8月10日晚,由DISCOVER实验室主办的第二十三期AIR青年科学家论坛顺利开展。本期活动有幸邀请到清华大学电子工程系助理教授姚权铭,为我们做了题为LLM for Structured Data - where is the way(用于结构化数据的大语言模型——路在何方)的精彩报告。


姚权铭博士是清华大学电子工程系助理教授。于香港科技大学计算机系取得博士学位,之后加入第四范式担任高级科学家,创建和领导公司的自动化机器学习研究组。主要研究方向是机器学习,特别是自动化和可解释的结构化数据学习方法。已发表论文70余篇;总引用7000余次。任机器学习主要会议ICML、NeurIPS、ICLR领域主席;Neural Network和Machine Learning编委。荣获过国际神经网络学会早期成就奖(全球2人)、香港科学会优秀青年科学家(全港2人)、吴文俊人工智能学会优秀青年奖(全国15人)、Google全球博士奖(全球13人)同时入选全球Top 50华人AI青年学者榜和福波斯30Under30精英榜。
本次演讲分为三个部分,结构化数据处理的一条路线图,结构话数据处理的两个瓶颈以及结构化数据处理的三个尝试。
最近一段时间以来,大语言模型(LLM)令人惊奇的表现引起了全世界的关注。随着模型大小、数据集大小以及用于训练的计算资源增加,语言模型的性能也不断提升。姚权铭博士以自然语言处理为演讲开端提出了一个问题,即自然语言处理的路线图,包括使用表达能力强的模型,进行通用的预训练任务,和针对特定任务的微调,是否也适用于结构化数据的处理。姚权铭博士以Open Graph Benchmark (OGB)的三个任务为例对这一问题进行了探索,并分别展示了在节点级、链接级和图级不同任务的性能分布和最优架构的差异,说明了结构化数据可能不存在一个通用的大模型来适应不同的架构和任务。