1月11日晚,由DISCOVER实验室主办的第二十七期AIR青年科学家论坛如期举行。本期讲座有幸邀请到北京大学助理教授王鹏帅,为AIR的老师与同学们做了题为《Unified Deep Learning Frameworks for Computer Graphics》的精彩讲座。


王鹏帅,现为北京大学助理教授。2013年和2018年分别于清华大学获得本科学位和博士学位。2018年至2022年,就职于微软亚洲研究院,历任研究员、高级研究员。研究方向为计算机图形学、几何处理和三维深度学习,在图形学、视觉学术会议SIGGRAPH(ASIA)、CVPR、ICCV等上发表多篇论文。担任图形学学术会议SIGGRAPH Asia 2024、EuroGraphics 2024、CVM 2023/2024程序委员,图形学期刊Computers & Graphics副主编。于2023年获得AsiaGraphics 青年学者奖。
图形学和计算机视觉中关注的任务有很大交叉,其中包括对三维数据的理解、生成、仿真和渲染。近些年来,深度学习的技术在这些任务上取得很大的突破,引起了大家的极大关注。但王博士指出,深度学习技术应用到三维数据存在一些挑战:
首先,深度神经网络最初是为定义在二维均匀格点上的图像所开发的,而三维数据有非常多种表达,比如体素、三角形网格、点云、一些艺术家设计出的样条曲面等等。对三维数据的表达多种多样,而原始的神经网络并没有针对这些表达而定义。因此,科研人员需要针对不同的三维数据表达进行神经网络的适配。这就导致针对每一种表达、每一种任务都需要设计一个神经网络。王博士指出,这种研究状态存在两个问题:一是神经网络的开发代价较高,二是处理三维数据的神经网络很难规模化。为了解决这些困难,我们希望针对图形学开发一个较为统一的深度学习框架,解决尽可能多的任务。例如,针对三维数据的多种表达,我们将其转换为某种统一表达(例如八叉树),再构建一个较为标准化的神经网络。在神经网络的backbone后面接上轻量级的前段来完成理解、生成、仿真和渲染任务。
王博士介绍了其团队过去几年中在这一方向上的一些研究成果。
首先是基于八叉树的CNN网络(O-CNN,SIGGRAPH 2017)。O-CNN可以完成三维理解任务。具体而言,给定一个三维物体,先构建一个包围盒,若包围盒非空,就将其一分为八,直到达到最大深度为止。以此将三维物体转化为八叉树。转换完成后,我们希望将神经网络的运算和存储限制在非空区域中。八叉树的结构能够帮助我们快速实现一些卷积,把空的区域中的卷积运算跳过,实现巨大的时间和内存的节省。不同于Submanifold Convolution和MinkowskiNet需要构造多种分辨率的哈希表,O-CNN的八叉树本身就具有很好的层级结构。接着,王博士简介了O-CNN在三维生成任务上的用法。但是,这种方法生成的三维物体表面网格具有缝隙。进一步,在对偶八叉树(Dual Octree)上构建图卷积并进行运算后,预测feature,而后就能够重建出更加连续的三维曲面。
