在现代深度学习基础设施中,GPU Kernel 优化是决定计算效率的“最后一公里”。然而,这块领地长期被极少数拥有深厚硬件背景的专家所垄断。清华大学智能产业研究院(AIR)与字节跳动 Seed 联合SIA-Lab发布了CUDA Agent,旨在打破这一技术壁垒。
近年来,多模态大模型(MLLMs)发展迅猛,从看图说话到视频理解,似乎无所不能。但你是否想过:它们真的“看懂”并“想通”了吗?这些模型在面对复杂的、多步骤的视觉推理任务时,能否像人类一样推理和决策?
清华大学智能产业研究院(AIR)执行院长刘洋教授团队,联合清华大学计算机系、复旦大学带来重磅新作——EscapeCraft:一个3D密室逃脱环境,让大模型像真人一样“动脑逃生”,用于评估多模态大模型在视觉环境中,完成复杂任务推理的能力。测评结果却意外频出:模型常常看到了门,却一直绕着墙走;捡起钥匙,却忘了怎么用;甚至有模型想去“抓”沙发,理由是“可能有暗格”……这不是个别翻车。而是系统性的“看见不代表理解”。即便是 GPT-4o 这样的明星模型,也只有少部分子任务是真的想明白了完成的,其它全是歪打正着。
•论文标题:CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
•项目主页:https://cuda-agent.github.io/
•Github仓库:https://github.com/BytedTsinghua-SIA/CUDA-Agent
•Huggingface数据集:https://huggingface.co/datasets/BytedTsinghua-SIA/CUDA-Agent-Ops-6K
•论文作者:戴炜楠,吴翰林,禹棋赢,高焕昂,李家昊,姜成全,楼伟强,宋宇凡,于鸿利,陈家泽,马维英,张亚勤,刘菁菁,王明轩,刘欣,周浩
一、 背景与核心挑战:为什么 LLM 写不好 CUDA?
1. 高度专业化的“硬件艺术”
CUDA 优化不仅要求开发者精通并行编程,更需对 GPU 微架构(如寄存器压力、共享内存分配、指令流水线等)有深刻理解,并能熟练操作 Nsight Compute 等复杂的 Profiling 工具。
2. 现有大模型的“幻觉”与“平庸”
尽管通用大模型(LLMs)在 Python 等通用编程中表现出色,但在 CUDA 生成任务上仍面临两大困境:
•性能倒挂:顶级闭源模型生成的 Kernel 往往无法媲美 torch.compile 的自动化启发式优化,甚至在复杂逻辑下会出现功能错误。
•能力瓶颈:现有的 Training-free 方法(如简单提示工程或多轮细化)本质上是在“消耗”模型原有的微薄知识,未能从根本上提升模型内在的 CUDA 优化直觉,导致性能增益受到极大限制。
二、 破局之道:CUDA Agent 核心架构
研究团队引入了 CUDA Agent,这是一个大规模智能体强化学习(Agentic RL)系统。它不再只是一个代码补全工具,而是一个能够自主思考、测试、优化的“AI工程师”。
1. 核心组件一:可扩展的数据合成流水线
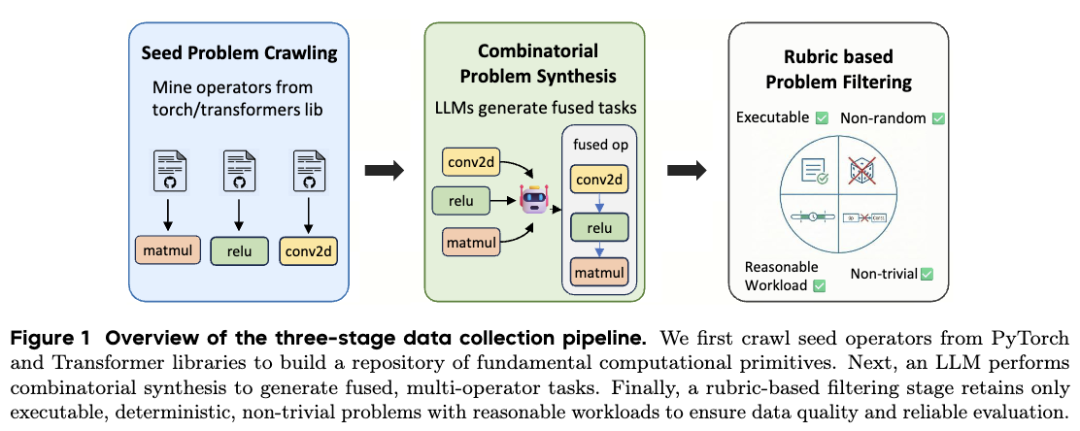
高质量训练数据的稀缺是制约 CUDA 模型发展的核心瓶颈,因为专家级代码的标注成本极其昂贵。为此,CUDA Agent 设计了三阶段生成流程:
•种子爬取与组合:从 PyTorch 和 Transformers 库中挖掘原始算子,并利用 LLM 将 1 到 5 个算子进行“组合拳”式的拼接(Combinatorial Synthesis),合成复杂的融合任务(Fused tasks)。这种方式重塑了优化空间,强制模型学习如何处理算子融合带来的内存带宽瓶颈、寄存器占用和共享内存分配冲突。
