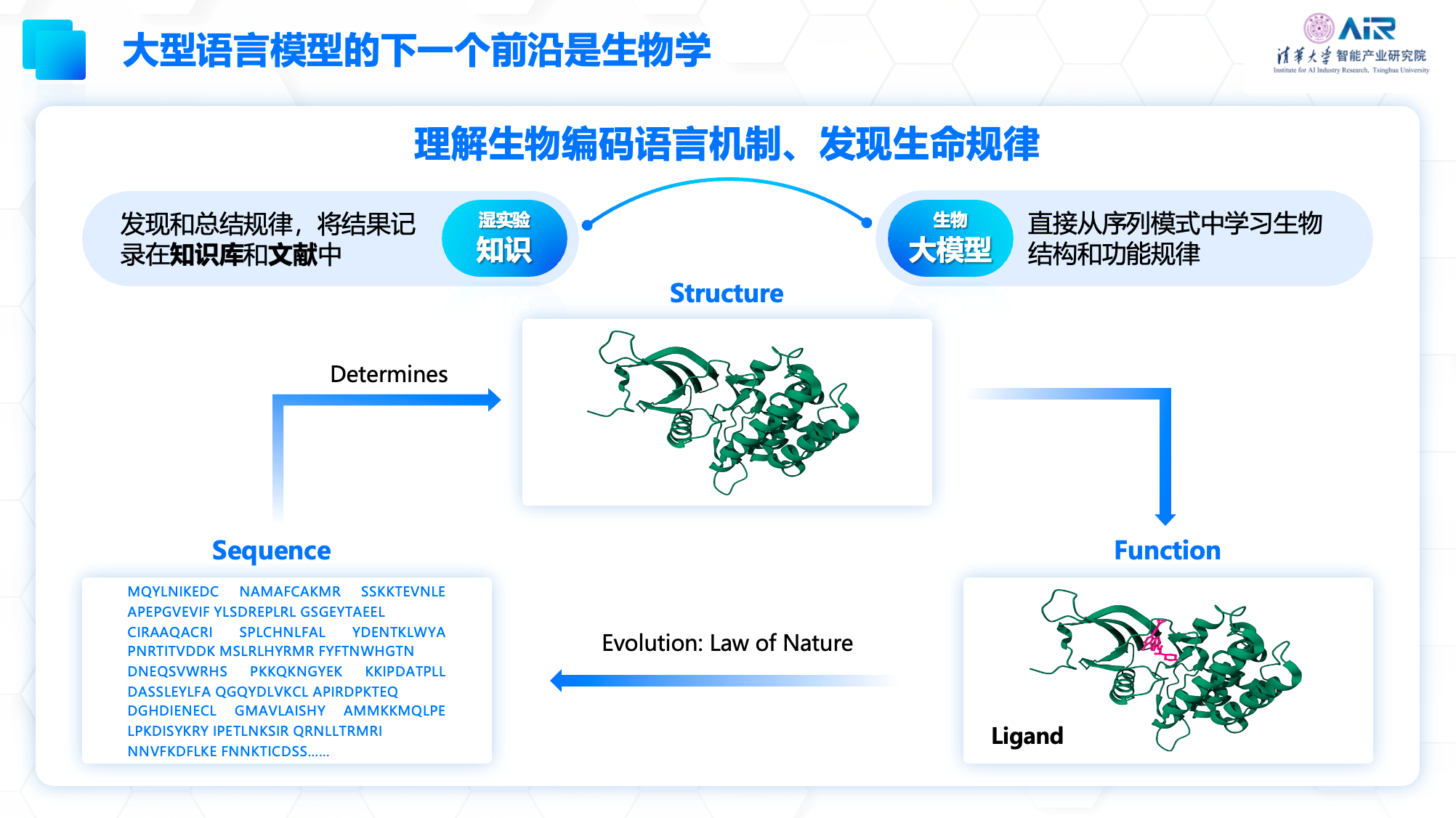
目前,生物医药领域已经存在许多多模态数据,包括蛋白大分子数据、可成药小分子数据和单细胞数据,以及自然语言文本(如论文)和知识图谱等不同模态的数据。每个数据都可以通过自监督学习来训练一个大模型。例如,对于一个靶点JAK1,可以通过大模型学习到的向量来表示,而相应的小分子药物也可以有小分子的表示。除了分子序列信息这个模态,还可以通过人类总结的海量论文和知识图谱信息这些模态的信息进行自监督学习,以表示这个靶点和小分子药之间的关系等等。在这样的背景下,聂再清教授团队也进行了非常多的探索。
KEDD:将多模态信息用于药物研发AIDD任务。KEDD通过融合分子结构、知识图谱和文本,构建多模态数据统一表示,大幅提升如药物性质预测、药物-靶点相互作用等AIDD任务的表现,佐证了融合多模态生物医药数据的价值和意义。
CellLM:构建高效细胞编码器,进行单细胞语义表征。CellLM在超过45M的单细胞数据上进行预训练,并通过设计的预训练任务理解疾病和正常细胞之间的表征差异以提升在CellLM对疾病数据的理解。CellLM在较有挑战性的细胞类型注释、药物敏感性预测等任务进行测试,均取得SOTA的结果表现。
BioMedGPT:百亿参数开源多模态生物医药大模型
更进一步,聂再清教授团队与水木分子公司合作,构建了多模态生物医药领域的基础模型——BioMedGPT,旨在将生物世界中的分子、文本和知识进行统一表示学习,以提高各项下游任务的能力。BioMedGPT在数据层面整合了基因、分子、细胞、蛋白、文献、专利、知识库等多源异构的数据,首次将知识引入到模型构建中,实现了生物世界文本和知识的统一表示学习,增强了模型的泛化能力和可解释性。