7月6日晚,由DISCOVER实验室主办的第22期AIR青年科学家论坛如期举行。本活动有幸邀请到了北京大学前沿计算研究中心助理教授董豪,为AIR的老师和同学们做了题为《Towards Unified Robotics Manipulation via Object-centric Policy》的精彩报告。


董豪,北京大学前沿计算研究中心助理教授。他的研究重点包括可泛化的机械臂操作、机器人视觉和移动设备自主决策等方面。董豪博士在NeurIPS、ICLR、CVPR、ICCV、ECCV、ICRA、IROS等国际顶尖会议/期刊上发表论文40余篇,Google Scholar引用4000余次,多次担任国际顶尖会议领域主席。其领导了多个开源项目,例如TensorLayer和OpenMLsys,在ACM Multimedia 2017获得了最佳开源软件奖,并在2021年和2022年获得了OpenI杰出项目奖。
在报告中,董豪博士首先介绍了具身智能(Embodied Intelligence)这样一个宽泛的问题背景。为了让机器人帮助人类完成各种各样的任务,具身智能包含了操纵、导航、感知、协同等多种任务。而在这些任务之中,操纵(Manipulation)则是机器人与物体进行交互所需的最基本能力。

董豪博士首先给出了机器人操纵任务的基本定义,即学习一个策略π,根据观测X和机器人状态S,输出机器人的动作Y,从而通过π(X, S)→Y的映射关系控制机器人的关节移动,执行相应的交互任务。