姚权铭博士通过展示不同Graph的技术的表现,指出了在深度增加时模型不一定会收敛,甚至还会出现表达能力下降的情况。这就提出了一个令人深思问题,即如何设计有效的预训练任务和模型架构来处理结构化数据。
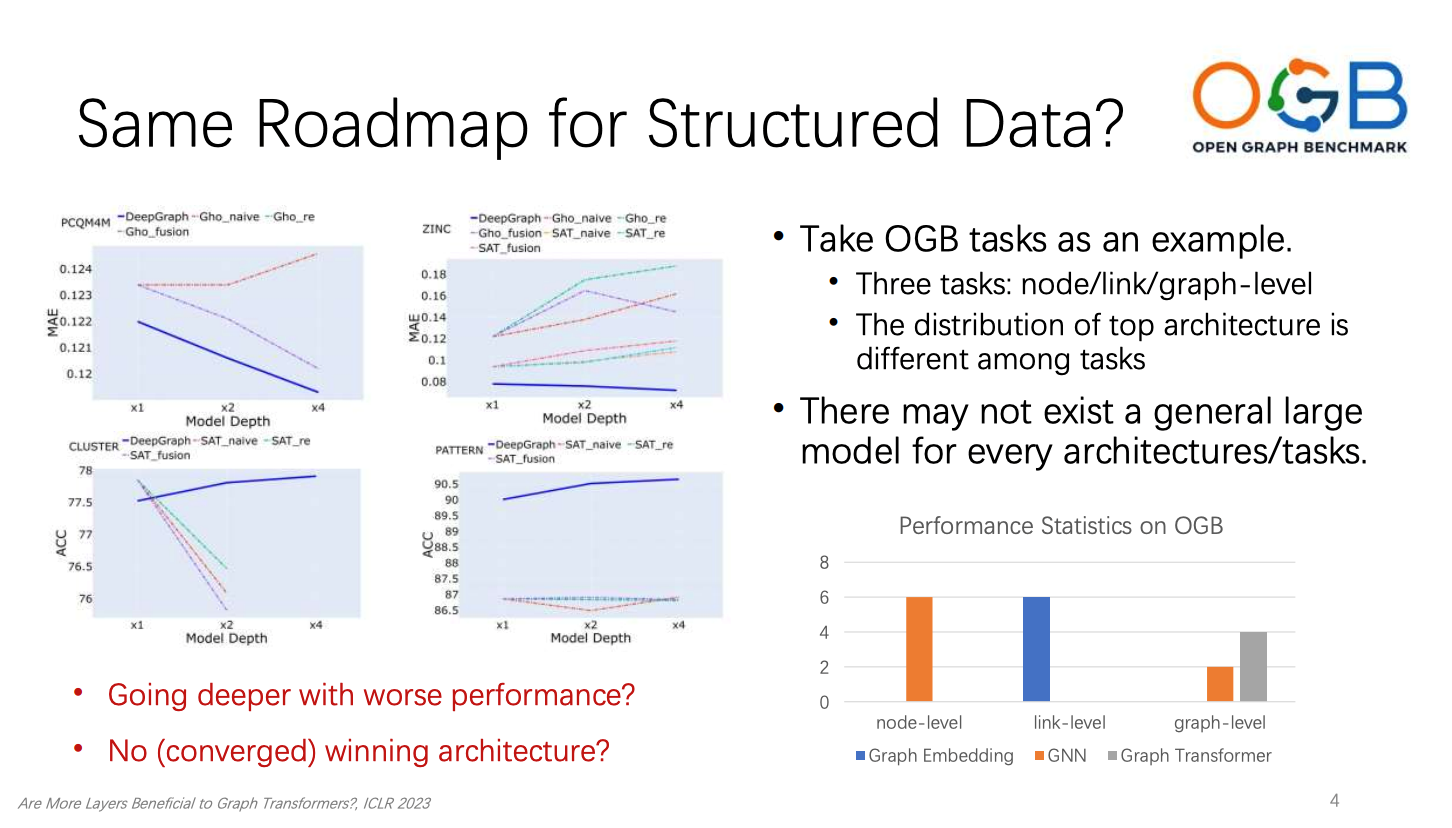
对此,姚权铭博士介绍了现阶段所要面临的两个瓶颈。首先介绍了预训练任务中的瓶颈。在结构化数据预训练中有两个问题值得探讨。第一,是否有一种数据集能像自然语言处理一样适用于各种下游任务。例如我们是否可以只需要使用社交网络或者分子网络便能完成结构化数据学习的预训练,并且预训练后的模型是否在下游的各种任务中也能有很好的表现?第二,自然语言处理利用其数据内部的顺序相似性发展出了多种预训练方法,而结构化数据内部是否也存在一种通用的性质来支撑结构化数据的预训练任务?自然语言的各种预训练方法是否适用于结构化数据学习?

