清华大学智能产业研究院(AIR)联合小米汽车发布了Hyper Diffusion Planner (HDP):一个面向真实道路部署的扩散模型端到端自动驾驶规划框架。不同于大量停留在开环指标或仿真结果的方法,HDP直接面向实车表现 从模型设计、训练范式都做了系统性探索,目标是回答一个关键问题:扩散模型在自动驾驶规划中的潜力,是否被真正发挥出来了?
近年来,多模态大模型(MLLMs)发展迅猛,从看图说话到视频理解,似乎无所不能。但你是否想过:它们真的“看懂”并“想通”了吗?这些模型在面对复杂的、多步骤的视觉推理任务时,能否像人类一样推理和决策?
清华大学智能产业研究院(AIR)执行院长刘洋教授团队,联合清华大学计算机系、复旦大学带来重磅新作——EscapeCraft:一个3D密室逃脱环境,让大模型像真人一样“动脑逃生”,用于评估多模态大模型在视觉环境中,完成复杂任务推理的能力。测评结果却意外频出:模型常常看到了门,却一直绕着墙走;捡起钥匙,却忘了怎么用;甚至有模型想去“抓”沙发,理由是“可能有暗格”……这不是个别翻车。而是系统性的“看见不代表理解”。即便是 GPT-4o 这样的明星模型,也只有少部分子任务是真的想明白了完成的,其它全是歪打正着。
•论文链接:https://arxiv.org/pdf/2602.22801
•项目主页:https://zhengyinan-air.github.io/Hyper-Diffusion-Planner/
•论文作者:郑一楠,谭添一,黄彬,刘恩光,梁睿鸣,张健霖,崔建伟,陈光,马昆,叶航军,陈龙,张亚勤,詹仙园,刘菁菁
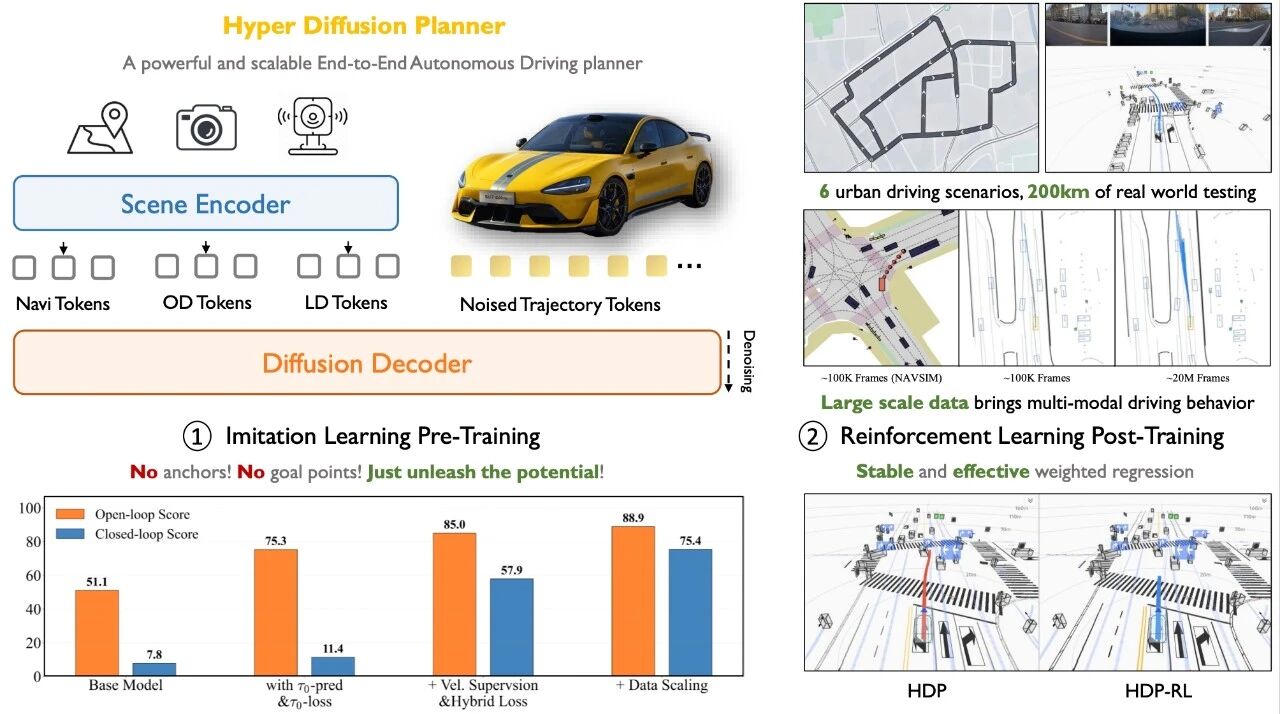
背景:为什么我们还需要重新审视“扩散 + 自动驾驶”?
扩散模型在生成与决策任务中已经展现出强大能力,但在自动驾驶领域,很多工作仍然局限在开环回放或仿真环境。
要真正跑到实车上,挑战并不小:
能力与效率要同时满足:既要理解复杂场景,又要满足车端实时要求;
闭环误差会累积放大:一点偏差可能在连续决策中演化为明显风险;
过度工程掩盖模型能力:现有的工程落地方案依赖锚点、目标点等额外先验条件或重后处理,难以验证扩散模型本体上限。
我们希望走一条更“干净”的路线:在不过度堆叠先验的前提下,系统释放扩散模型在端到端规划中的潜力。
方法总览:HDP 做了什么?