董豪博士指出,这样一个问题的较为复杂,环境中物体本身的几何、纹理和可交互的模式各异,机器人状态复杂,而机器人的动作指令也丰富多样。这样的组合关系使得通用的AI策略π很难学到。
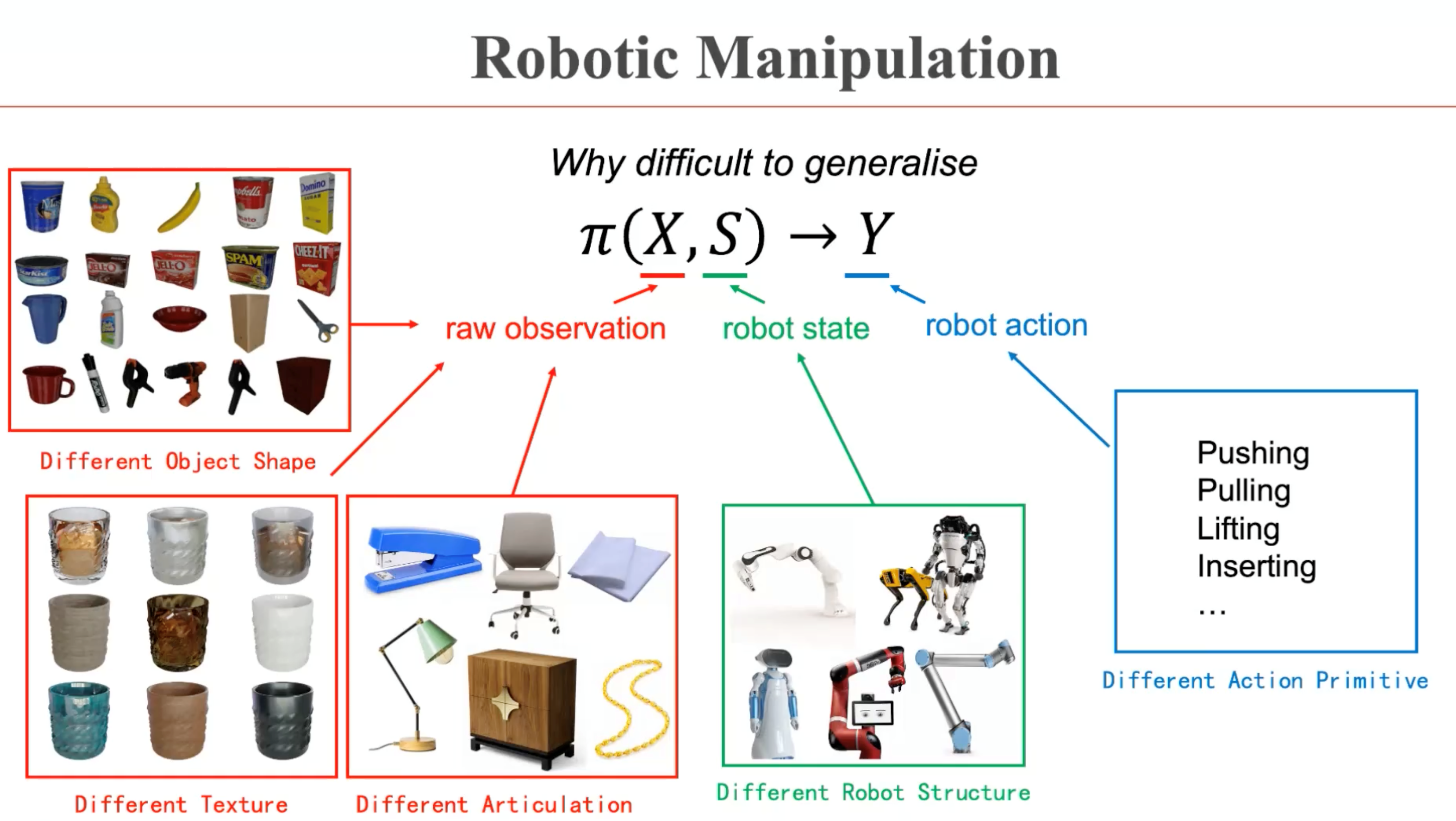
由此,董豪博士考虑的是一种以物体为中心的策略(object-centric policy),即考虑与机器人状态无关的策略π(X)→Y,来降低问题的复杂度。针对这样一种策略,董豪博士介绍了本框架的核心思想,即找到物体中哪些地方可以被交互,并推断出可被交互的位置的活动轨迹,由此获得以物体为中心的通用策略表达。
