可信机器学习最本质的问题可以归结为对“分布漂流“(distribution drift)及“分布迁移“(distribution shift)的分析。绝大多数的可信机器学习问题都可以归结到分布漂流中去。
——李博
2月23日上午,第16期AIR学术沙龙在线上如期举行。本期活动荣幸地邀请到了伊利诺伊大学厄巴纳-香槟分校计算机科学系李博教授为我们线上作题为《可信机器学习: 机器学习鲁棒性、隐私性、泛化性、及其内在关联》的报告。

本次活动由清华大学智能产业研究院(AIR)副教授刘洋主持,AIR官方视频号和b站同步直播,当日线上逾1700次观看,目前共计触达人数近3000人。
李博教授现任职于伊利诺伊大学厄巴纳-香槟分校计算机科学系。她曾荣获许多学术奖项,包括麻省理工学院技术评论 MIT TR-35 、Alfred P. Sloan 斯隆研究奖、NSF CAREER 奖,英特尔新星奖、赛门铁克研究实验室奖学金,并获得来自Amazon、Facebook、谷歌、英特尔和 IBM 等科技公司的学术研究奖。她的论文曾获多个顶级机器学习和安全会议的最佳论文奖;研究成果还被永久收藏于英国科技博物馆。李博的研究侧重于可信机器学习、计算机安全、机器学习、隐私和博弈论的理论研究和实践分析。她曾设计多个鲁棒性机器学习算法及和隐私保护数据发布系统。她的工作曾被《自然》、《连线》、《财富》和《纽约时报》等主要媒体报道。
报告内容
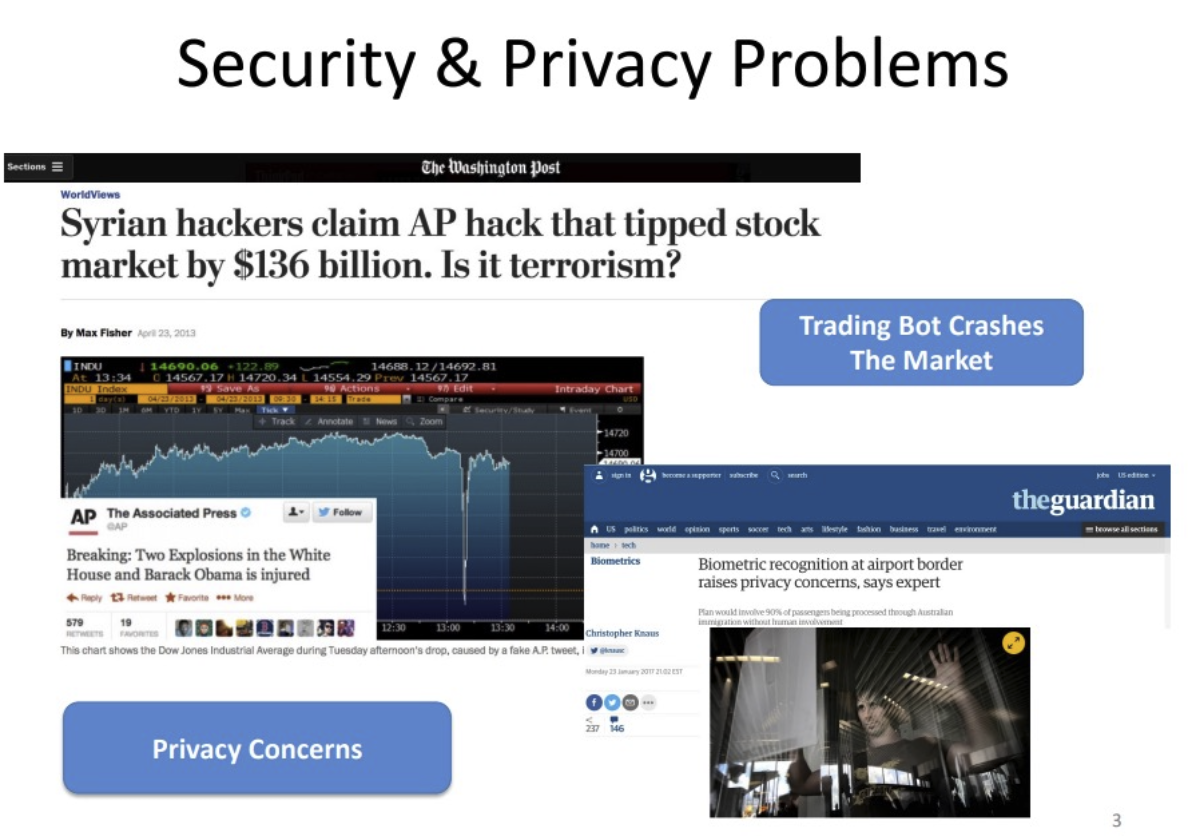