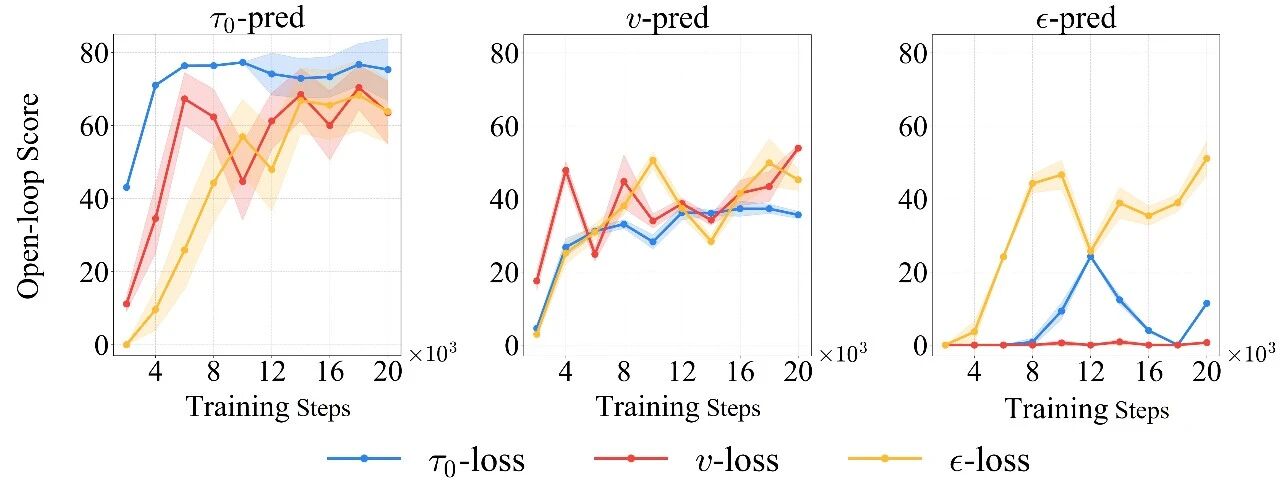
1.重新审视扩散损失空间:规划任务要用“对的目标”训练
扩散模型常见的训练目标来自图像生成范式,但自动驾驶规划和图像生成有本质差异:规划轨迹是低维、强约束、强时序相关的决策输出。如果直接沿用“通用配置”,很容易出现训练不稳定、轨迹抖动和闭环表现退化。
为此课题组系统比较了 9 种 prediction-loss 组合(tau0 / v / epsilon 预测与监督的全组合),结论非常明确:
这一步的意义在于:先把扩散模型的“基础训练坐标系”调准,后续的表征设计与数据扩展才能真正起效。

2.轨迹表示双优融合:Hybrid Loss 同时兼顾几何与动力学
在轨迹表示上,研究人员观察到一个非常典型的 trade-off:
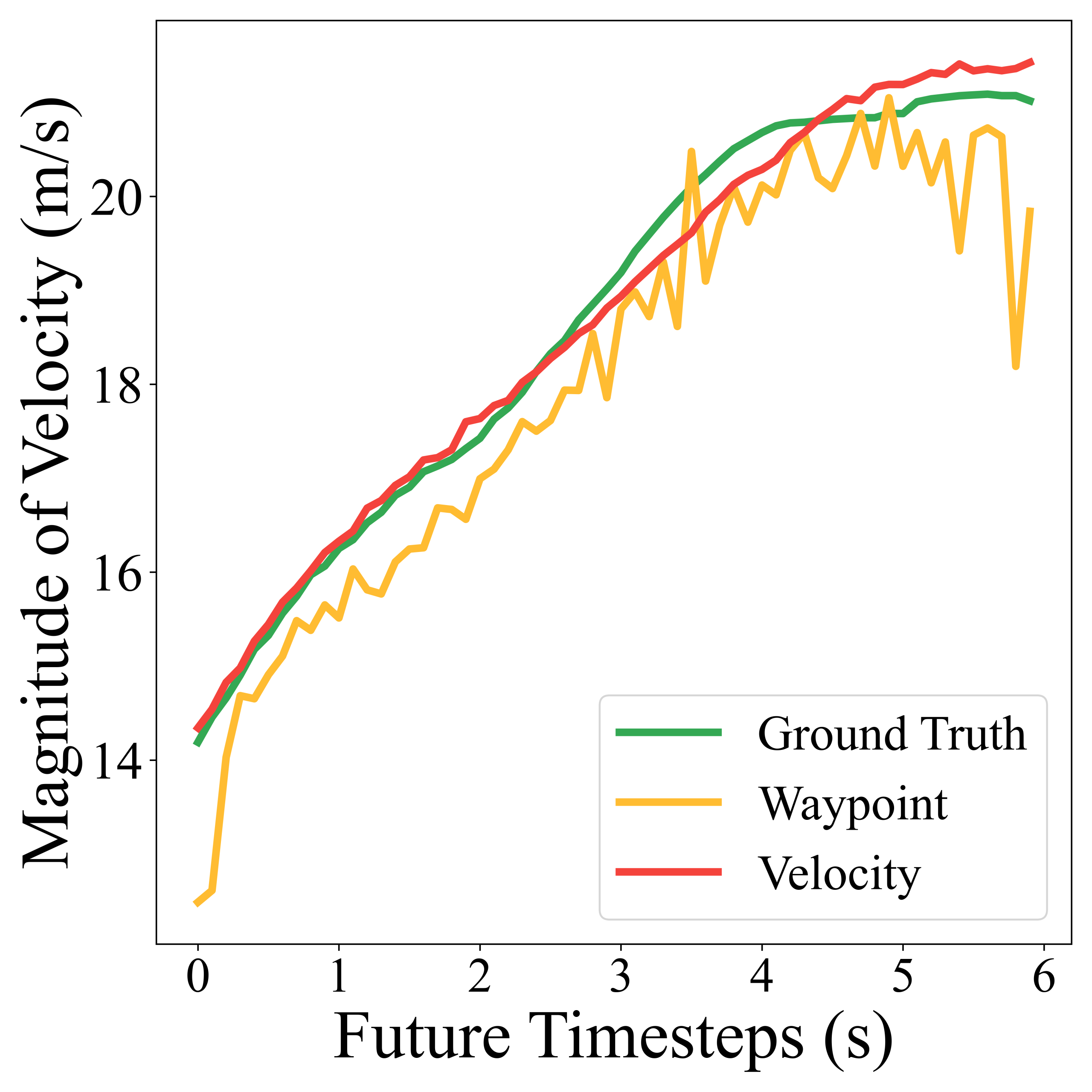
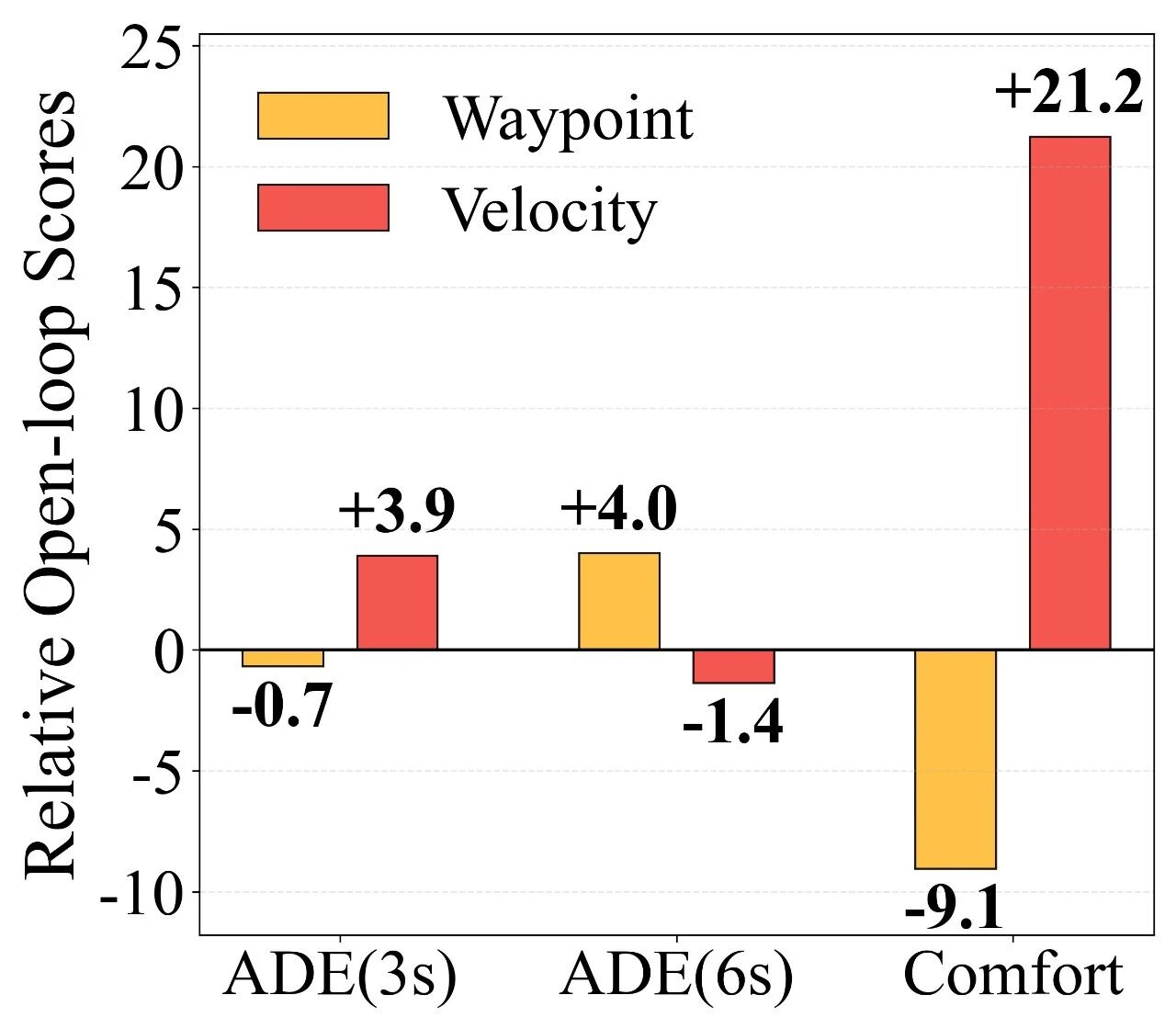
如果只选一边,就会在“轨迹形状”与“动力学平顺”之间做妥协。因此我们提出Hybrid Loss:模型仍然输出速度,但训练时同时施加两类监督:
理论上,我们证明了Hybrid Loss 仍然对应有效的扩散学习目标;

工程上,在实车闭环测试中它显著拉升成功率与稳定性,是从“能跑”到“跑得稳”的关键一步。
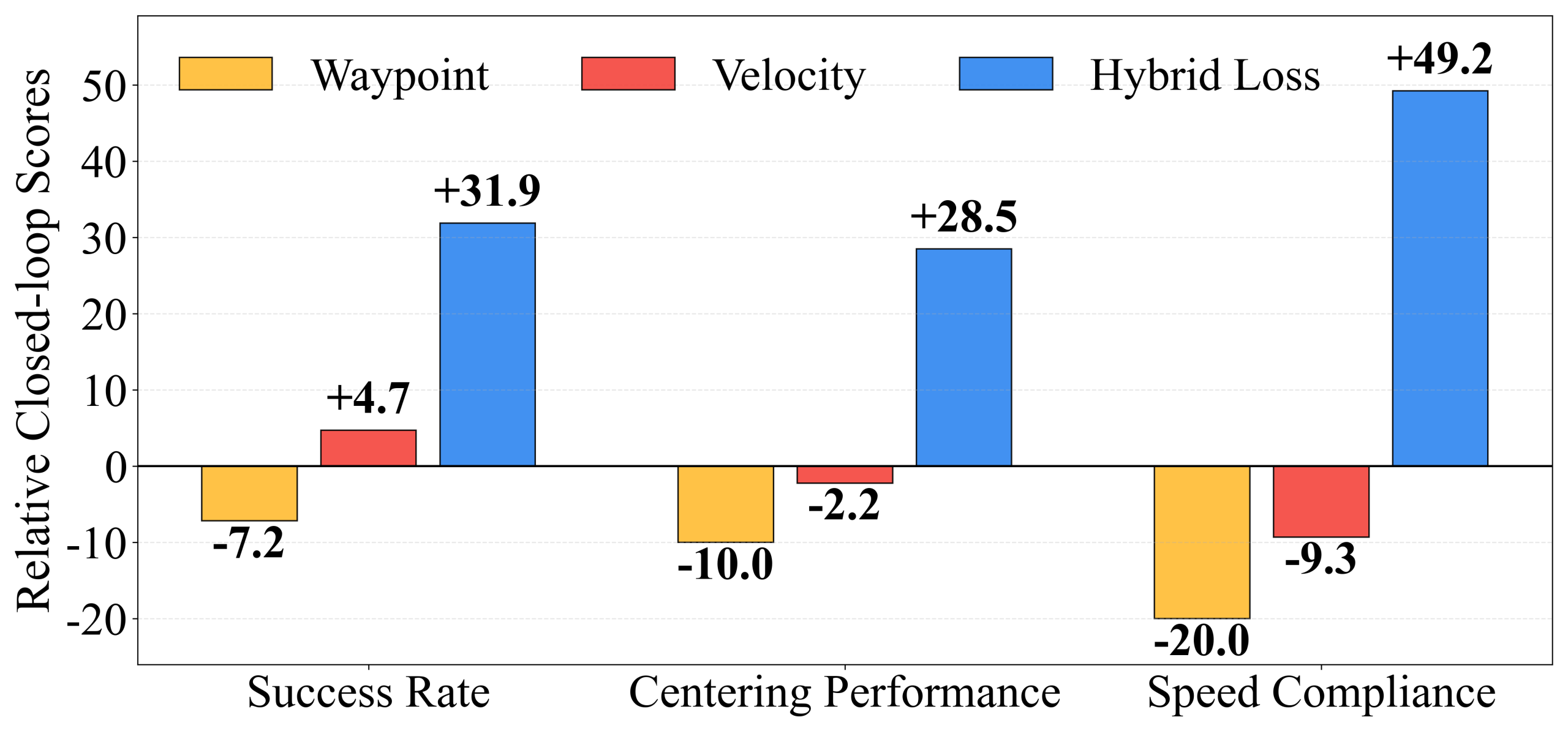
3.数据规模带来“涌现”:近亿级真实帧的系统验证
课题组做了从 10M 到 70M 帧的受控扩展实验,重点回答一个问题:真实数据规模到底能带来什么?