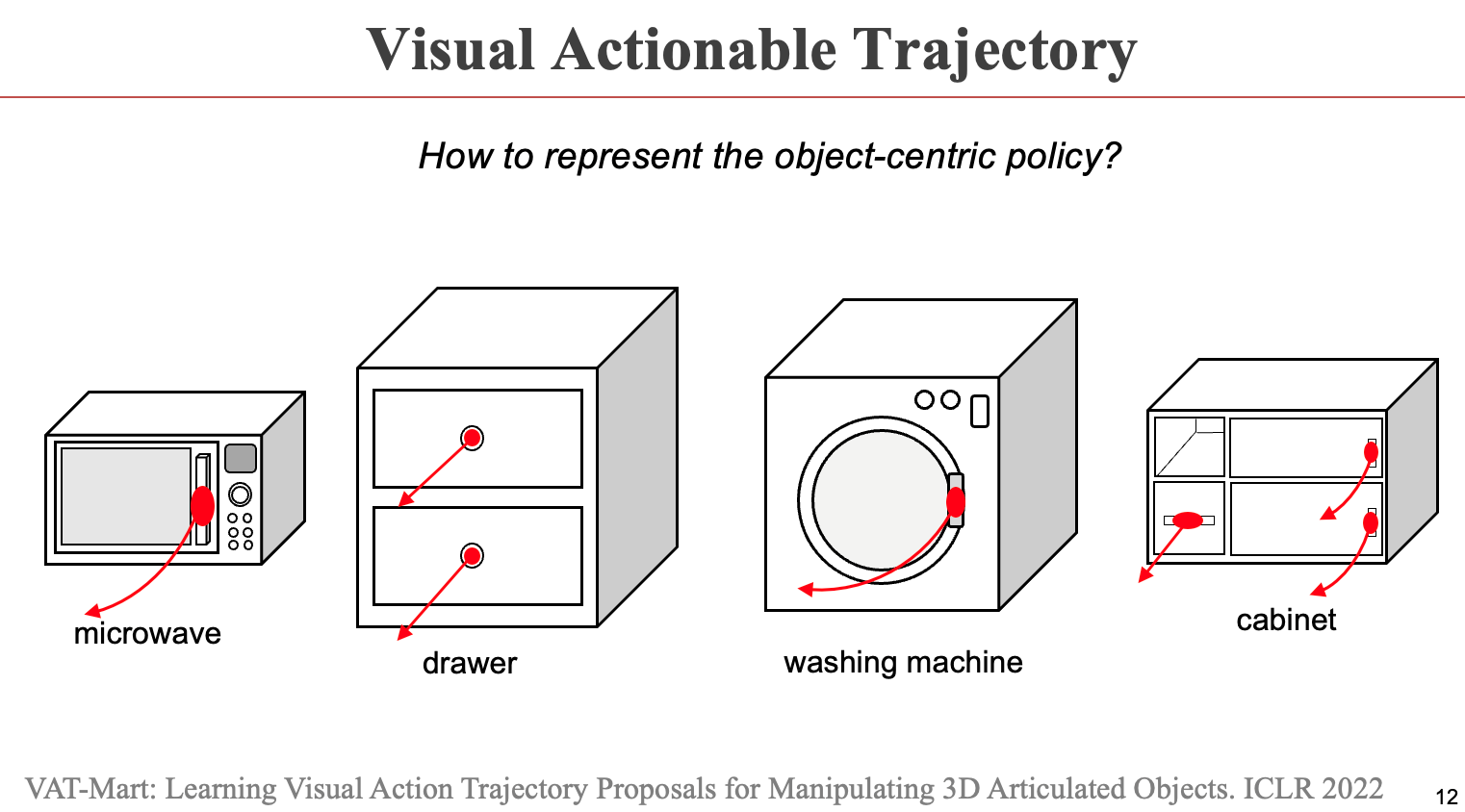
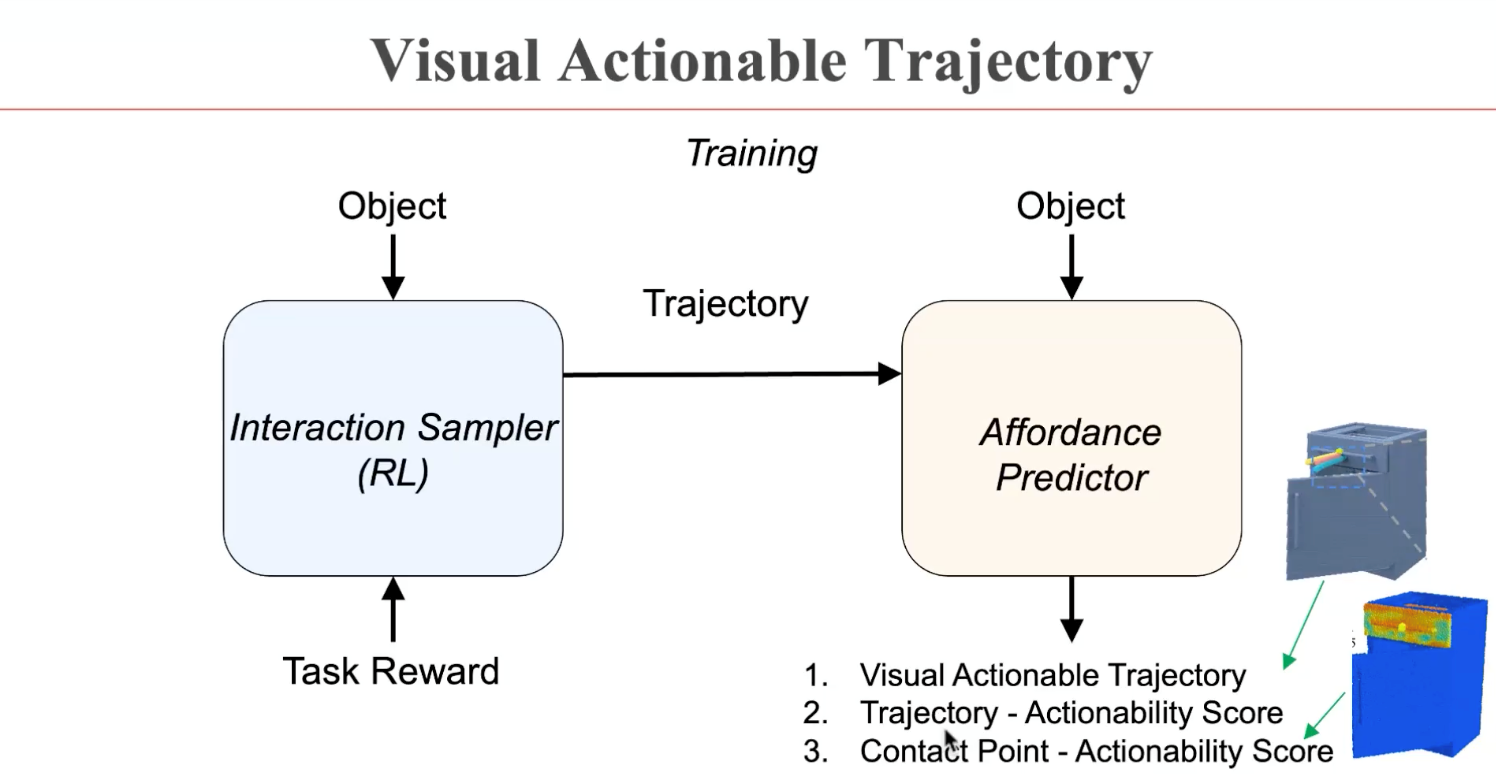
董豪博士首先介绍了课题组在ICLR 2022发表的工作VAT-Mart。这个工作提出了visual actionable trajectory的表征来学习物体操纵的策略表达。而在学习过程中,获取物体每个可交互点的运动轨迹有无限可能,因此人工标注十分困难。针对这样一个难点,可通过一个强化学习模块在虚拟环境中自动生成训练数据,再为预测模块提供监督信号,学习不同物体的可交互位置和运动轨迹。
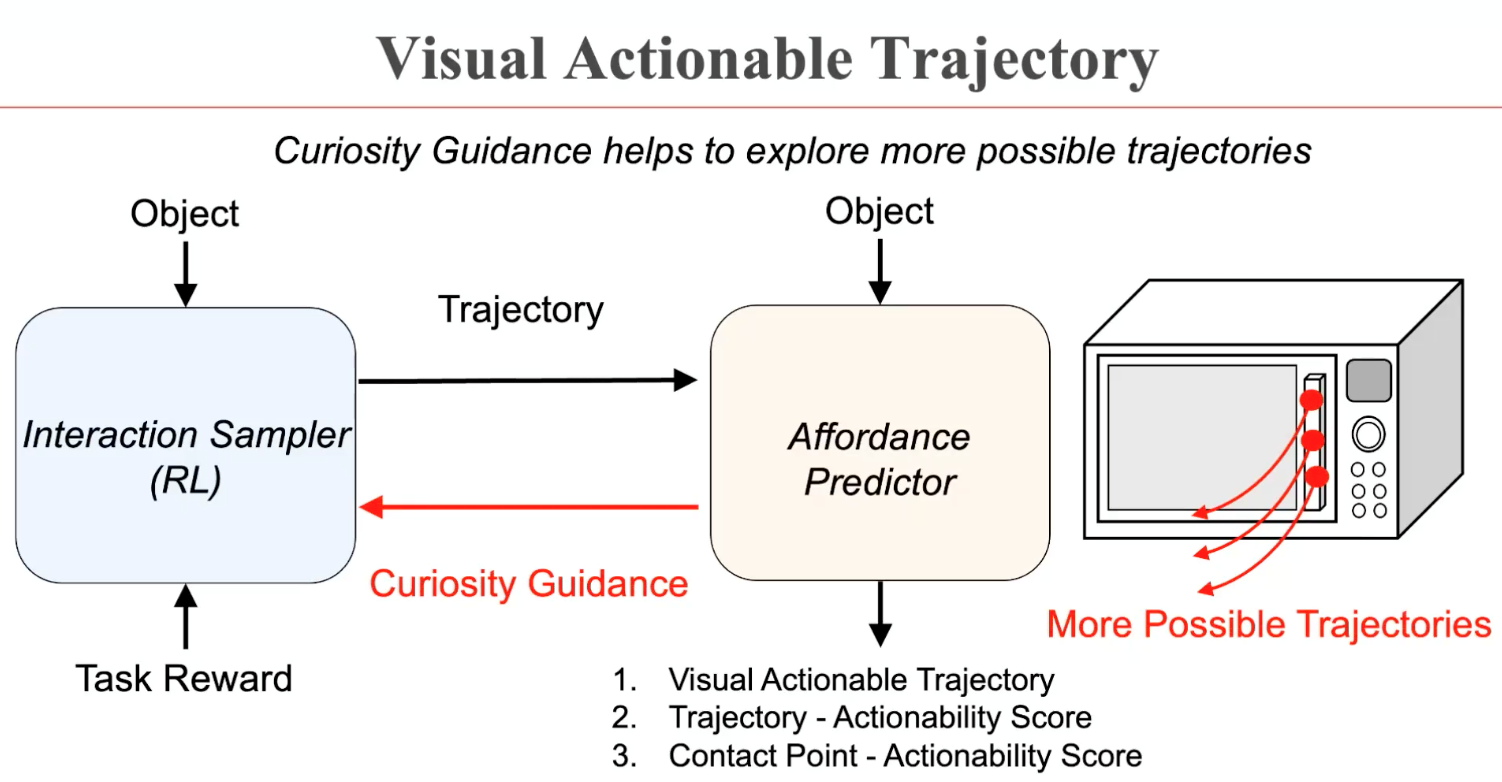
