12月7日晚,由DISCOVER实验室主办的第二十六期AIR青年科学家论坛如期举行。本期讲座有幸邀请到浙江大学软件学院“百人计划”研究员彭思达,为AIR的老师与同学们做了题为《Towards the High-Fidelity and Real-Time Dynamic View Synthesis》的精彩报告。


彭思达,浙江大学软件学院“百人计划”研究员、浙江大学计算机科学与技术博士。研究方向为三维计算机视觉,至今在TPAMI、CVPR、ICCV等期刊或会议发表三十余篇论文,谷歌学术引用2300余次。曾获得CVPR 2021最佳论文提名奖,CCF-CV学术新锐奖。
从文字、照片再到视频,技术的发展使我们记录世界的方式越来越真实。在本次讲座中,彭博士为我们介绍了可能是下一个时代的记录方式——体积视频。通过录制整个三维场景而不是二维图像,体积视频允许在播放过程中的任意视角移动。由于更加贴近人类的自然感知方式,这一技术在沉浸式视频通话、自由视角广播和日常生活记录方面都有广阔的应用空间。
彭博士首先介绍了体积视频技术的目标:以多视角视频作为输入重建出任意新视角的视频,然后带我们回顾了到目前为止的实现方式。传统的重建系统技术方案包括在不同视角设置许多摄像设备并在这些视角之间插值,以及使用结构光等手段重建对象mesh并附加纹理。这样的方法有较高的设备成本,且重建质量受许多因素制约。
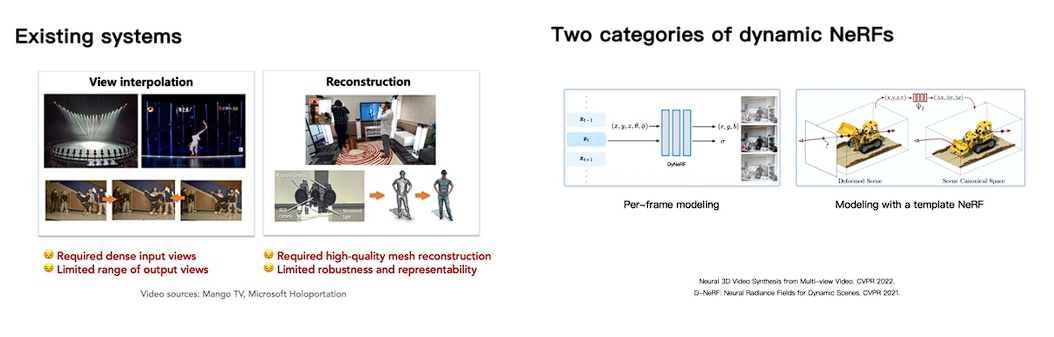