实验结果显示:
小数据下扩散规划容易模式塌缩;
数据规模上来后,多模态行为能力明显增强;
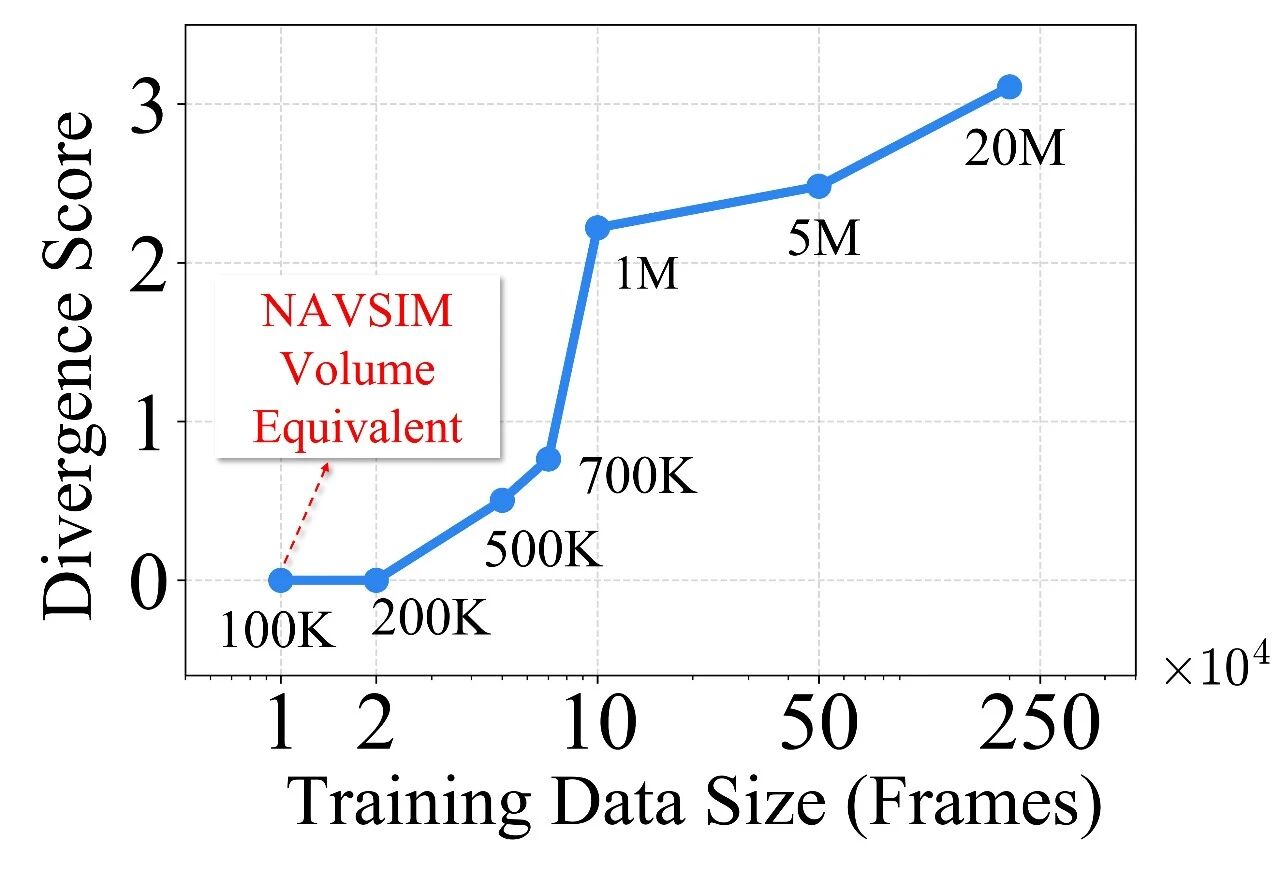
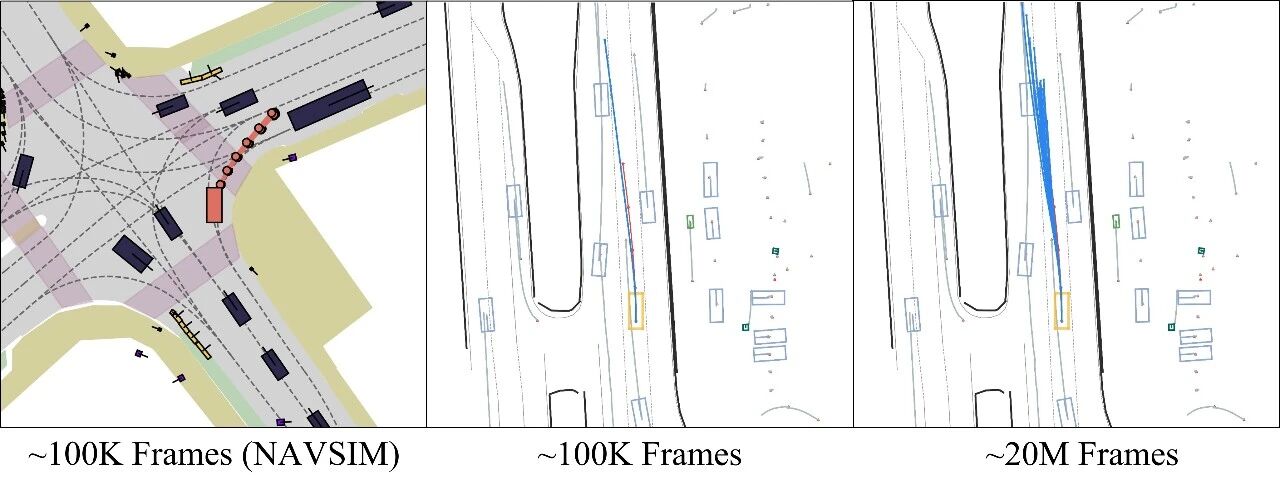
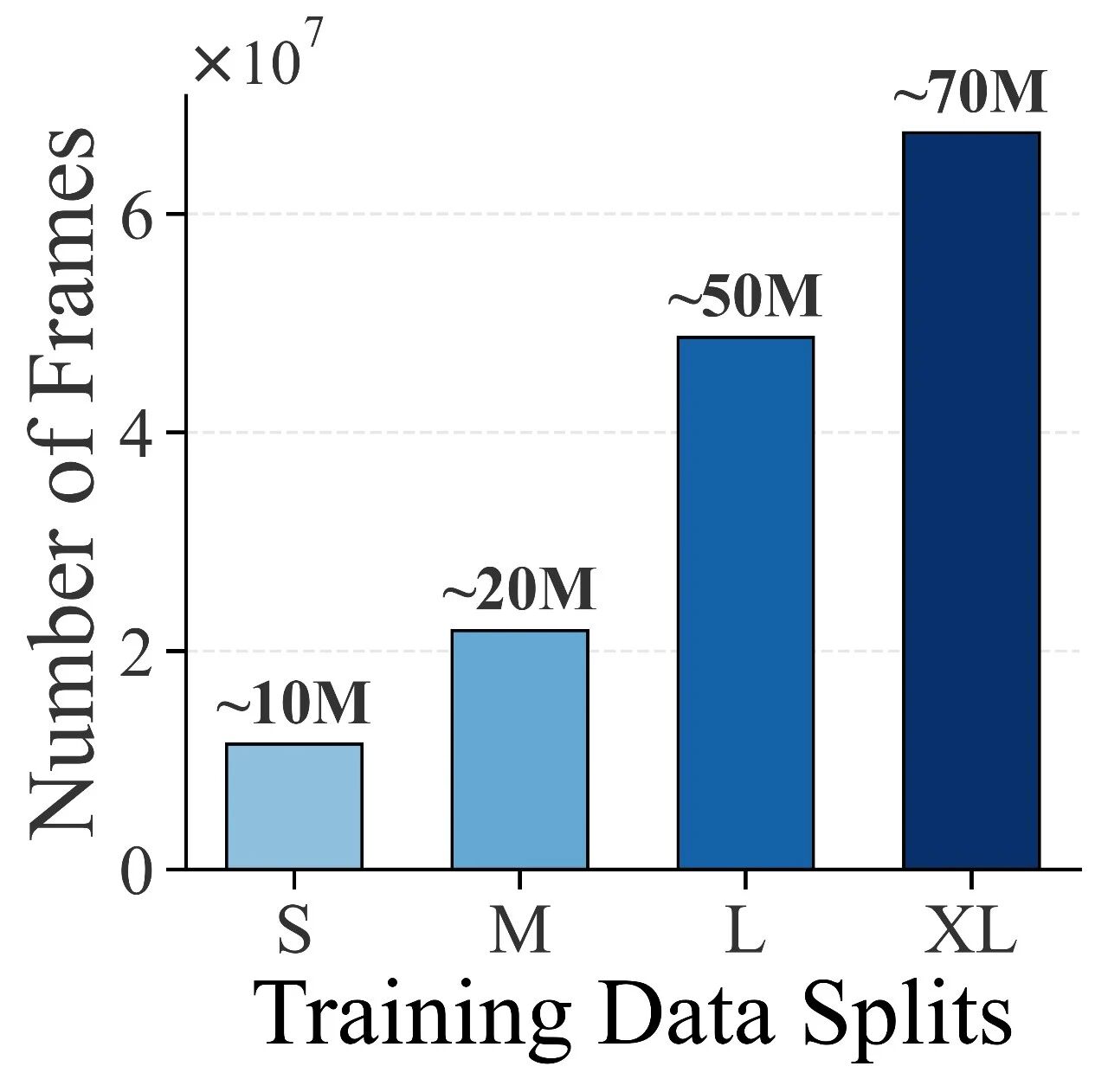
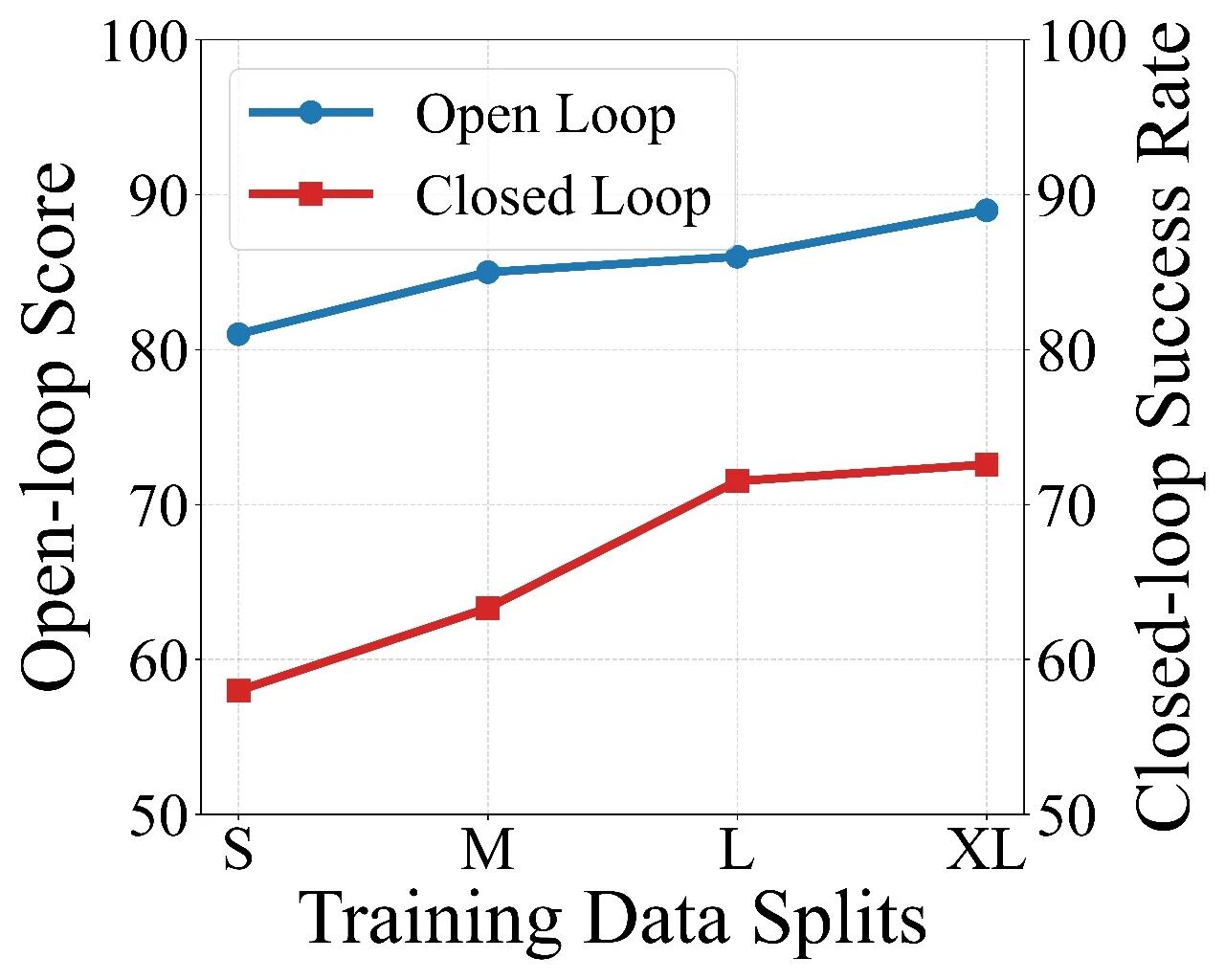
更重要的是,数据扩展不仅提升“平均分”,还提升了模型对长尾交通交互的覆盖能力:同一场景下可以生成更合理的多种可行行为,而不是单一僵化策略。这说明扩散规划在工业级数据条件下具备稳定、持续的可扩展潜力。
4.RL 后训练:进一步强化安全能力