董豪博士指出,在强化学习的训练过程中,预测模块可能倾向于选择同一个位置进行交互。因此,6在设计中额外引入了好奇心机制,从而驱动预测模块学到机器人对物体进行操纵的全解。

这样一种学到的策略可以在与训练集相似的物品上进行较好的操纵。而针对更加通用、统一的机器人操纵算法的探究过程中,董豪博士的团队发现了两个问题,衍生出了AdaAfford(ECCV 2022)和DualAfford(ICLR 2023)两个后续工作的改进。首先,生活中的一些物体并不能简单地通过视觉信息知道它该如何进行操纵,而是存在歧义。比如如下图所示的门把手可能需要朝左侧拉拽,也可能朝右侧拉拽。这样的操纵方式需要具体进行交互尝试才能够明确。
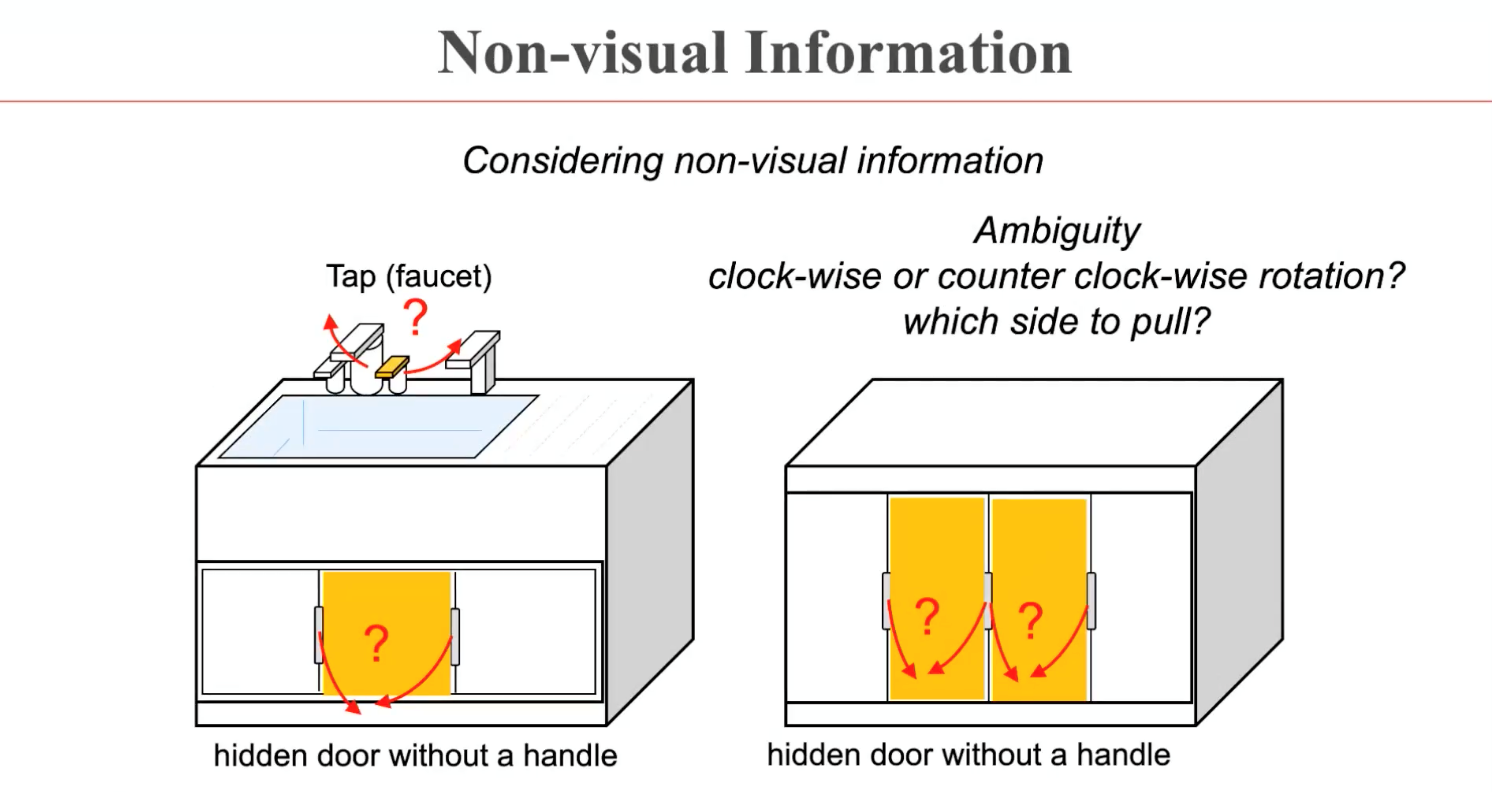
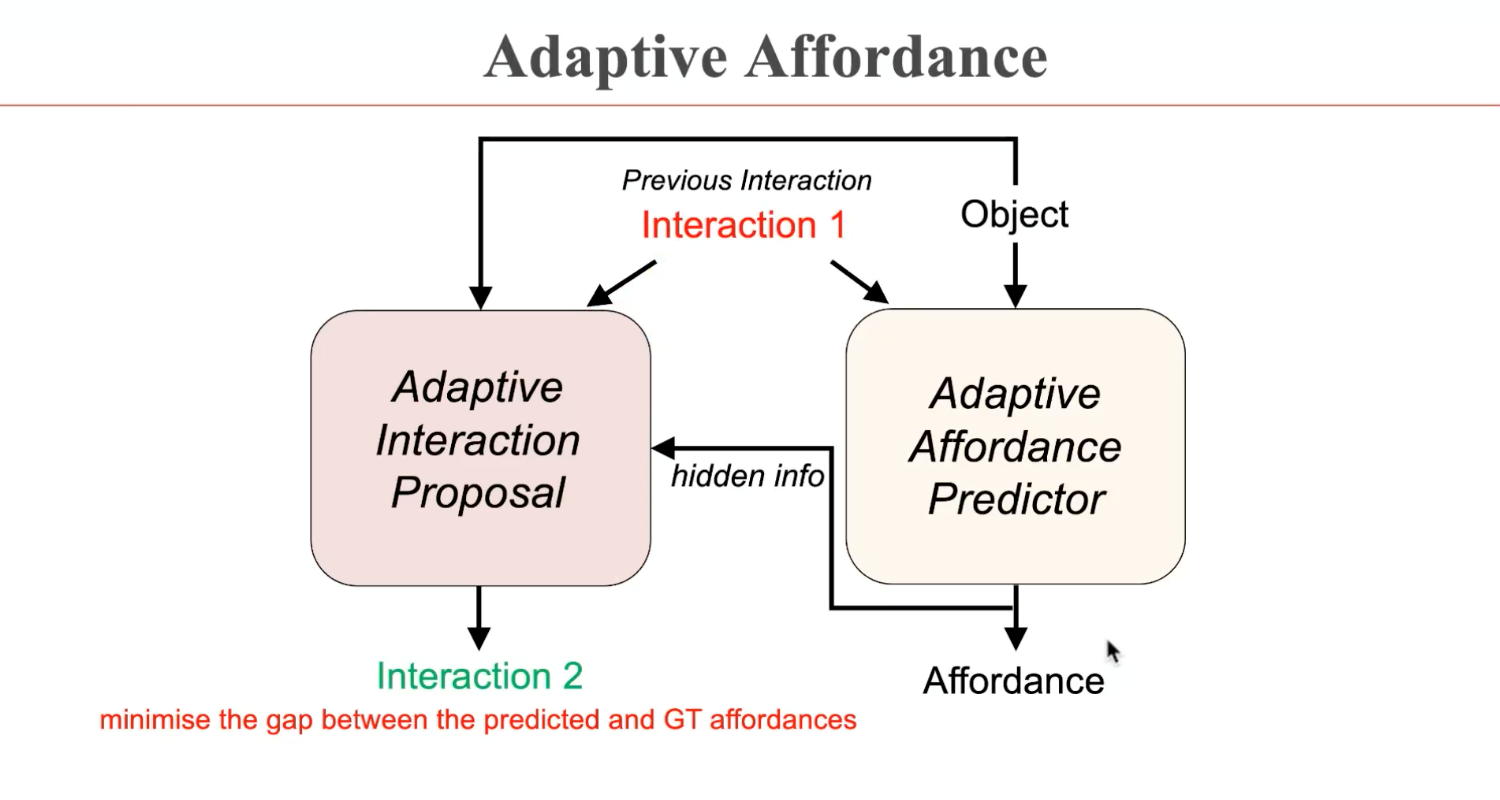
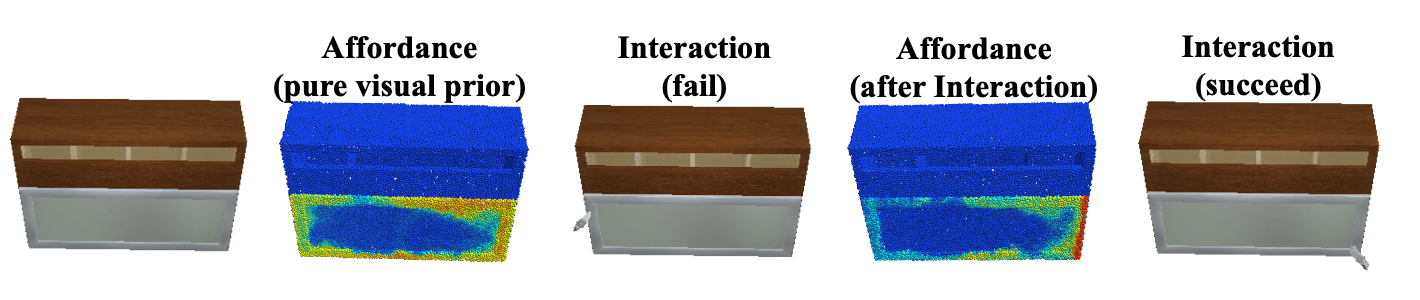
由此,在AdaAfford这篇工作中,机器人将先根据预测模块的交互位置进行操纵,如果第一次交互并不成功,预测模块会更新交互位置和交互方式,进行下一次尝试,直至成功。这样,操纵的策略可以通过交互的成功与否进行更新,而不再依赖于视觉信息。
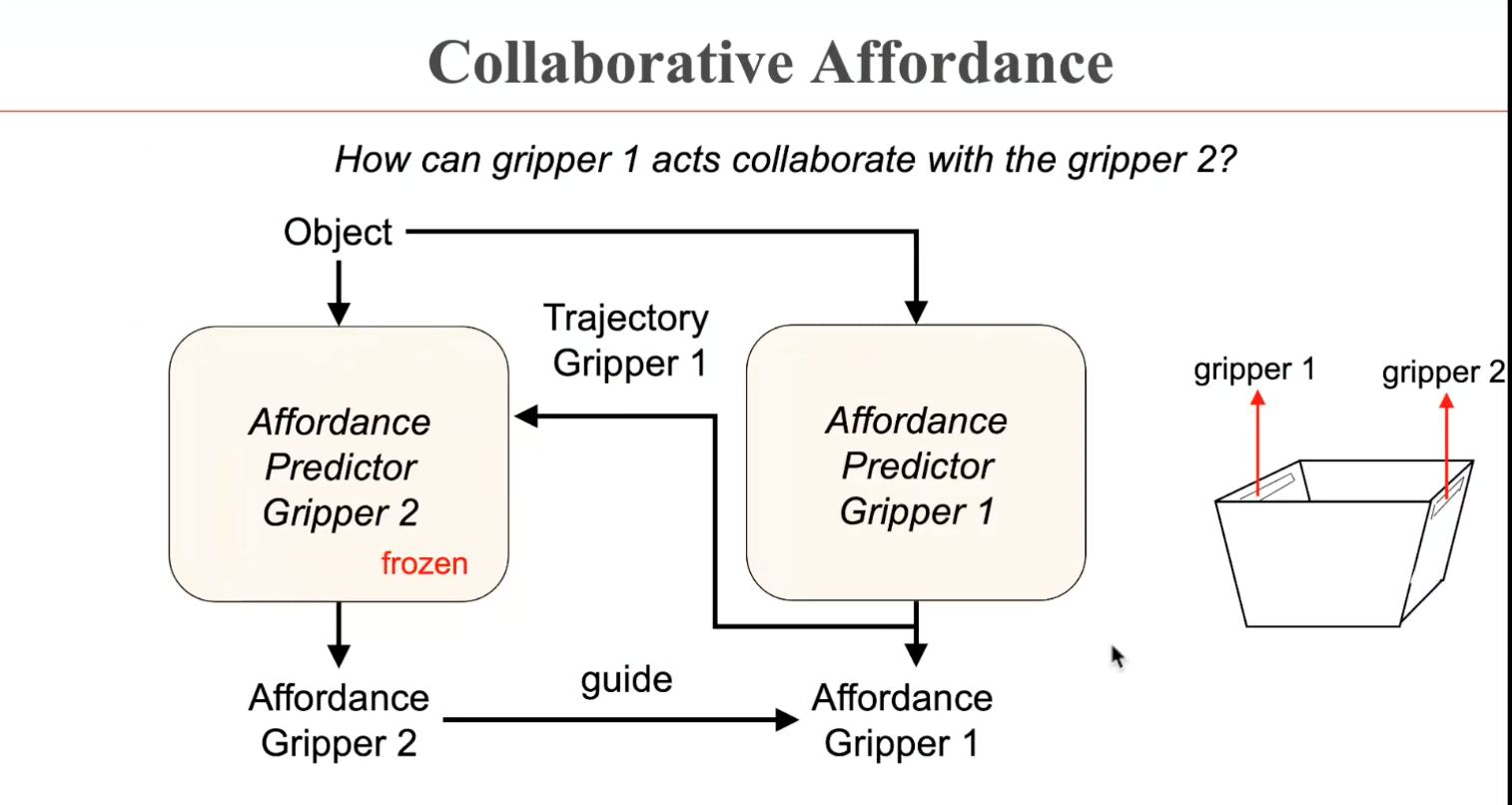