在应用任务方面,BioMedGPT能够处理自然语言、药物性质预测、跨模态生成等多个任务,实现对生命科学全域任务的探索,已经在多个关键下游任务中取得了最佳效果。
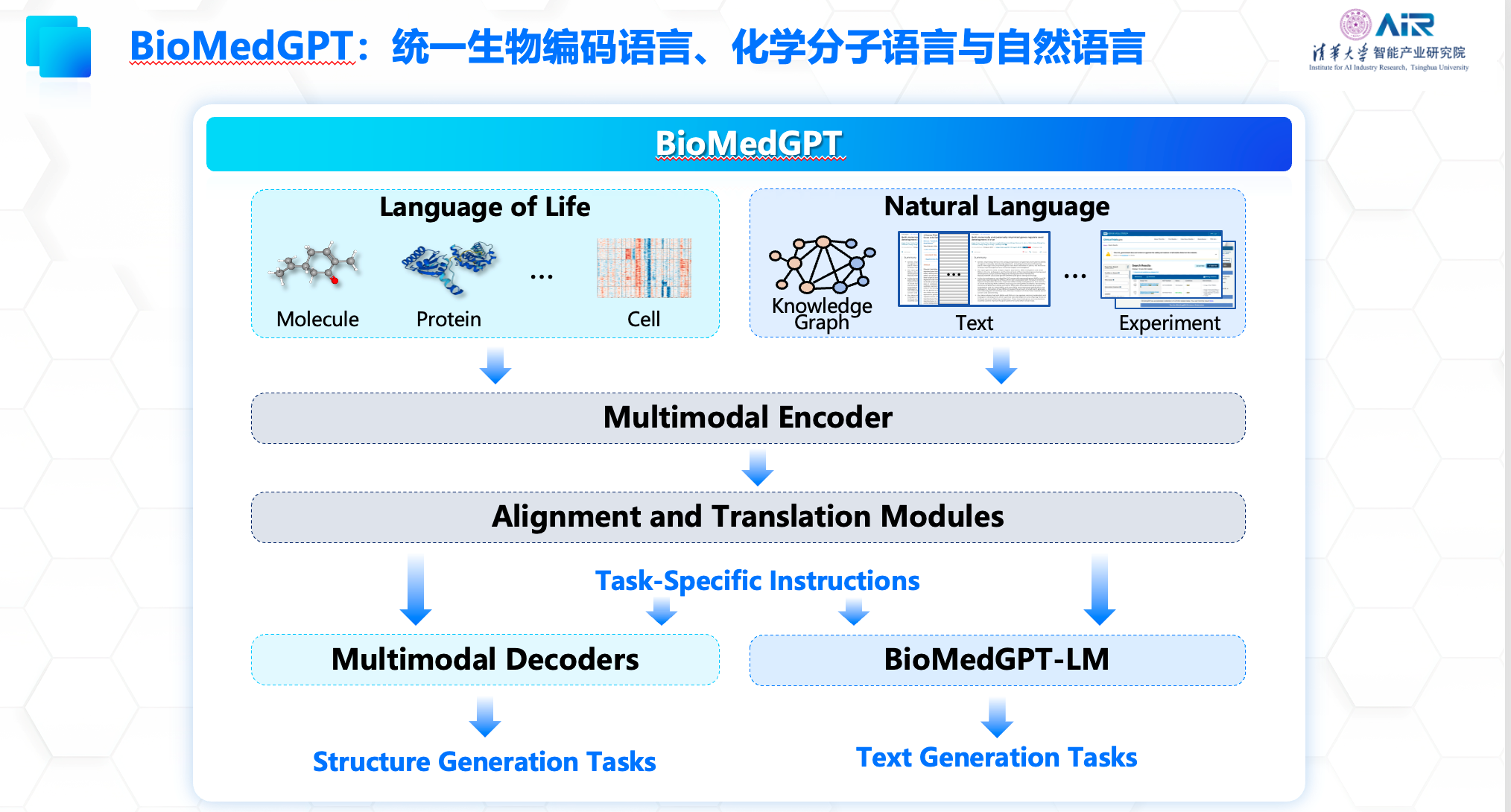
同时,为了促进学术和工业发展,打造良好的生物医药大模型生态环境,聂再清教授团队于4月开源轻量级科研版基础模型BioMedGPT-1.6B,聂再清教授团队联合水木分子在8月开源全球首个可商用百亿参数多模态生物医药大模型BioMedGPT-10B。
其中BioMedGPT-10B支持跨模态自然语言和分子语言的交互式问答,为验证模型在跨模态交互式问答中的能力,团队提出分子自然语言跨模态QA、蛋白质自然语言跨模态QA任务,针对输入分子式、蛋白质序列生成相应对自然语言描述,可在药物靶点探索与挖掘、先导化合物设计与优化、蛋白质设计等领域得以应用。
同时,BioMedGPT学习了大规模的生物医学文献数据,其语言能力在生物医学领域表现更为出色。在多个生物医药问答基准数据集上实现了SOTA,比肩人类医学专家水平,已成功通过了美国医师资格考试。
-
更多详细信息可见:https://air.tsinghua.edu.cn/info/1007/2077.htm
-
BioMedGPT开源项目网址:https://github.com/PharMolix/OpenBioMed