模仿学习可以学到“像人开车”,但在安全关键场景中,仍然需要更直接的目标优化。因此在 IL 预训练之后,我们加入与 Hybrid Loss 兼容的 RL 后训练策略,重点针对安全相关行为做强化。
如果用一个更“公式化”的方式来描述,课题组先在旧策略基础上写出一个带 KL 正则的离线 RL 优化目标,用来约束新策略不要偏离原来的模仿策略:
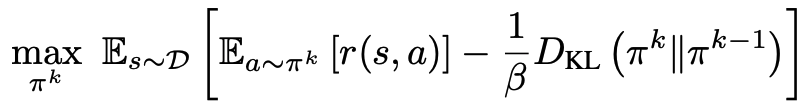
这个目标的闭式最优解可以写成一条简单的“加权重采样”形式:在原策略的基础上,用 exp(β r) 对高回报轨迹进行放大:
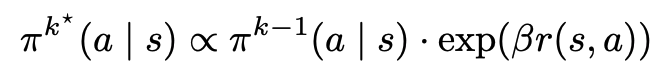
在具体实现上,课题组并不显式采样这条新策略,而是把它“折叠”进扩散训练,得到一个带权重的混合回归损失:回报越高的样本,对应的扩散监督权重越大:
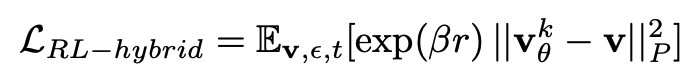
这里的范数与前文 Hybrid Loss 使用的是同一个加权范数,这样就把“更安全”的偏好自然注入到了同一套扩散 + 混合损失框架中,我们在论文中给出了详细的证明。相比之下,很多针对扩散模型的 RL 方法会把整个去噪过程当成一个多步 MDP:将每个 denoise step 拆成一个时间步,再用 PPO 等 RL 算法去优化整条“去噪轨迹”。这类方法一方面实现复杂,另一方面计算量和显存开销都显著增加。课题组的做法只是在原本的 IL diffusion loss 外面乘上一个简单的回报权重,相当于“加权监督学习”,既兼容现有训练管线,又能在几乎不增加工程复杂度的前提下,让扩散规划器朝着更安全的方向偏移。