为了解决曲面不连续问题,我们使用了图神经网络,这破坏了神经网络的统一性。Transformer在CV和NLP领域取得的重大突破,及其很好的形状理解能力,激发了人们研究三维点云的Transformer模型。
Transformer直接作用于三维点云理解任务存在一些挑战。首先,若元素数量为N,Transformer的复杂度是
 ,这导致其难以高效处理大规模点云。其次,我们依然希望找到统一的神经网络架构来处理所有的点云理解问题。此前一些相关工作,例如PCT,Point-BERT, Point-MAE都是用全局Transformer来处理点云,效率很低。为了加速这一过程,CV领域产生过一些很好的尝试。为了加速ViT,把图片划分成一个一个小窗,attention模块并行地执行到每个小窗里。这一想法被推广到3D上,产生了例如Stratified Transformer,SWFormer,SST等工作。但由于点云的稀疏性,窗口内元素个数不均匀,这一想法不能很好地直接推广到三维数据。另一派加速方法是对点云降采样,形成稀疏点,在低分辨率点云上进行Transformer运算。但这一过程信息有损,导致模型性能受限。此外,还有一类工作使用K近邻的方式做attention运算,将attention以滑动窗口的方式作用在每个点上,例如Point Transformer和Point Transformer v2。但这类方法窗口与窗口间有很多重叠,也是不够高效的。
,这导致其难以高效处理大规模点云。其次,我们依然希望找到统一的神经网络架构来处理所有的点云理解问题。此前一些相关工作,例如PCT,Point-BERT, Point-MAE都是用全局Transformer来处理点云,效率很低。为了加速这一过程,CV领域产生过一些很好的尝试。为了加速ViT,把图片划分成一个一个小窗,attention模块并行地执行到每个小窗里。这一想法被推广到3D上,产生了例如Stratified Transformer,SWFormer,SST等工作。但由于点云的稀疏性,窗口内元素个数不均匀,这一想法不能很好地直接推广到三维数据。另一派加速方法是对点云降采样,形成稀疏点,在低分辨率点云上进行Transformer运算。但这一过程信息有损,导致模型性能受限。此外,还有一类工作使用K近邻的方式做attention运算,将attention以滑动窗口的方式作用在每个点上,例如Point Transformer和Point Transformer v2。但这类方法窗口与窗口间有很多重叠,也是不够高效的。
