和自然界的生物分子不同,化学小分子多数是由人类创造出来的,其存在不代表有确定的功能意义,让化学大模型具有更多与药物相关的知识对于AI药物设计是非常重要的。
10月14日,第5期AIR学术工作坊第二位嘉宾:北京大学前沿交叉学科研究院特聘研究员,博士生导师裴剑锋教授,为我们做了题为《PharmGPT生成式大模型及其在药物设计中的应用》的报告。

北京大学前沿交叉学科研究院特聘研究员,博士生导师,2014年起在国内率先开展人工智能药物设计研究,在JACS、PNAS、Nucleic Acids Res、J Med Chem、Nature、Chem Sci等国际重要学术刊物上发表论文70多篇,申请获得专利6项,软件著作权8项。主持和承担863计划、重大新药创制国家科技重大专项、国家基金委重点项目等国家科研项目多项。曾获中国药学会施维雅青年药物化学奖,中国化学会青年计算化学奖和药明康德生命化学研究奖。
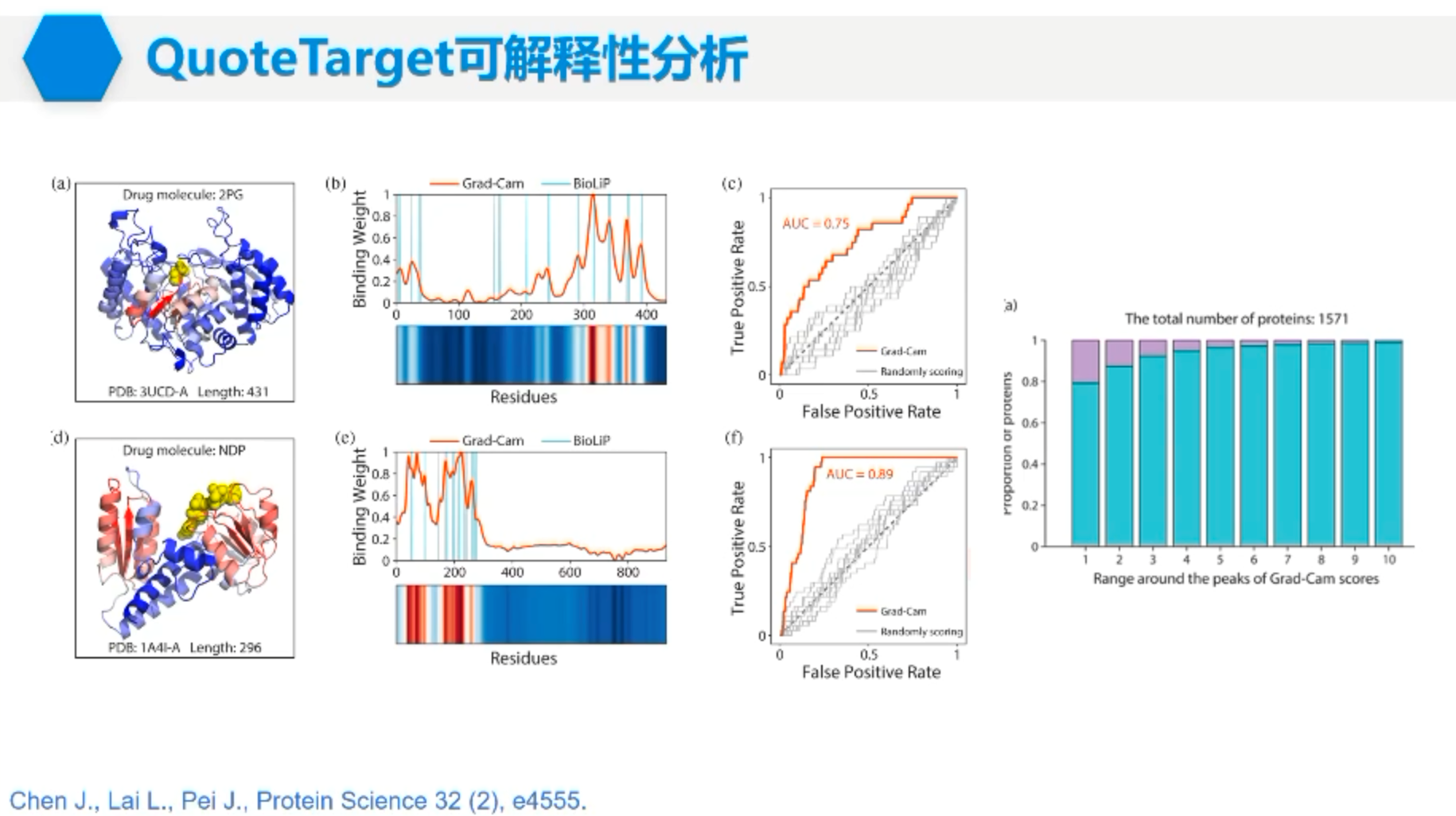