最终得到 HDP-RL:在真实闭环场景中,模型在安全相关任务上的表现进一步提升,实现从“能开”到“开得更稳、更安全”的持续进化。
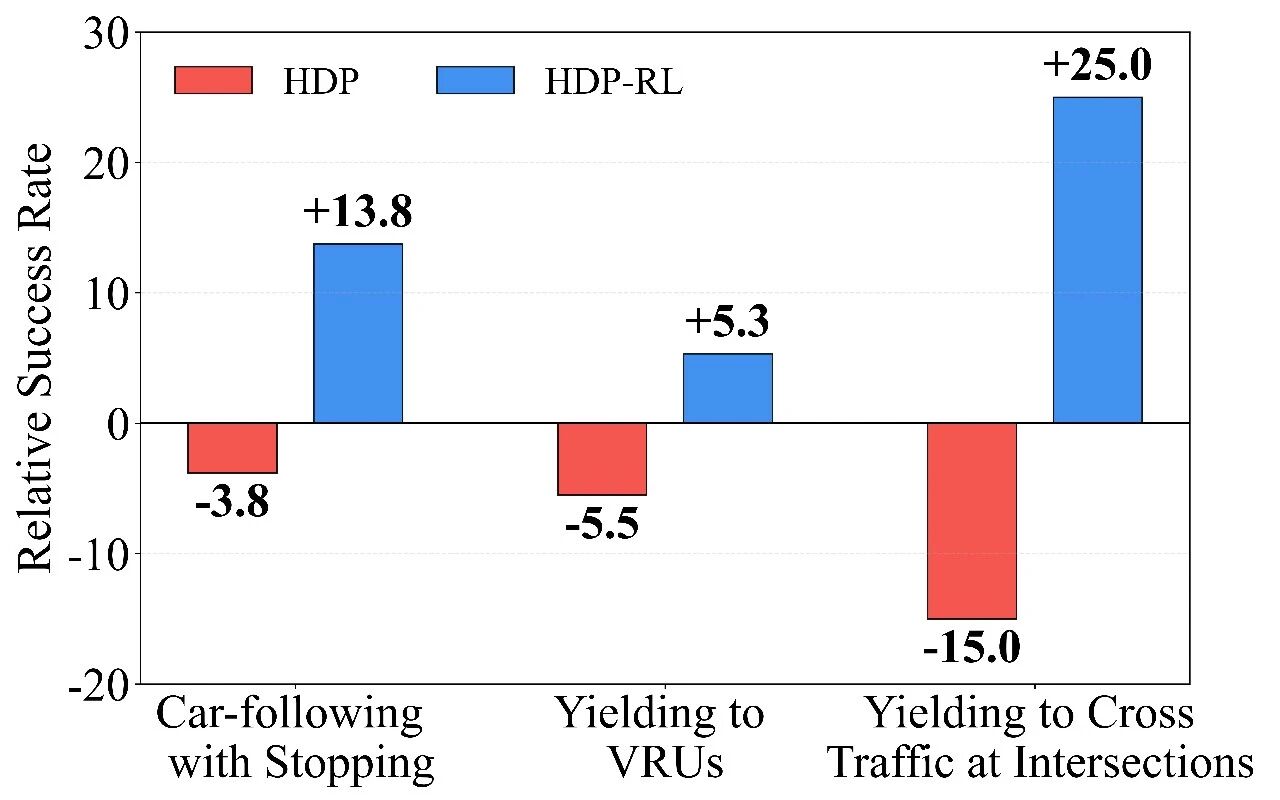
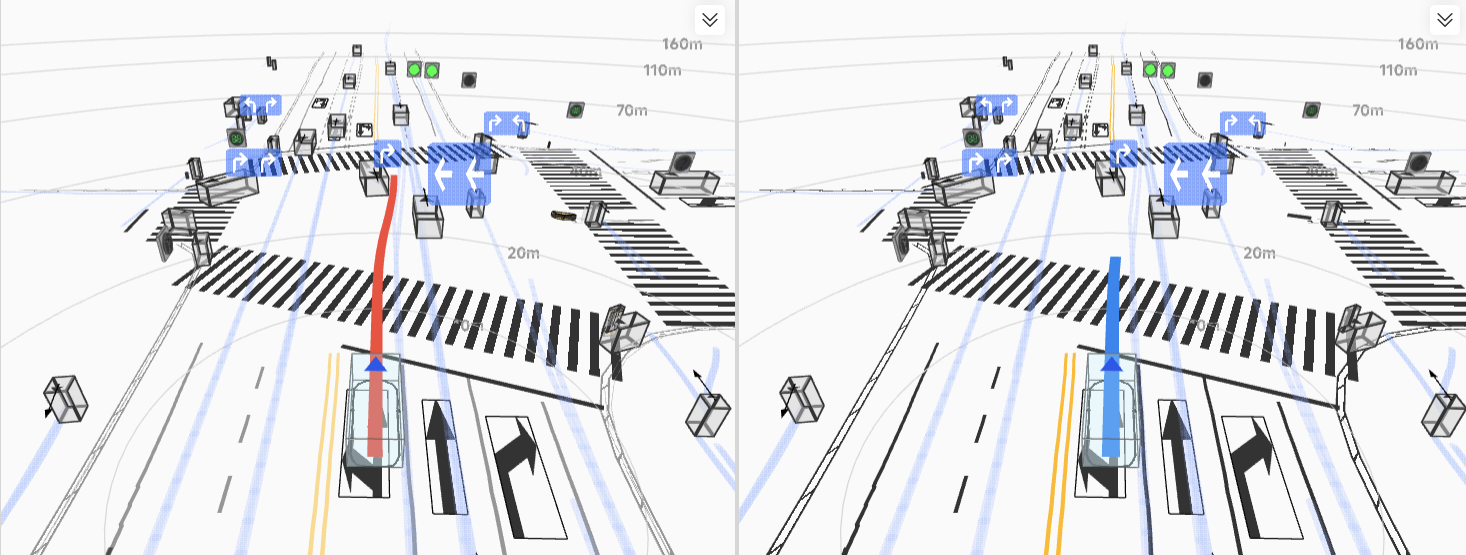
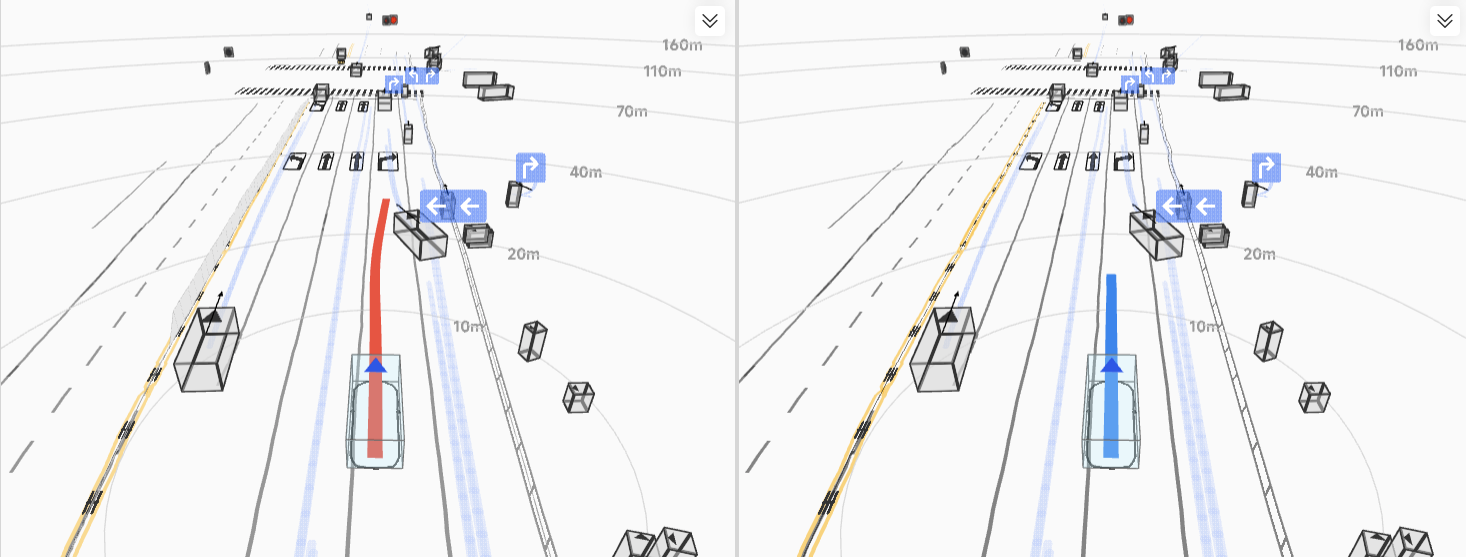
实车结果:不是仿真更优,而是真路更强
HDP 在真实道路闭环测试中覆盖多类城市场景,取得了显著收益:
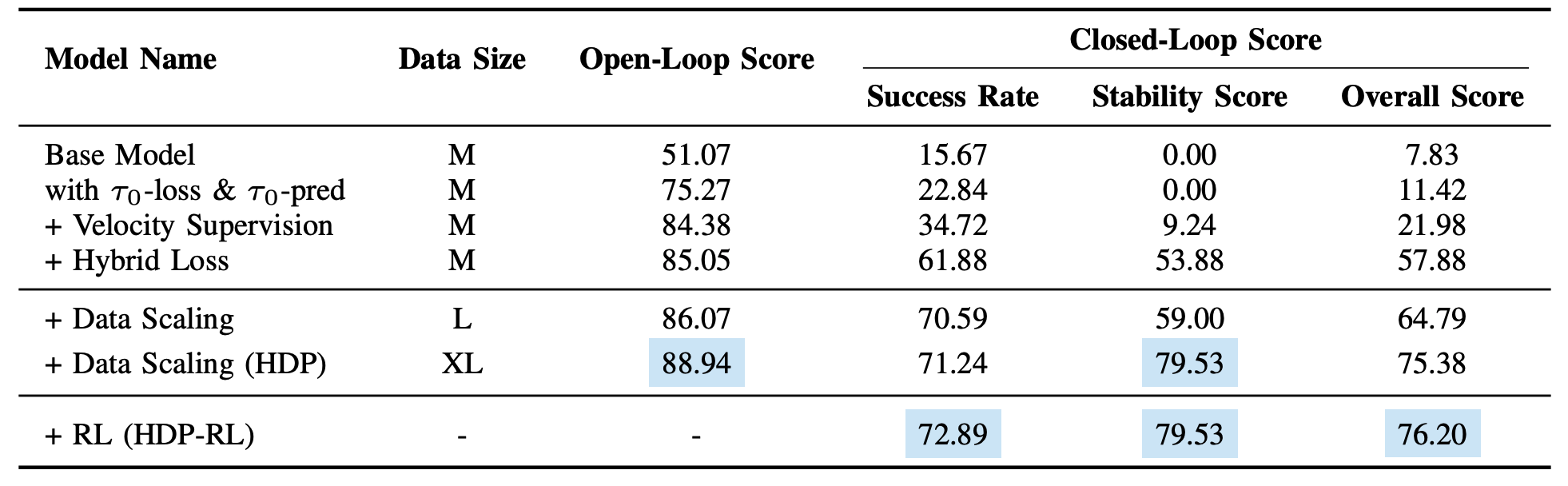