接下来,王博士讲解了OctFormer的两个核心要点。首先,OctFormer打破思维定式,让窗口形状自由变换,保证每个窗口内点数相同且窗口局部性良好,实现高效并行执行。观察发现,八叉树结构刚好可以实现这一窗口的构建。其次,八叉树的数据结构帮助我们打破了第二个思维定式,即点云是杂乱无序的。构建八叉树时,其实是在做点云排序。
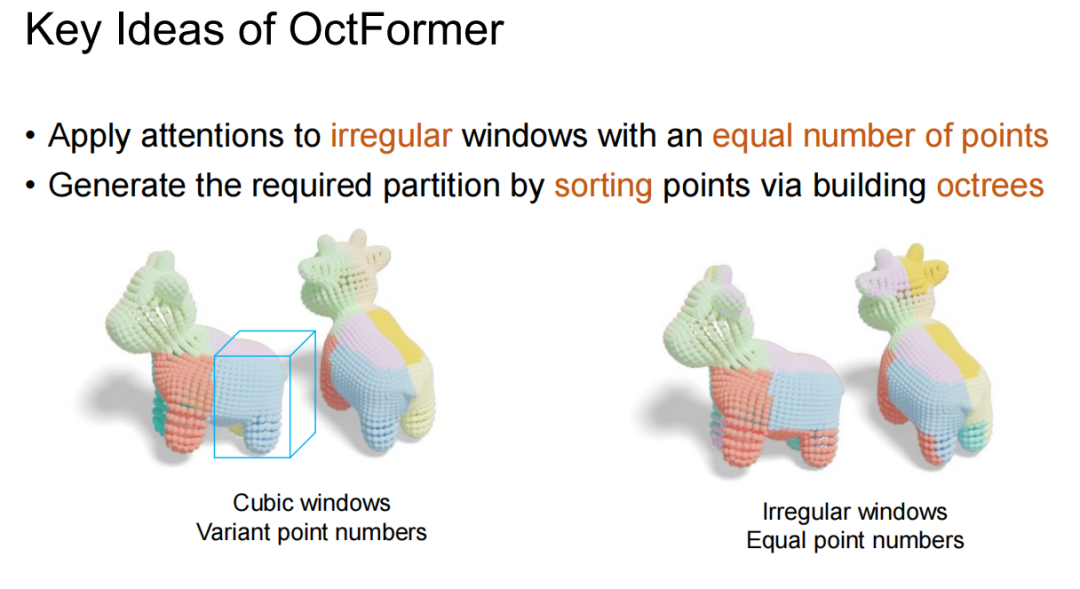
王博士接着详细解释了构建八叉树的过程,即对点云排序的过程。GPU上构建点云是一个自底向上的过程。给定点云后,将其按Shuffled Keys实现Z字形排序。Z字形排序的好处在于,排序后相邻的四个节点实际也是相邻的。排序完成后,将Z字形分形降采样,就直接构建了父节点。
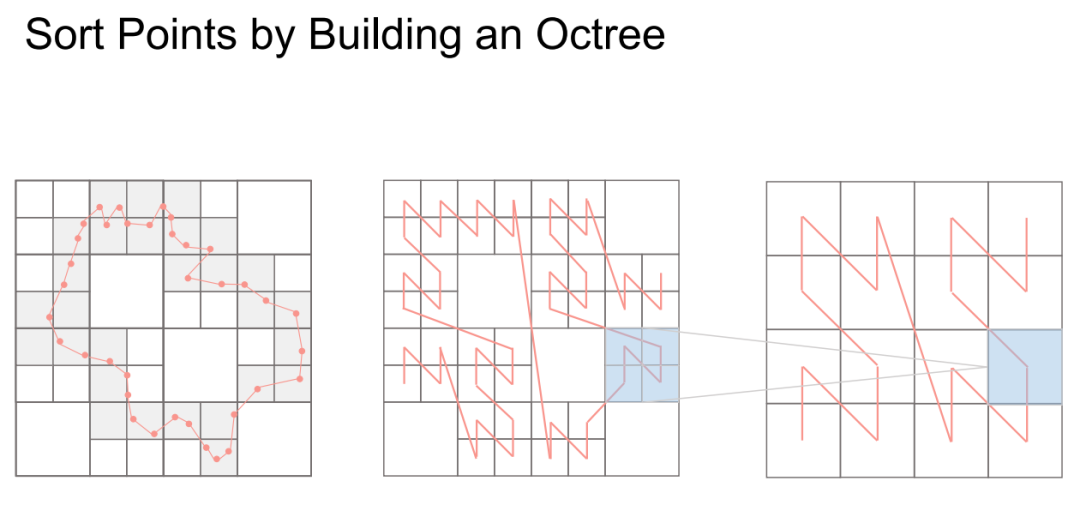
构建完八叉树后,我们只关注非空节点。八叉树的非空节点在内存也是中沿着Z字形顺序存储的,按序按窗口大小直接划分,即可得到属于同一窗口的八叉树节点。这一过程在pytorch中相当于排完序后对tensor的reshape操作,只是一种描述的修改,并没有计算代价就得到了划分好的窗口。接下来Octree Attention就在不同颜色的窗口里并行执行。进一步,为了实现窗口间的交互,王博士团队还设计了Dilated Attention。
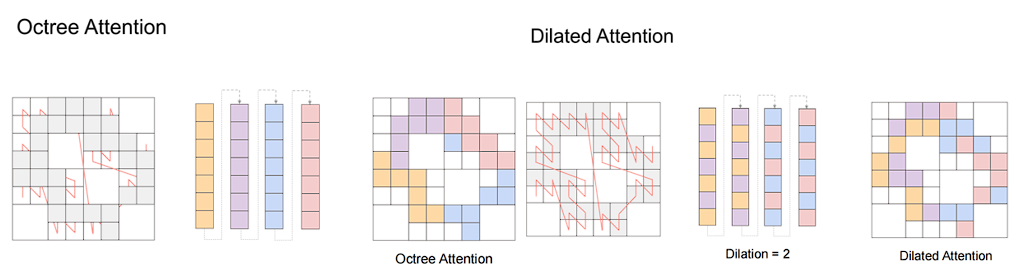
此外,Attention是无法感知位置的,因而我们需要加入Positional Encoding。本文选用了Conditional Positional Encoding(CPE)的做法。此处,CPE可以实现为一个Octree-based Depth-Wise Convolution。
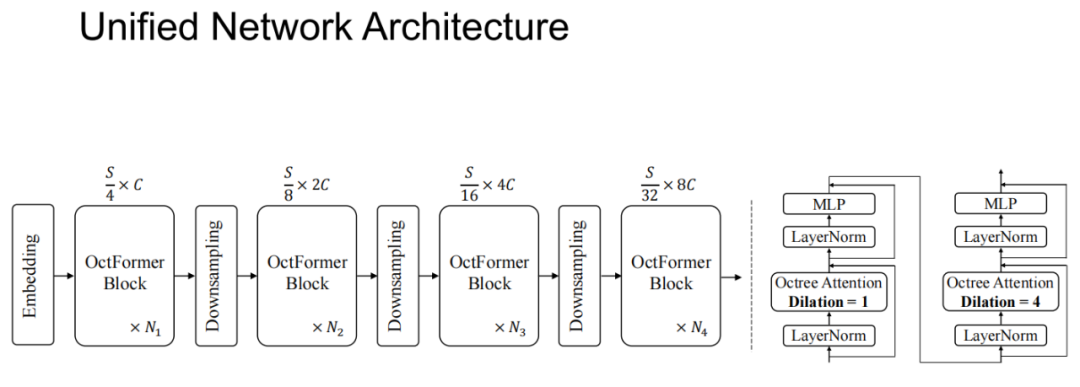
随后,王博士给我们展示了OctFormer这一统一化网络的框架结构。其中,一个OctFormer Block内部由两个连续的OctFormer构成,Dilation分别为1和4。
最后,王博士展示了OctFormer在点云分割、检测等各个任务上的实验效果。其在速度和性能上都取得了优异表现。
文稿撰写 / 沈思甜
排版编辑 / 王影飘
校对责编 / 黄 妍