裴教授从靶标的角度为我们介绍了AI在生物学中的应用。最近蛋白大模型预训练更是火热(例如ESMFold)。基于新的预训练方法,裴教授为我们进一步介绍了新的蛋白质功能预测框架QuoteTarget。新的框架在很多任务上都有很大的提升。不仅如此,QuoteTarget也提供了一定的可解释性。分析在序列特征上找到模型重点关注的位置到结构上的对应关系,可以发现80%~90%的情况都对应药物的结合位点。不过裴教授也对模型的泛化性能表达了担忧,基于序列的深度学习模型在全新序列上的泛化性仍然是未知的。
接下来裴教授为我们介绍了集成各项先进技术形成的靶点评估平台TopTargets。该平台对于上市药物靶点的价值分析中展示了非常高的准确率,在销售前100的药物对应的靶点上,TopTargets成功将76%的靶点预测为高价值靶点。裴教授相信这个平台在未来也可以为大家带来更多的帮助。
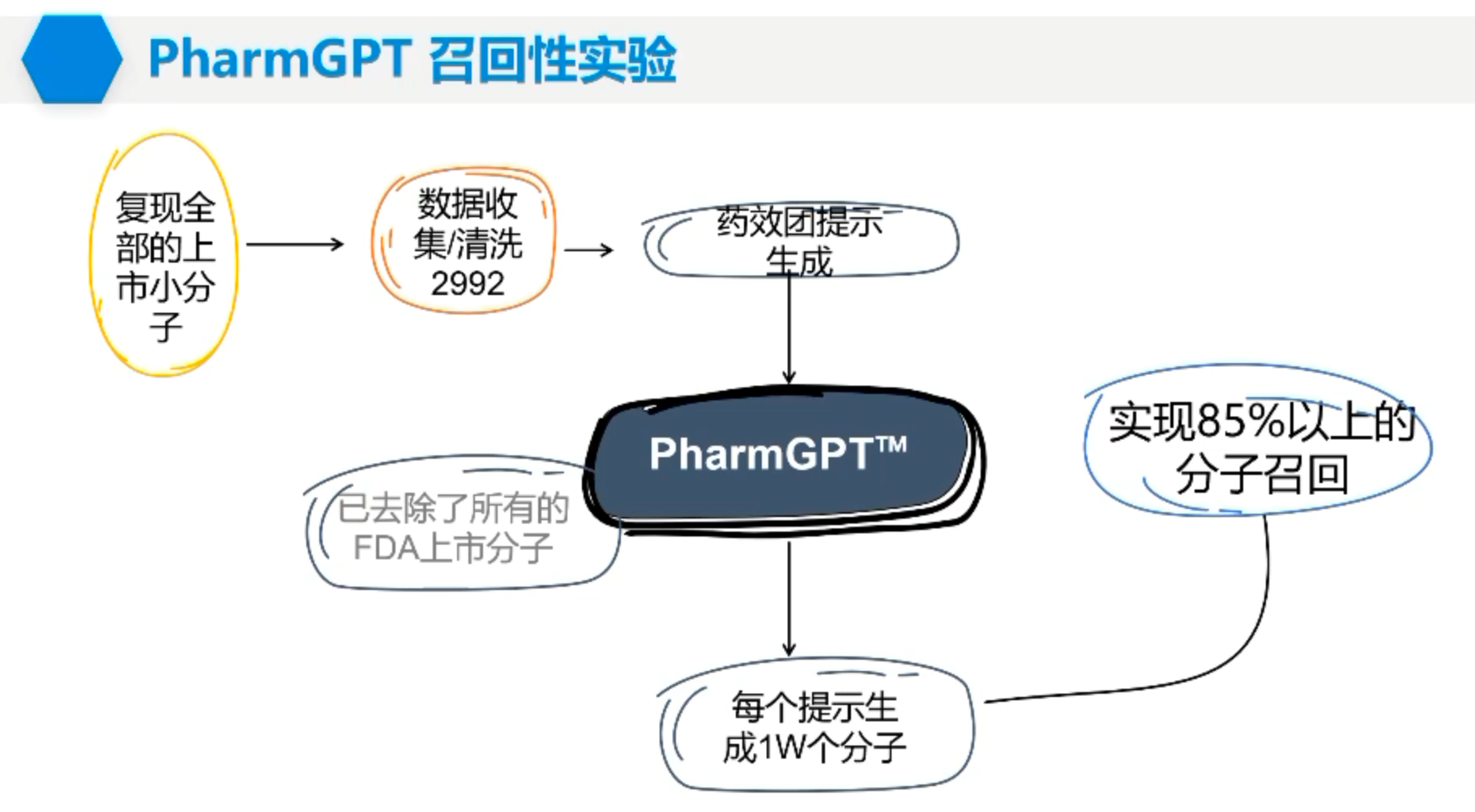
结束了靶标层面的探讨后,裴老师带我们进入了AI在化学大模型中的应用。裴教授首先为我们总结了常见的小分子预训练模型及其预训练方法。然而,使用大模型进行分子生成的工作,仍旧是一片蓝海。目前的药物分子生成模型仍然具有较大的局限性,基于结构的分子生成方法还很不成熟,基于配体的生成则被批评为生成的分子和现有药物分子的结构过于相似。