近年来,机器学习在真实世界诸多方面都有着广泛的应用,例如,自动驾驶,健康医疗,智慧城市等。虽然机器学习和人工智能强大且便捷,但是真实世界中机器学习的安全与隐私所涉及到的问题依然引起了人们的担忧。就在2016年,推特由于遭到黑客攻击释放出了白宫遇袭的消息。这些对公众来说显而易见的假消息,却使得基于机器学习的算法做出了错误的决策,在短短的几秒钟内交易了1360亿美金的股票。除此之外,澳大利亚的航空公司也开始使用人体的生物信息来进行身份识别,同样引发了公众对隐私泄露的担忧。基于机器学习隐私和安全等方面的可信机器学习的研究已经成为一个重要的课题。
李博教授团队以研究在真实世界可应用的可验证的鲁棒性(Certified Robustness),隐私以及可解释机器学习为主,以应对可能出现在机器学习流程中各个方面的攻击。
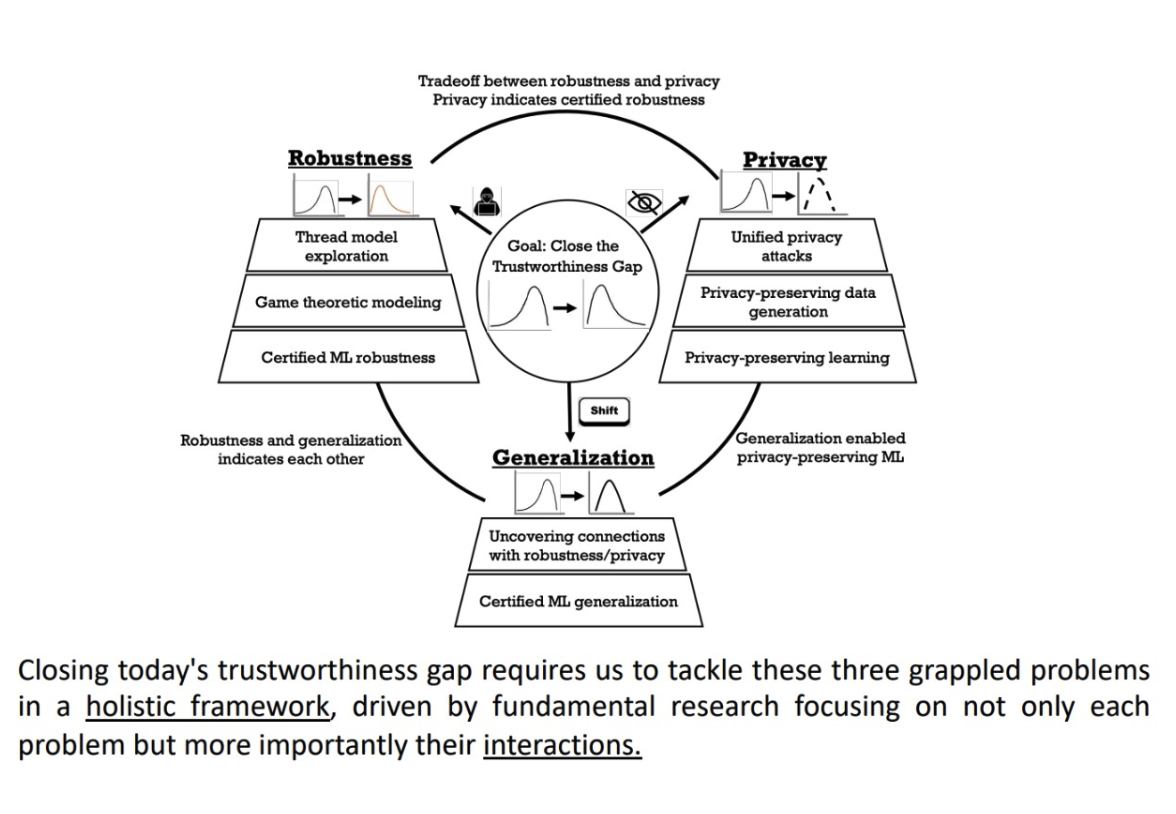
可信机器学习最本质的问题可以归结为“分布漂流”(distribution drift)以及对“分布迁移”(distribution shift)的分析。绝大多数的可信机器学习问题都可以归结到分布漂流中去。
鲁棒性便是研究在训练或测试阶段可能出现的微小的恶意分布漂流。这些微小的分布漂流极有可能是恶意方精心设计来达到某些目的,比如,恶意方的中毒攻击(Poisoning attack)和后门攻击(Backdoor attack)是在训练数据集上的分布漂流;恶意方的对抗攻击(Adversarial attack)是在测试数据中的分布漂流。对于分布漂流的深度研究有助于防御方在攻防游戏中获胜,甚至提供可验证的鲁棒性以研究模型对于不同的分布漂流表现的下界。