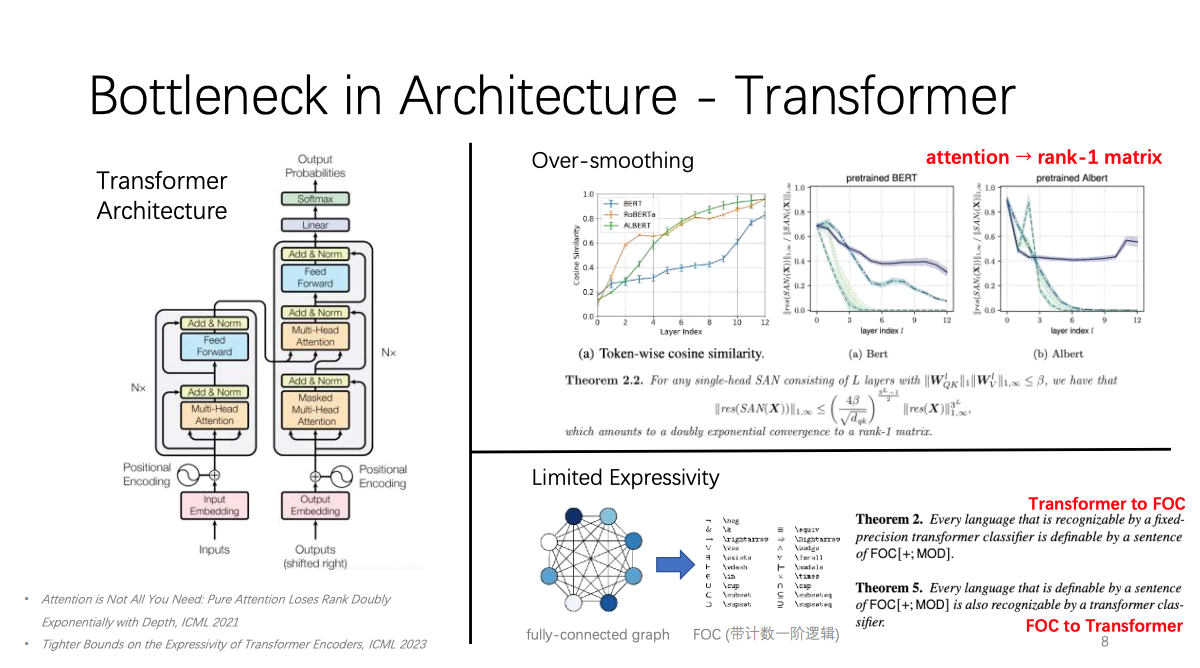
其次,姚权铭博士介绍了现有模型在结构化数据处理上表达能力有限的瓶颈。GNN的聚合操作会导致信息的压缩和损失,降低了模型的表达能力和逻辑推理能力。Graph Transformer的注意力机制会导致信息的平滑和冗余,降低了模型的秩和复杂度。
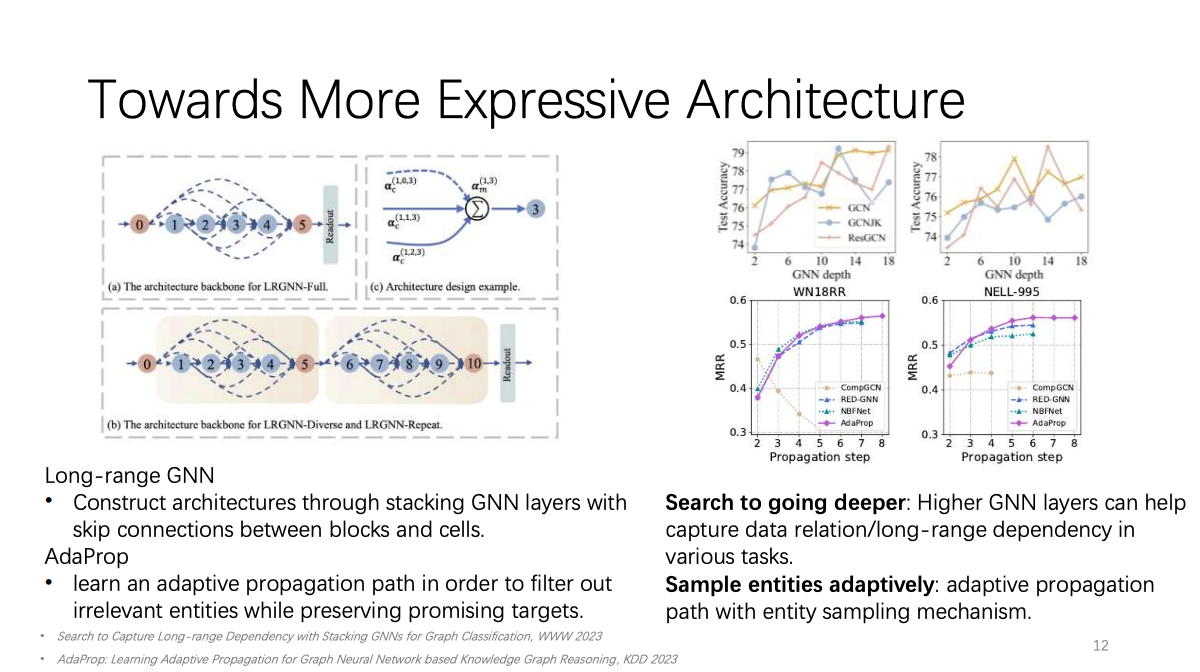
为此,姚权铭博士进行了三种尝试。第一个是尝试提升模型的表达能力。这其中有两项目标,第一,通过子图传播以提高表达能力。第二,寻找能够随深度的增加,性能会提升的架构。姚权铭博士首先通过在块和单元之间堆叠GNN层并添加跳跃连接构建架构,更多的GNN层可以帮助捕捉各种任务中的数据关系和长程信息依赖关系。其次,通过学习自适应传播路径,以便在保留有希望的目标的同时过滤掉无关的实体。