彭博士介绍说,最近神经辐射场(NeRF)的提出为学界揭示了一种全新的连续场景建模方法:使用MLP网络编码场景中方向相关的辐射度信息,并使用体积渲染技术计算任意视角下的颜色。基于NeRF的体积视频实现主要可以分为两类:用添加时间嵌入的方式为每帧场景建模,或者利用一个形变场将所有时间的场景映射到同一个典范(Canonical)空间。然而,这些方法运行缓慢、无法实时渲染,且渲染质量受到模型容量的制约。接下来,彭博士为我们讲解了其团队解决这两个问题的三项工作。
由于方法的相关性,彭博士首先以K-Planes为例介绍了基于网格的NeRF实现。通过将信息更多的存储在特征网格这一显式表示中,这类方法对MLP容量的需求较原始NeRF实现大幅降低了,因此可以使用更小的MLP实现更快的渲染速度;特征网格的可扩展性也有益于模型容量的增加。然而,这一方法的渲染质量依然不够好。
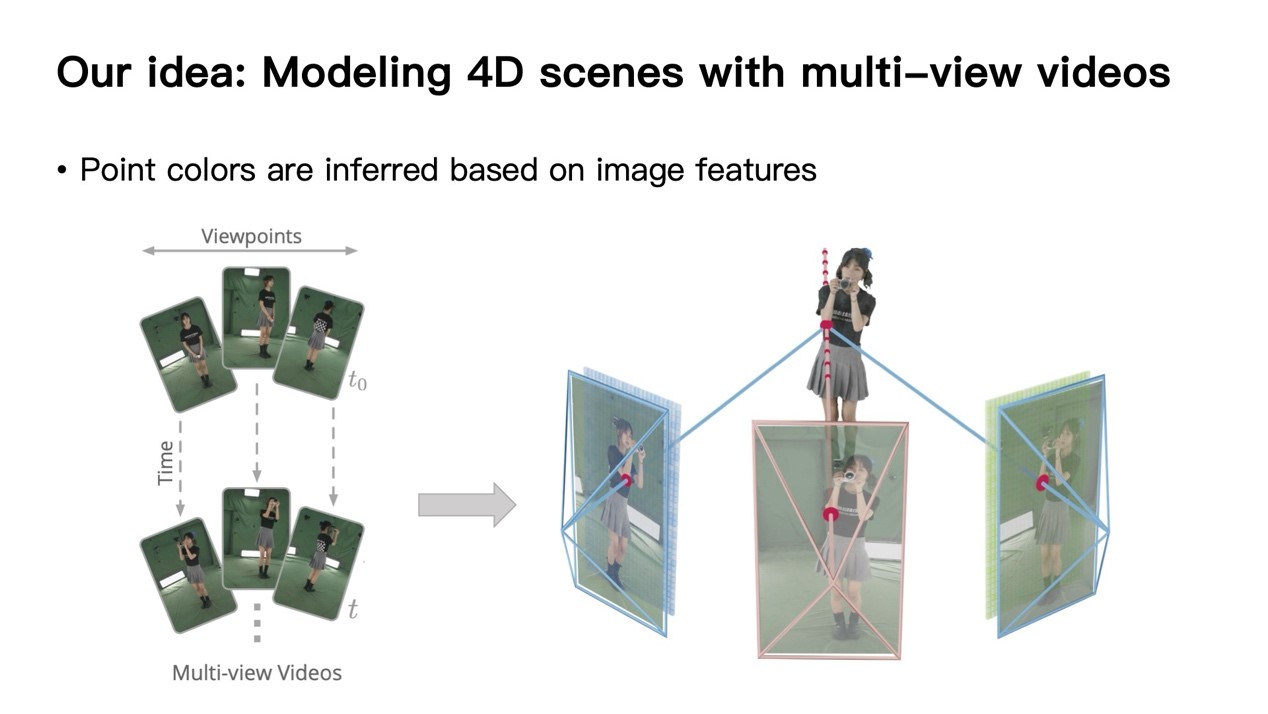
彭博士团队提出了一种直接基于图片的渲染(IBR)方法ENeRF。ENeRF首先将输入图片编码为特征图;对于要查询的渲染点,将其投影会所有视角的特征图上,查询出对应位置的特征并进行渲染。得益于直接利用了输入图像的信息,这一方法的渲染质量有明显的改善,但传统体积渲染中沿光线稠密采样的方式意味着每个像素对应大量的采样点,这拖慢了性能。为此,彭博士团队使用输入的多视角图像计算新视角下的MVS深度图,实现了深度指导的采样。将采样点数量降低至稠密采样的1/60,大幅降低采样过程的时间消耗。
在多种数据集上的验证结果显示ENeRF相较先前的方法大幅提升了渲染速度。彭博士团队搭建了基于多摄像头的场景采集系统,并借此实现了实时重建与渲染管线。同时,在体育比赛中的实验证明了其在真实场景中的可用性。