隐私性的研究是根据已知部分的分布信息来推断出未知部分的分布信息,包括数据的统计信息,甚至恢复出数据本身。隐私性的研究可以大概分成两个大方向,第一个是高隐私性数据的生成,第二个是高隐私性算法的设计。相较而言,高隐私性数据的生成更具有普适性但是也更有挑战性。高隐私性算法的设计可以弥补前者的空缺,在学习的过程中为模型提供隐私保护。 隐私性在一定程度上能够推导出可验证鲁棒性,对有一个符合差分隐私的模型,其可验证鲁棒性可以表示为一个差分隐私的函数。
第三个主要的问题是模型的泛化性。泛化性本身就是在研究在自然环境中分布漂流的问题,在真实世界里,数据分布随时随地都在发生变化。所以在静止的数据集上训练出来的模型如何能在时刻变化的真实世界数据分布上表现出较高的泛化性是一个重要的问题。
这三者之间相互关联,比如对于一个完美泛化性的模型,其鲁棒性一定是能得到保证的,但是完美泛化性的模型往往是难以得到的。
可验证鲁棒性
在真实世界中,大量研究表明攻击者可以轻易干扰自动驾驶的相机或雷达以降低自动驾驶系统对于路边标识牌或路边物体的识别。比如一些轻微的扰动就会使机器学习模型把“停止”标识预测成“限速45”,进而加大了自动驾驶的危险性。目前相当一部分自动驾驶公司,已经开始对相关攻防展开分析。同时,研究者也提出了对于攻击的防御手段,但是新提出的防御手段同样面临被新攻击方法干扰的风险。而可验证鲁棒性意在解决无休止的攻防循环。

直观来讲,可验证机器学习是为算法提供预测准确率的下界,即在攻击者满足一定限制的前提下,不管使用什么攻击方法,模型的预测精度都不会低于此下界。
