清华大学万国数据教授、智能产业研究院(AIR)执行院长刘洋教授课题组在基于知识迁移的增量学习方面取得新进展,相关研究成果“基于知识迁移的多语言神经机器翻译增量学习方法”(英文名称Knowledge Transfer in Incremental Learning for Multilingual Neural Machine Translation)于北京时间2023年7月11日获得人工智能领域重要国际会议ACL 2023颁发的杰出论文奖(Outstanding Paper Award)。该论文由AIR与清华大学计算机系、北京信息科学与技术国家研究中心、上海人工智能实验室、腾讯、中国科技大学等单位共同完成。ACL全称是Annual Meeting of the Association for Computational Linguistics,由计算语言学协会主办,Google Scholar h5-index为169,是自然语言处理领域最具影响力的国际学术会议。ACL 2023共收到约5000篇投稿,除了传统的最佳论文奖、杰出论文奖和系统展示奖,今年增设了特别奖、领域主席奖、学生研讨会奖、荣誉提名等奖项。
多语言神经机器翻译旨在利用多语平行语料,在单个模型内实现多种语言之间的互译。在实际应用中,可用的平行数据和支持的语种随着时间的推移逐渐增多,因此翻译系统需要及时更新以应对复杂的场景需求。然而,由于多语言神经机器翻译模型的原始训练数据通常规模庞大,使用原始数据和新数据混合训练的方法既耗时又繁琐。因此,更为高效的做法是:这些模型无需访问以前的训练数据,就可以快速实现语种和数据的增配。然而,面向大规模模型的增量学习是具有挑战性的,主要存在以下两个方面的问题:首先,如何使原始模型能够更好地适应新的数据,避免跨语言表示差异。其次,在学习新的知识时,如何避免遗忘旧的知识,即灾难性遗忘问题。
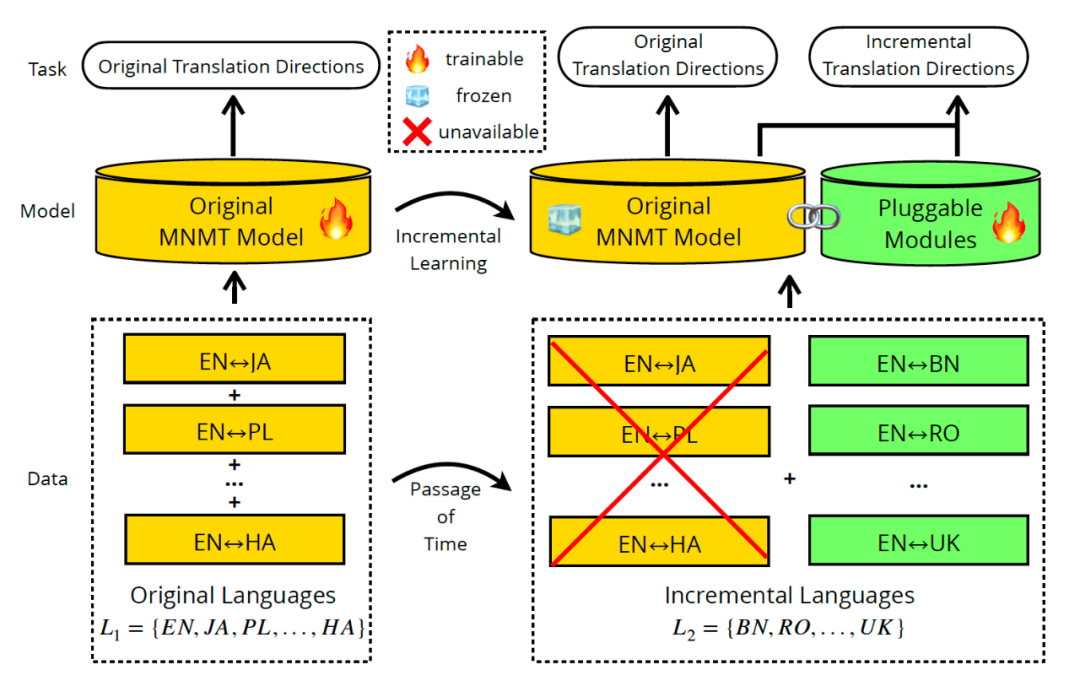
论文提出了一种基于知识迁移的增量学习方法(Knowledge Transfer, 简称KT),该方法从独立训练的网络中提取对适配新语种有益的两种类型连续型知识库,把该知识库作为可插拔模块,以插件的形式增配到原有模型中来弥合跨语言表示差距。对比随机初始化产生的可插拔模块,KT缓解了可插拔模块捕捉跨语言之间共享语言特征的能力较弱的问题,同时降低训练阶段学习新语言对的成本。此外,KT采用了冻结原始模型参数的策略,在增量学习过程中消除对原始模型的影响,完全避免灾难性遗忘问题。在有监督增量学习任务上,KT在新增翻译方向的性能超过了多个强基线方法,并且没有损失原始翻译方向的性能。在Zero-Shot翻译方向上,KT增配后的新旧语种间互译BLEU值比标准参数高效化方法提升平均4.58。论文工作为大规模语言模型适配新语种提供了新的解决方案。
黄锴宇,论文第一作者,清华大学智能产业研究院(
AIR
)博士后,合作导师是刘洋教授。
研究兴趣为预训练模型、多语言处理、机器翻译。
曾在国际顶级会议和国内外核心期刊
(ACL/KDD/EMNLP/IJCAI/CIKM
等
)
发表论文
30
余篇。
在
ACL 2023
获得杰出论文奖。
个人主页:https://koukaiu.github.io/
李鹏,论文共同通讯作者,清华大学智能产业研究院(
AIR
)副研究员
/
副教授,研究兴趣包括自然语言处理、预训练模型、跨模态信息处理等,在人工智能重要国际会议与期刊发表论文
80
余篇,获得
ACL 2023
杰出论文奖。
个人主页:https://www.lpeng.net
刘洋,论文共同通讯作者,清华大学万国数据教授、智能产业研究院(AIR)执行院长、计算机科学与技术系副系主任、人工智能研究院副院长,国家杰出青年基金获得者。研究方向为人工智能、自然语言处理、智慧医疗。
个人主页:http://nlp.csai.tsinghua.edu.cn/~ly/
关注AIR公众号并回复“AIR ACL 2023“下载完整论文