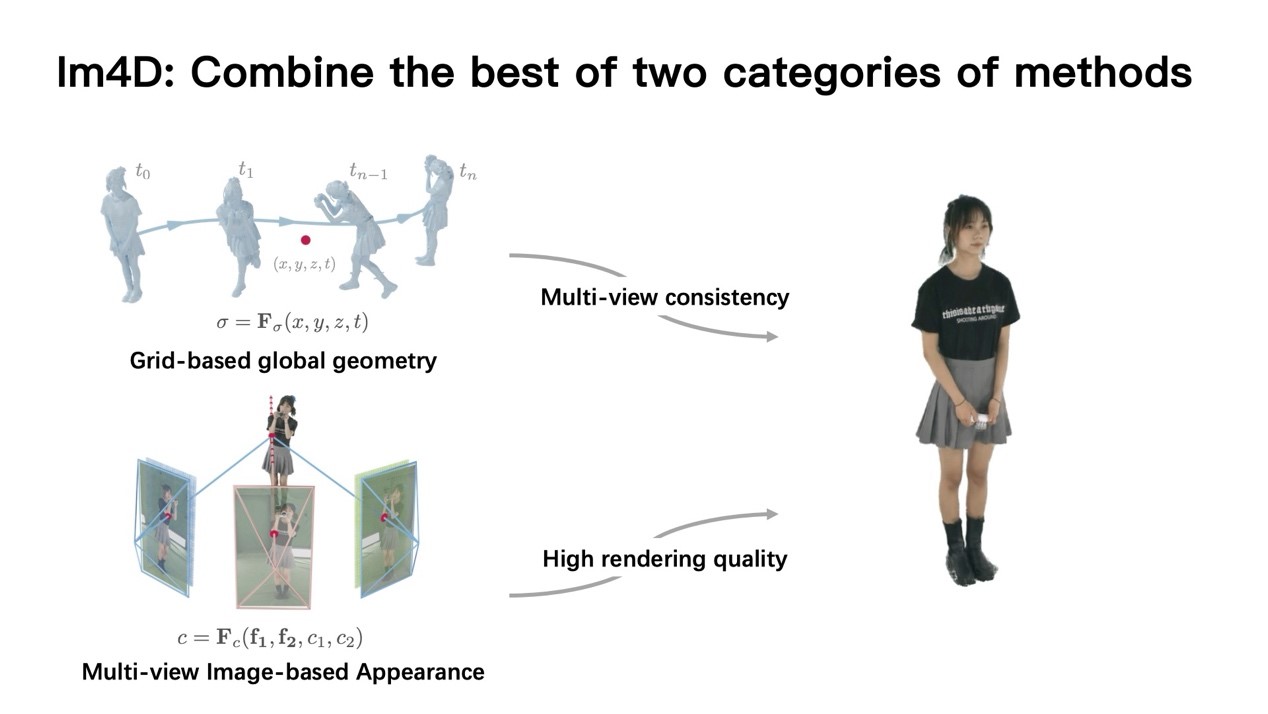
ENeRF依然存在缺乏多视角一致性和场景几何质量低的问题,这表现为在合成新视角数据时存在抖动,未被任何视角拍摄到的空间区域会出现不应存在的几何体(artifacts)。彭博士指出,先前的K-Planes等基于网格的方法能够实现场景几何的较好表示,因此有较好的多视角一致性;因此结合这两种方法可以起到取长补短的效果。基于这一思想,彭博士团队提出的Im4D使用基于网格的动态几何表示,使用网格模型从四维时空坐标推断出采样点的密度;高频的颜色信息则使用IBR生成,渲染时还能预缓存几何信息加速采样。得益于场景表示的解耦,在ZJU-MoCap、DNA-Rendering、ENeRF-outdoor等数据集上的实验显示Im4D实现了更高的渲染质量和速度。
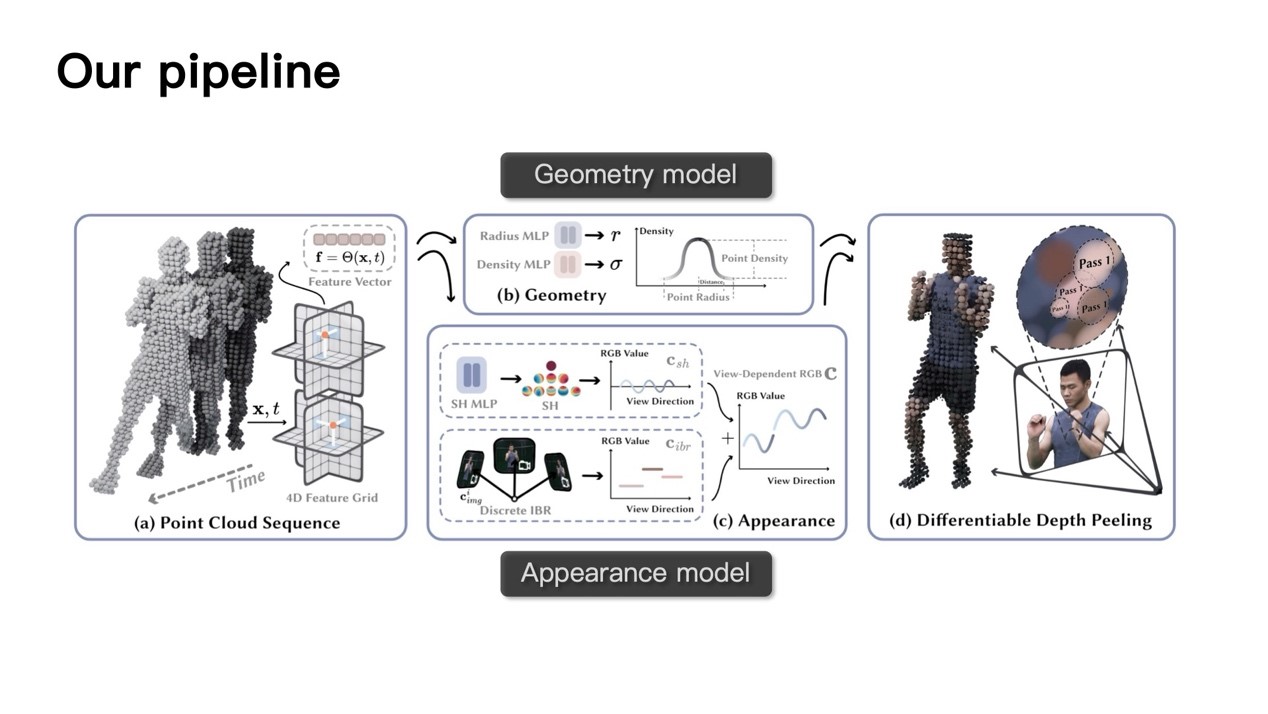
以上的工作虽然较之前的方法大幅加速了推理过程并达到实时渲染,但这是在较低的分辨率上完成的。为了实现4K级分辨率体积视频的实时渲染,彭博士团队提出了一种新颖的场景表示方法4K4D。在这一工作中,动态场景中的几何被逐帧的点云序列表示,点云使用深度peeling算法进行渲染。在渲染过程中,点的位置首先被传入4D特征网格,这是一种类似K-Planes的六平面特征图表示。每个点查询出的特征使用两个MLP分别预测辐射与密度值,并使用外观模型得到颜色进行体渲染。