此外,董豪博士的团队还发现,很多物体在实际生活中无法仅通过一次交互进行操纵,而需要多次协同交互完成。而这样一个问题的动作输出复杂度极高,导致训练效率不佳。在DualAfford工作中,协同操纵的任务被解耦成多个串行任务,使得问题的复杂度极大降低。
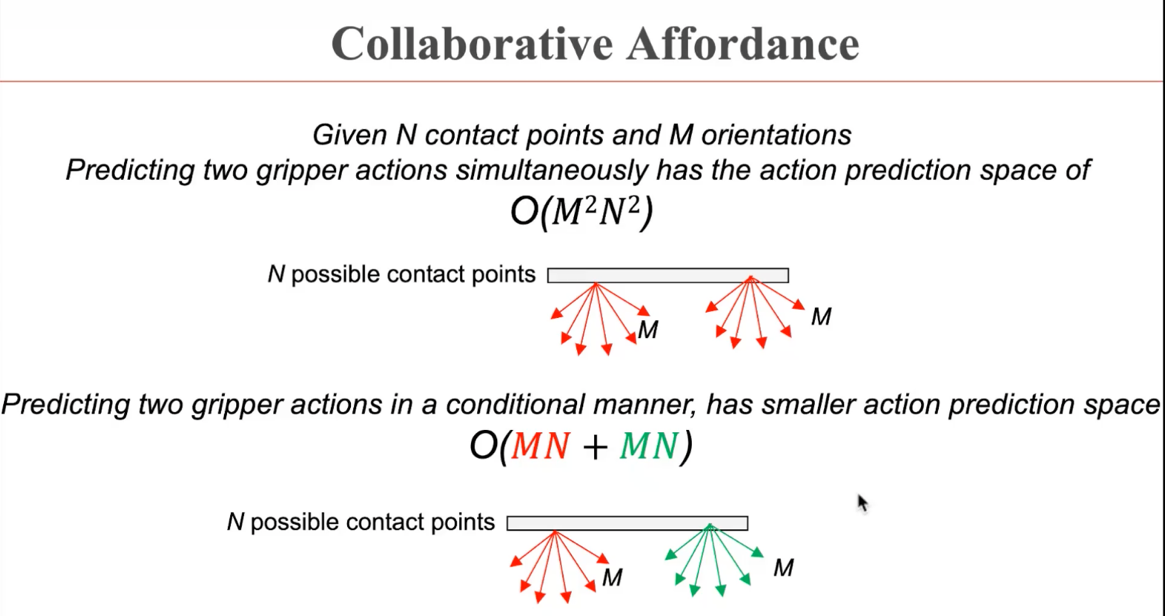
与前述工作的学习策略类似,两次操纵的串行任务将交替进行训练,得到物体的交互位置和交互轨迹,并假设另一次任务的操纵策略已知。
这样一种以点为表达的affordance-trajectory的表达对物体的形状具有很好的泛化性。然而,现有的学习策略对于不同的动作需要学习不同的交互位置,而实际上,交互位置具有更强的一致性。不同的动作或许在同样的交互位置发生操纵。