目前的可验证鲁棒性基本可以分为两大类,一类是完全可验证(Complete),另一类是不完全可验证(Incomplete)。完全可验证的方法提供了充要条件,即如果方法可以对目标模型能提供可验证鲁棒性,则可验证鲁棒性存在,反之则不存在。不完全可验证的可验证鲁棒性方法提供了充分条件,即如果方法可以对目标模型能提供可验证鲁棒性,则可验证鲁棒性存在,反之可验证鲁棒性亦可能存在。其中,只有不完全可验证方法中基于概率的方法可以被应用于大规模数据训练模型。

目前可验证鲁棒性研究当中,实验可验证鲁棒性(empirical)和理论可验证鲁棒性(theoretical)存在较大落差。目前的一些攻击方法,虽然对机器学习模型十分有效,但是我们却可以轻易区分。所以如何把一些外部知识交给机器学习模型来帮助其提高防御能力成为一个有前景的研究方向。
李博教授团队提出感知-推理机器学习(Sensing-Reasoning ML Pipeline), 是一种端到端的机器学习流程,可以通过基于知识库的逻辑推理来提升网络的可验证鲁棒性。其中深度神经网络作为感知的部分来提取特征,之后经由推理网络整合特征之间的逻辑来达到最终预测。
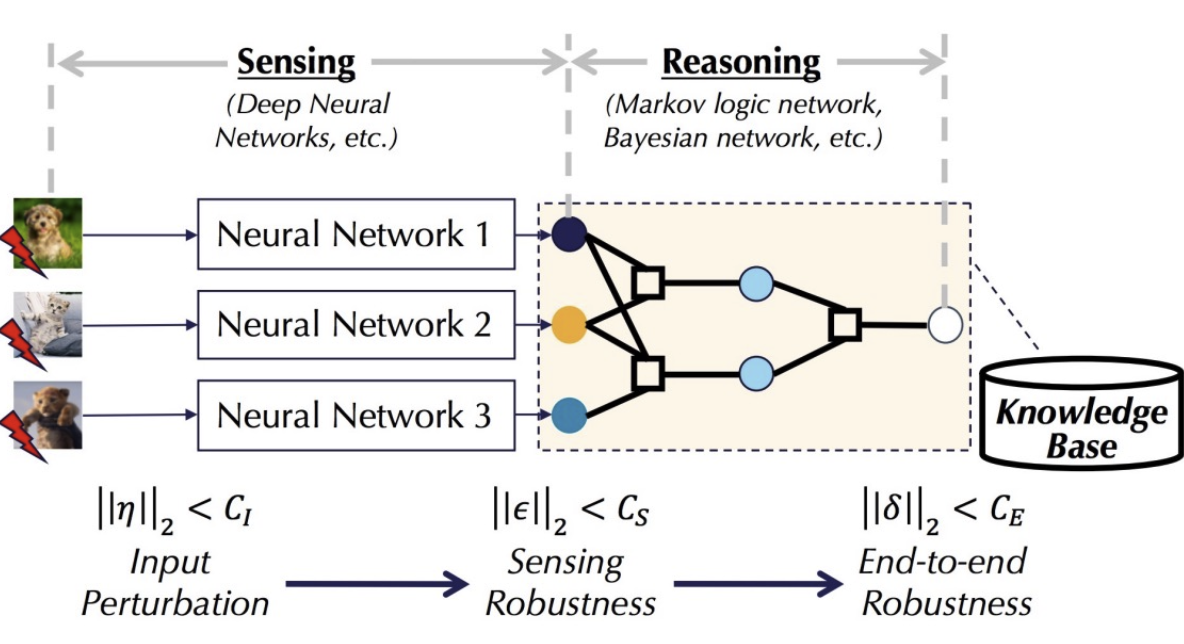
如果将感知-推理机器学习应用到上文中的自动驾驶路边警示牌识别当中。下图中,o代表模型的输出,s代表感知的结果。三个感知模型提取三种特征:对停止标志的识别,此标识是否含有“Stop”字样,以及牌子外形是否是八边形。其中如果识别出“Stop” 标识,则最后结果(o)一定是“Stop”标识。如果识别出“Stop”字样(s),则最后结果(o)也一定是“Stop”标识。如果最后结果(o)是“Stop”标识,则牌子形状一定是八边形(下图:o => s)。实验结果显示应用感知-推理机器学习可以显著提高自动驾驶算法的鲁棒性。