在外观模型的架构上,彭博士团队注意到传统IBR方法的网络输入包含编码的视角方向,这就意味着合成新视角图像必须重新由模型进行推理,这将减慢渲染速度;而移除这一方向编码会导致颜色输出在视角方向上是不连续的。为了解决这一问题,彭博士团队在外观模型中结合了一个球谐函数模型(球谐函数是一种球面基函数,可以使用参数拟合球面上的目标外观函数),它可以生成连续的颜色预测,同时计算更加快速。通过结合两种模型,本文中提出的外观模型是视角相关的,同时允许预计算并缓存输出加速推理。

这一工作从许多因素加速渲染过程:基于点云的场景表示兼容现代GPU的硬件加速功能,新颖的的外观模型允许跳过缓慢的推理过程,将网络量化到fp16并削减MLP深度等。消融研究显示,基于OpenGL的硬件加速能带来7倍的FPS提升,而预计算外观模型模型输出能提升10倍。彭博士介绍,得益于以上多方面的优化,4K4D能过在消费级GPU上实时渲染4K分辨率视频。与类似的工作3DGS相比,4K4D能实现更好的渲染质量,同时模型体积从700MB大幅减小到16MB。

本着将体积视频技术普及给大众的期望,彭博士展望了这一技术在消费级市场落地需要解决的问题:采集设备必须更简单易用,能使用手机、VR眼睛等消费者端设备完成;重建速度需要更快,最好能够实时进行;占用存储空间更小;显示过程等资源消耗需要够小从而能在终端设备上实时进行。彭博士介绍了其团队开源的体积视频研究框架EasyVolcap,这一框架整合了过去工作中使用的方法、管线和数据集,并提供了简单易用的体积视频查看器;其愿景是通过开源加速体积视频的研究。最后彭博士回答了同学们的问题。
文稿撰写 / 杨 卓
排版编辑 / 王影飘