•鲁棒性过滤:基于执行反馈,实施多维度清洗。系统会剔除具有随机性、不可执行或计算量异常(Eager 模式执行时间需在 1ms-100ms 之间)的样本,最终提炼出包含 6000 个高质量样本的 CUDA-Agent-Ops-6K 数据集,确保训练数据的“纯度”。
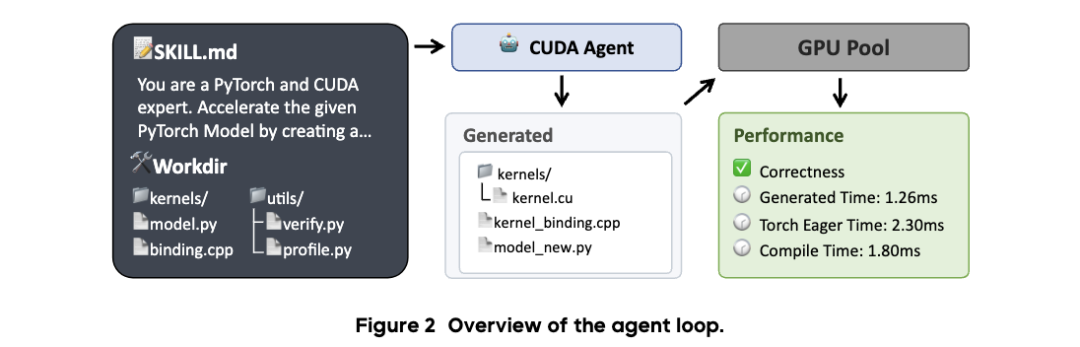
2. 核心组件二:技能增强的环境与里程碑奖励
•标准化技能流:引入 SKILL.md 指南,将专家的优化直觉结构化。系统为智能体提供分析(profile.py)、编写(.cu/.cpp)、编译(compile.sh)、评估和迭代优化的标准化工作流,使其具备“发现瓶颈-尝试优化-验证性能”的闭环能力。
•防作弊机制(Anti-hacking):为防止模型通过调用原生函数(如 torch.nn.functional)或修改测试脚本来“骗取”奖励,系统实施了系统级权限隔离和执行时间约束,确保性能提升完全源于生成的 CUDA 代码。
•鲁棒的奖励调度:摒弃了易受异常值和噪声干扰的原始“加速比”奖励,采用基于里程碑的离散奖励
。这种机制将“正确性”、“跑通”、“超过基础版”、“超过编译器版”设为明确的阶梯目标,联合优化了代码的数值精度与执行延迟。
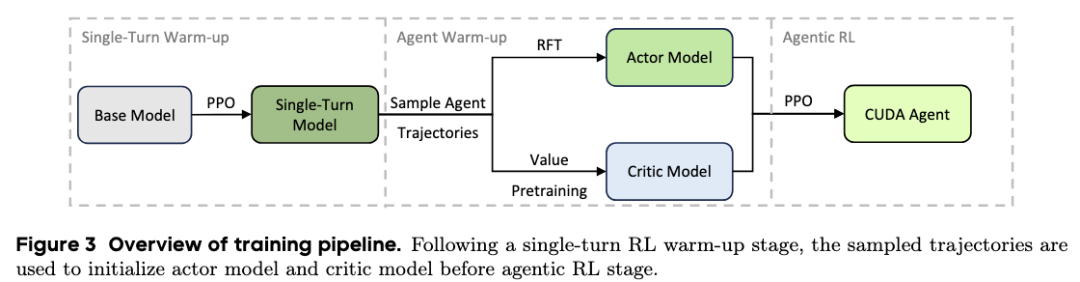
3. 核心组件三:确保训练稳定的算法创新
研究团队指出,CUDA 优化代码在预训练数据中占比极低(不足 0.01%),直接进行 RL 会导致模型因“跨度过大”而发生分布崩溃(Collapse)。
•多阶段预热策略:系统首先进行单轮 RL 增强基础生成能力。随后对 Actor 模型进行拒绝采样微调(RFT)以建立良好的行为先验,并对 Critic 模型进行价值预训练(Value Pretraining)以提供准确的优势估计。这种“先温固再突破”的策略,使得模型能支持高达 128k 长度的上下文,并在 150 个训练步中保持 reward 的持续增长,解决了长程智能体训练不稳定的顽疾。
三、 实验结果:全面超越与性能突破
1. 统治级的提速表现
在 KernelBench 基准测试中,CUDA Agent 展现了极强的竞争力。相较于 torch.compile,它在 Level-1 和 Level-2 任务中实现了 90% 以上的 Faster Rate(即生成的每个 Kernel 均快于编译器),在最复杂的 Level-3 任务中更是达到了 92%。
2. 领跑顶尖闭源模型
面对强大的通用编码模型,专门优化的 CUDA Agent 优势显著。在最高难度的 Level-3 测试中,其加速比超越 Claude Opus 4.6 和 Gemini 3 Pro,证明了大规模 Agentic RL 在垂直专业领域的巨大潜力。
四、 局限性与未来展望
1. 算力成本与对比深度
尽管表现优异,CUDA Agent 仍面临一定的局限:
•对比基准:尚未与 TVM 或 OpenAI Triton 等更复杂的领域特定语言(DSL)框架进行深度对比,主因是这些框架在大规模训练循环中的自动搜索和部署开销巨大。
•算力依赖:该系统的训练高度依赖庞大的 GPU 资源池(使用了 128 张 NVIDIA H20 GPU),这在一定程度上提升了技术复现的门槛。
2. 范式转移:从“代码生成器”到“系统优化器”
CUDA Agent 的成功标志着一个范式的转变:通过为基础模型配备结构化环境和执行反馈,LLM 可以从“被动的代码生成器”进化为“主动的系统优化器”。这种“具身智能”式的代码开发模式,为 GPU 计算乃至更广泛的高性能计算领域实现自动化开发指明了方向。