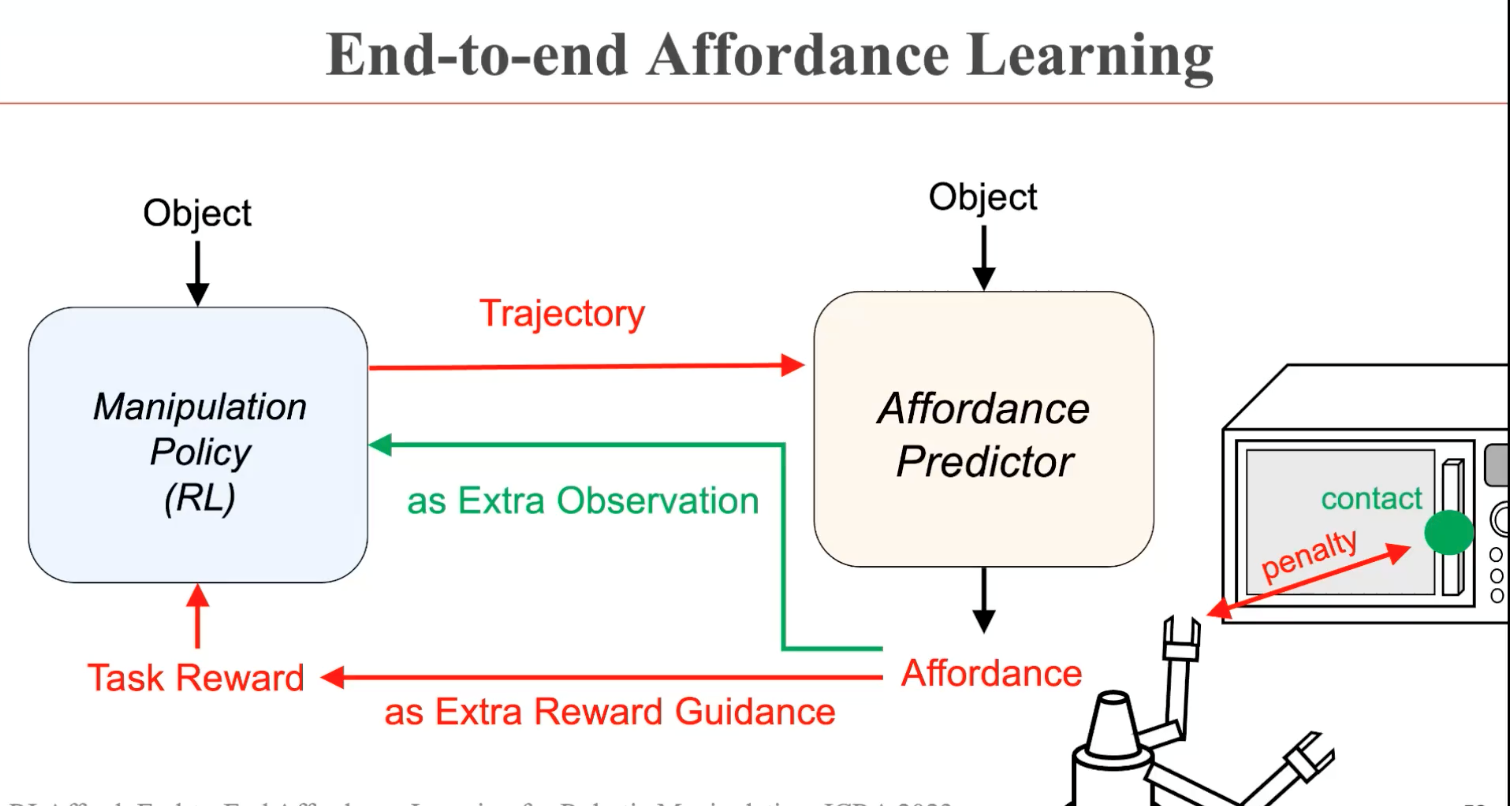
在董豪博士团队的RLAfford(ICRA 2023)工作中,抓取位置被作为额外的输入给到强化学习模块。通过感知和决策的联合学习,不同动作的交互位置被有效地统一起来。这样一个简单的改动有效地提升了机器人的操纵性能。

在报告的最后,董豪博士展望了机器人操纵在工作性能和交互能力上的未来探索方向,并回顾了课题组在机器人无关策略学习(robot-agnostic policy)的其它研究进展。报告结束后,董豪博士与参会的老师和同学们对报告中的技术细节和领域前沿进展进行了热烈的讨论。

AIR长期招聘人工智能领域优秀科研人员