同时,AIR与水木分子合作,共同推进AI4S科学研究。例如,一起提出了跨尺度、跨模态、跨任务的统一微观“大-小”分子建模方法,在药物分子的本征空间进行表示学习,构造举一反三的鲁棒性好、泛化能力强的统一药物小分子和蛋白大分子的分子大模型。期望构建多尺度统一表示的“大-小”分子编码器,解决小分子、大分子尺度各异(从原子尺度到氨基酸尺度)、兼容性差,难以统一建模的问题。
ChatDD: 新一代对话式药物研发助手,引领药物研发第四范式
药物研发经历了从手工制药TMDD到计算机辅助设计CADD,再到人工智能辅助设计AIDD的演进。每个阶段都不同程度地提高了效率和促进了科学发展,为药物研发带来了新的机遇和挑战。
第一代手工制药TMDD:基于经验主义的,通过大量实验试错来实现。
第二代计算机辅助设计CADD:通过计算机模拟建模,减少了对湿实验的依赖。
第三代人工智能辅助设计AIDD:应用人工智能技术从训练数据中挖掘药物发现和设计规律。但面临着训练数据不足、信息与知识分离、工具服务分散以及处理模态单一等挑战。
水木分子提出的ChatDD,基于大模型的能力,能够对多模态数据进行融合理解,并能够与专家进行自然交互和人机协作。ChatDD将人类专家知识与大模型知识联结起来,重新定义了药物研发的模式。它以全新的方式来应对药物研发中的各种挑战,为实现高效、精准的药物研发提供了新的可能性。
ChatDD的底座为千亿参数多模态生物医药对话大模型 ChatDD-FM 100B,
在通用语言模型基础上经过:生物医药专业知识增强、生物医药多模态对齐、专业领域指令微调和RLHF三层淬炼,成为更懂行业的大模型底座。
ChatDD 具备专业知识力、认知探索力和工具调用能力。
作为生物医药研发助手 Copilot 可以服务医药研发全流程场景,从立项调研,早期药物发现,临床前研究到临床试验、药物重定位等各环节。