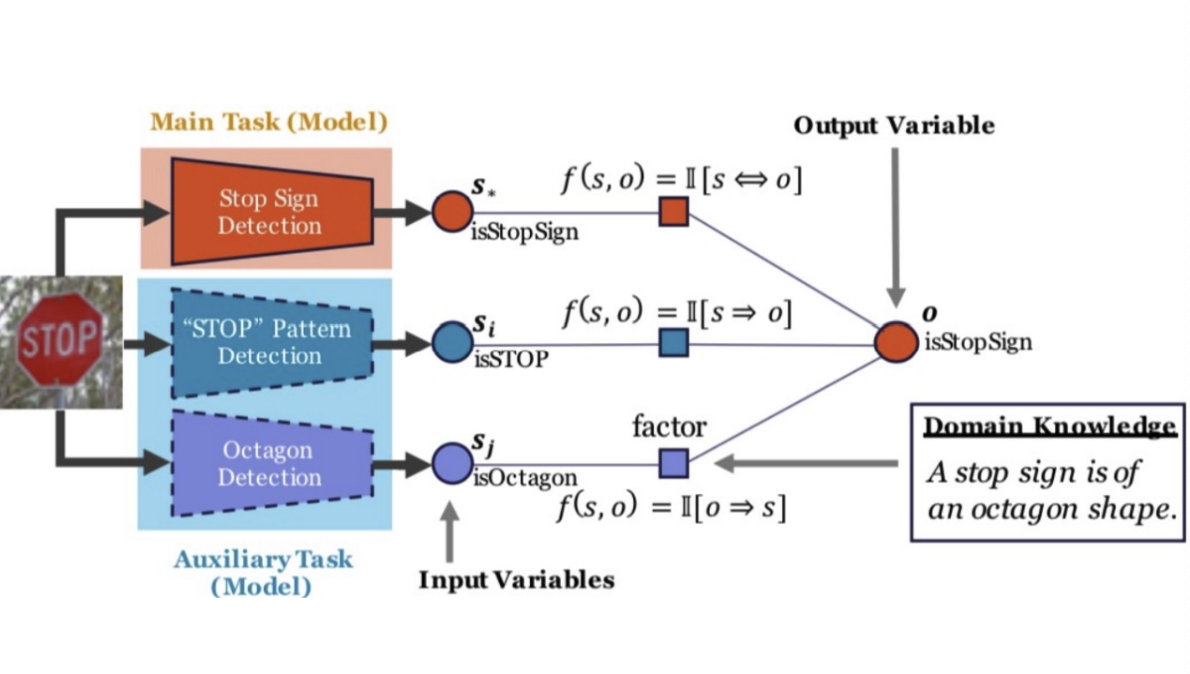
值得注意的是感知-推理机器学习没有应用到任何攻击时所需的信息,所以对于任何的攻击的方式,该方法都可以达到防御的效果。
联邦学习中的可验证鲁棒性
李博教授提出在联邦学习的训练过程中可以提供可验证性。其中如果攻击者对模型更新能够造成的扰动在一个限定的范围里面,则模型仍然可以提供一定的可验证鲁棒性。通过整合后门攻击扰动,模型间距离以及模型预测一致性,李博老师团队成功证明在特征水平上的鲁棒性条件,即只要攻击者所造成的扰动小于一个阈值,模型在输出上就能保证一致性。
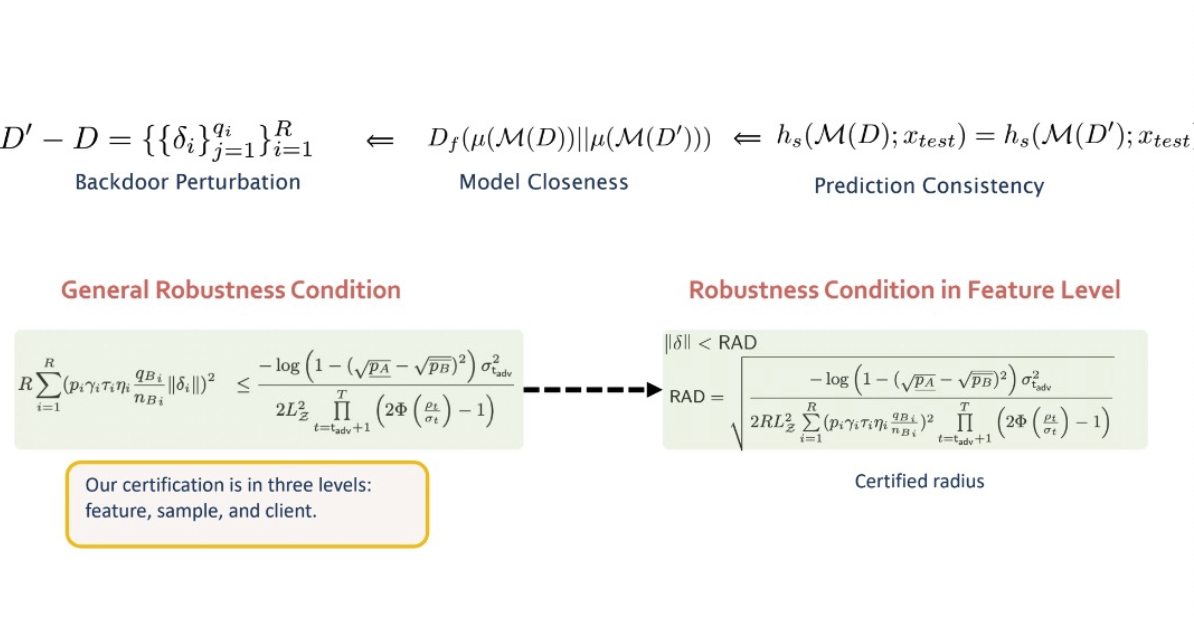
可验证鲁棒性作为一个刚刚出现不久的领域,为模型提供了最差情况下的表现。然而目前最优的理论和实践中仍然存在着较大的落差,对于该领域的理论提升还有很长的路要走。
除鲁棒性,隐私性和泛化性各自的研究之外,其三者之间的联系,是一个更重要且有待研究的问题。比如,鲁棒性一定情境下能揭示隐私性,而隐私性也能够提供可验证鲁棒性。可信机器学习中其他问题,例如公平性机器学习等也可以归结在这个框架下,同时也是非常活跃的领域。
精彩视频回顾及完整版PPT下载,请点击:
AIR学术沙龙第16期 | 可信机器学习: 机器学习鲁棒性、隐私性、泛化性、及其内在关联