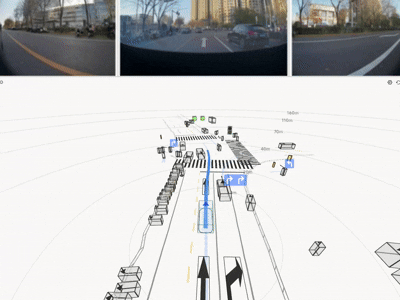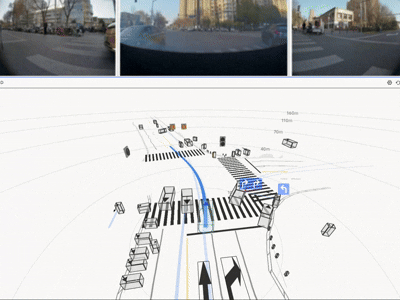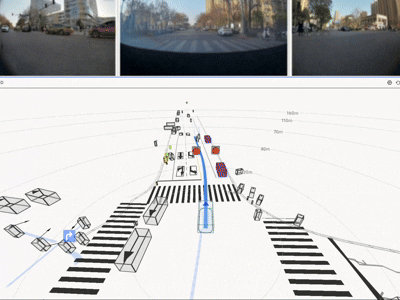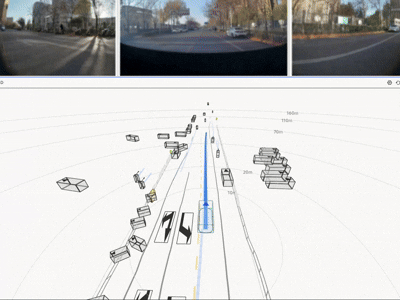

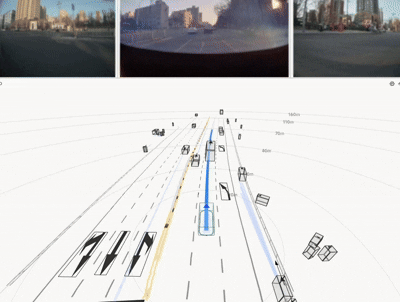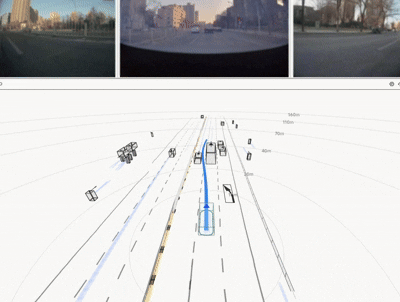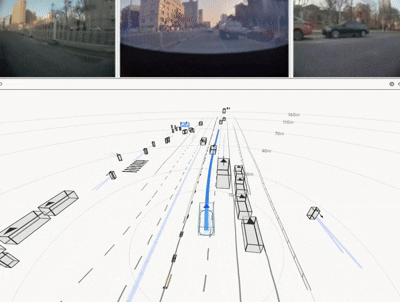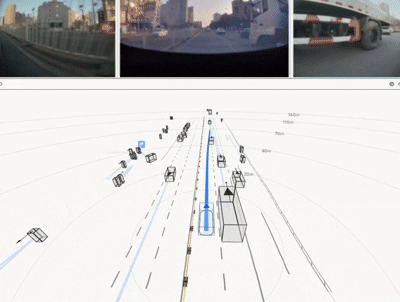
一句话总结
HDP通过充分的实车实验证明了经过精心设计和训练的扩散模型,可以成为自动驾驶的强大且可扩展的Planner。