为解决这些问题,发展更通用的药物分子生成大模型,裴教授团队联合英飞智药发展了PharmGPT生成式大模型,一个非常令人振奋的测试是上市小分子的召回实验。训练集中不包含上市的小分子。PharmGPT对于每个药效团prompt生成10000个分子,如果其中包含上市分子则视为成功。最后模型召回了85%以上的药物分子召回,展现出了其强大的潜力的通用性。
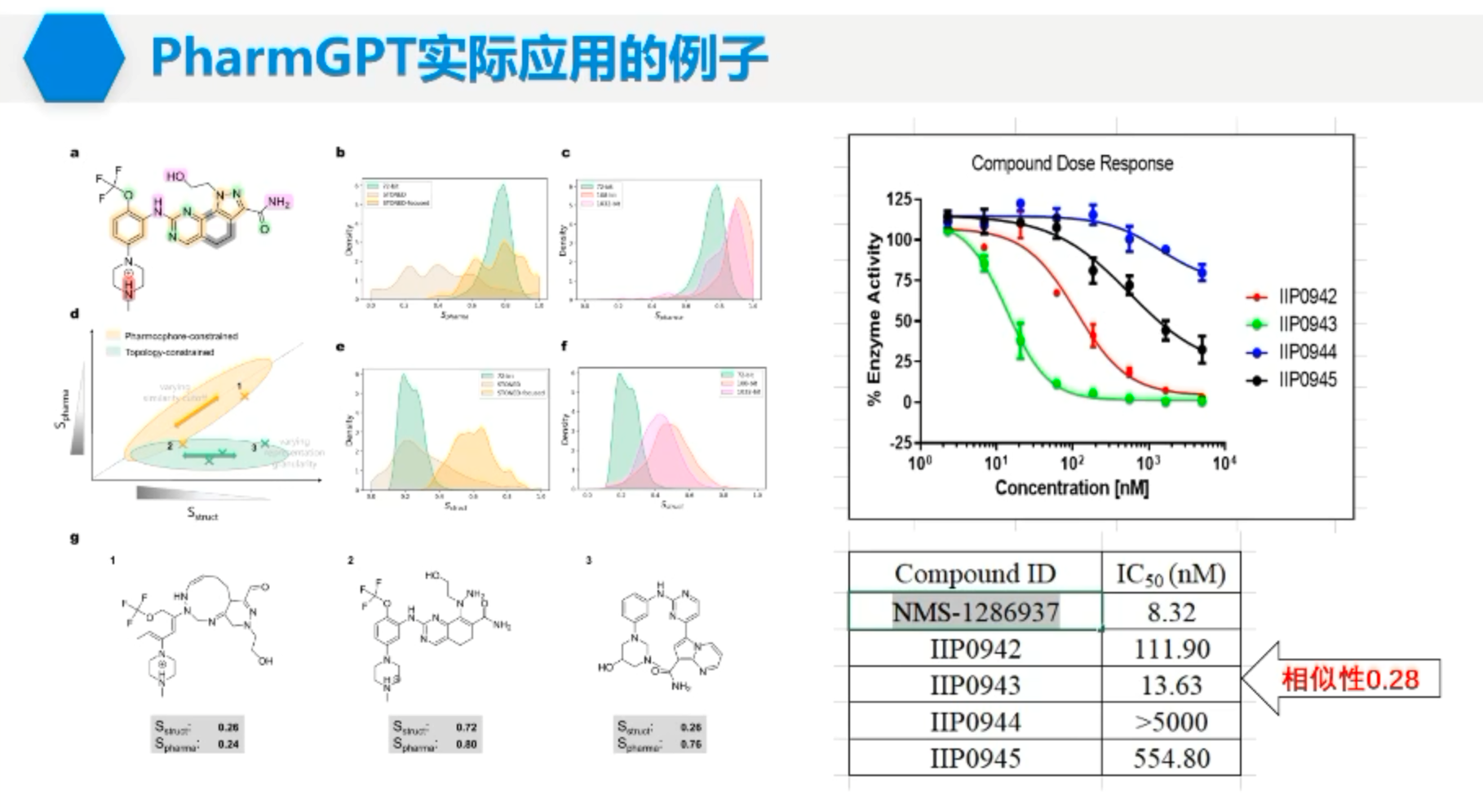
PharmGPT的一大优势是可以生成药效上相似,但结构上不相似的分子。例如对于PLK1抑制剂目前活跃的临床二期分子NMS-1286937,PharmGPT生成了一系列在药效团上与它类似的分子,对其中的4个小分子进行了化学合成和湿实验验证,发现其中一个分子的酶活抑制IC50值接近阳性分子NMS-128693,但二者的分子相似性只有0.28。这样的能力使得PharmGPT可以很容易突破分子骨架的限制。
最后,裴教授也介绍了DeepLigBuilder生成技术,用于基于靶点的药物分子三维结构生成。PharmGPT和DeepLigBuilder在多个管线中找到潜在PCC分子,且具有极高的设计成功率。