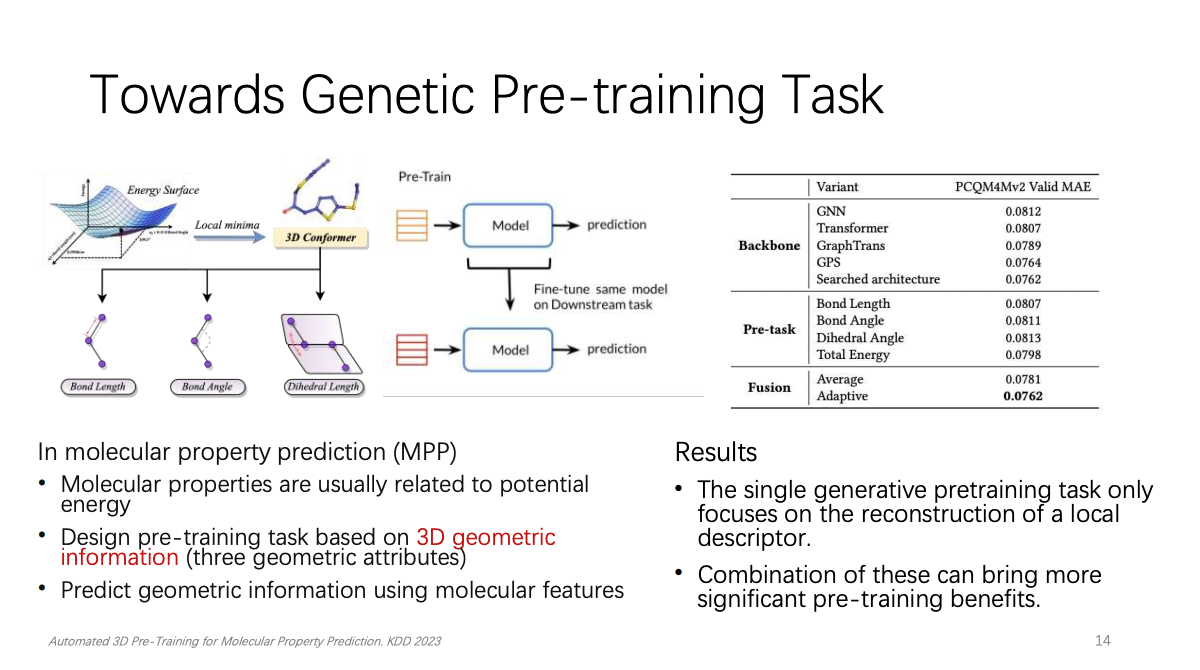
第二就是尝试寻找一个更加普适预训练任务。这其中也有两项目标,第一,在具有领域特定先验知识的情况下,探索一组预训练任务。第二,可以通过超参数优化使它们变得自适应。姚权铭博士以分子性质预测为例讲了如何利用领域相关的先验知识来设计图结构数据的预训练学习任务。姚权铭博士利用分子特征来预测几何信息,从而学习分子的潜在能量和结构。经过实验,并不是预训练数据量越多效果就会越好,这可能与transformer自身表达能力有限有关系。在8个下游任务中,有6个是随着预训练数据的数量增多,微调的效果越好。但是有两个任务的表现会出现明显的先上升后下降的趋势。
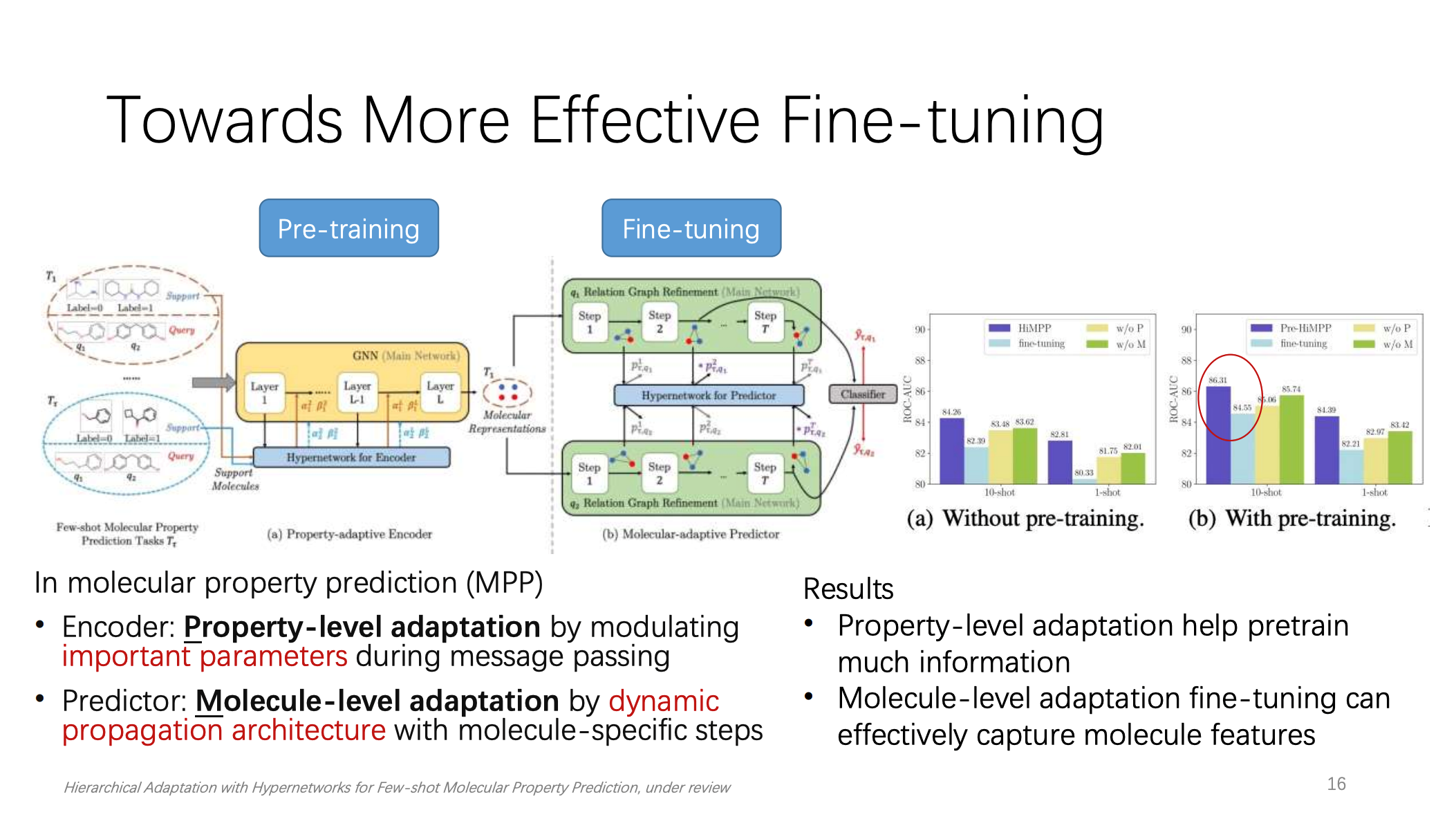
第三个尝试有效利用来自下游任务的少量样本进行微调。同样包含了两项目标,第一,动态地选择可以更新的预训练参数。第二,构建自适应预训练的结构。姚权铭博士依然以分子性质预测为例。可以根据参数的重要性和敏感性来选择性地更新预训练模型的部分参数,从而保留预训练模型的泛化能力。同时,可以利用一个辅助网络来动态生成预训练模型的参数,从而实现更灵活和更高效的微调。这样就可以从属性层面和分子层面实现自适应。结果表明,属性层面的自适应调整可以学习到更多的信息。分子层面的自适应微调可以有效捕获分子的特征。
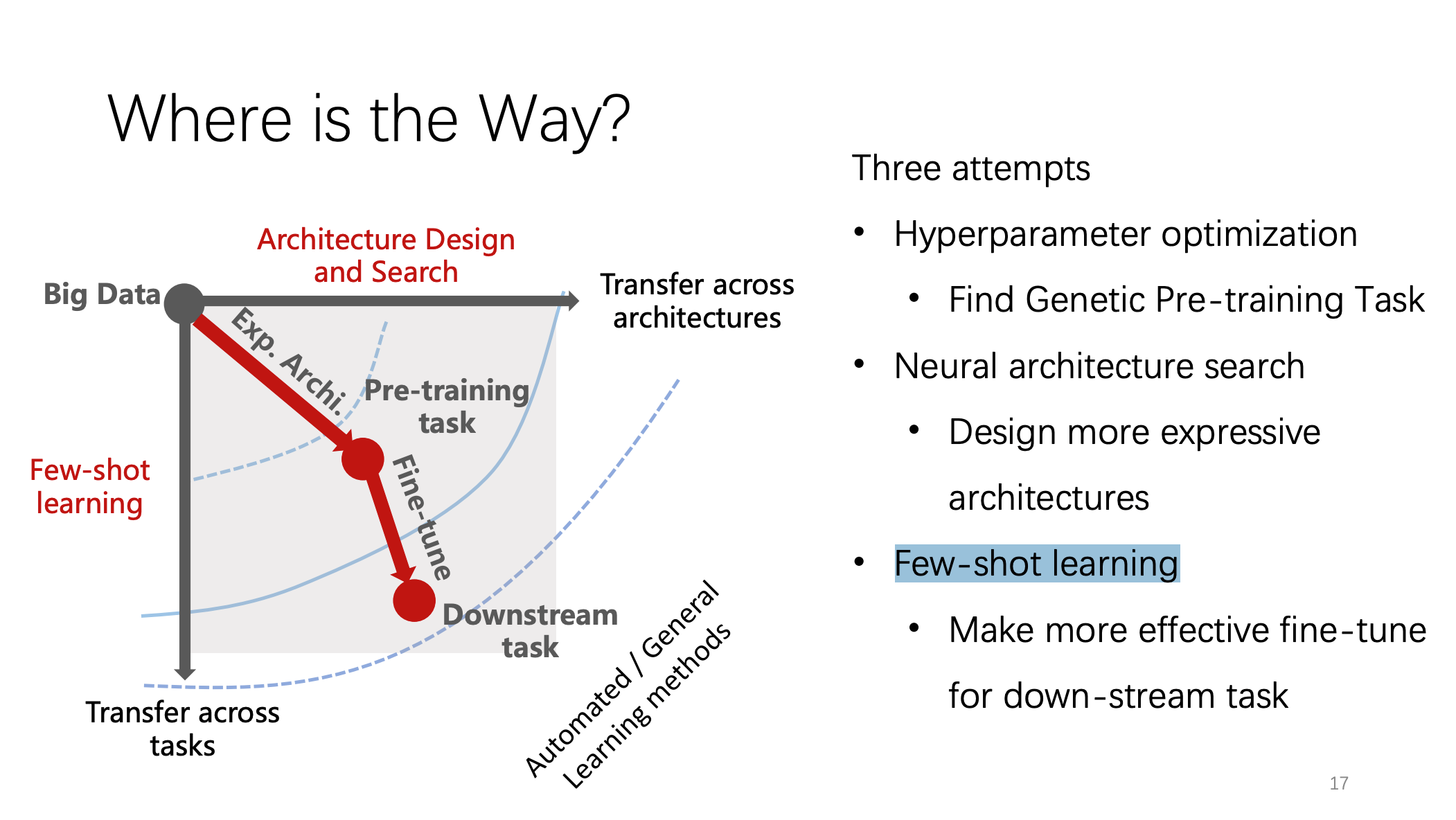
在演讲的最后,姚权铭博士总结了他探索结构化数据从预训练到微调的技术路线图的三个尝试:寻找出更普适的预训练任务以适应更多的下游任务;设计出更有表达能力的网络架构;探索微调方法,使下游任务的微调更加有效。演讲结束后,姚权铭博士与参会的博士和同学们对报告中的技术细节和领域前沿进展进行了热烈的讨论。
文稿撰写 / 刘冠洲
排版编辑 / 王影飘






