过去半年来,AIR围绕智慧交通、智慧医疗、智慧物联三大研究方向开展系统深入的研究,并在CVPR、NeurIPS、ICLR和MobiSys等重要国际期刊和会议上发表50篇高水平论文。在最近的NeurIPS 2022会议上,AIR共计12篇论文被录用。
今天,小编就为大家精选了一些AIR近期的亮点论文,并梳理了摘要解读,文末可获取完整论文打包下载方式。
Discriminator-Guided Model-based Offline Imitation Learning
作者:张文嘉,徐浩然,牛浩懿,成鹏,李明,张和明,周谷越,詹仙园
单位:清华大学自动化系、京东科技、北京交通大学、AIR
摘要:离线模仿学习可以通过没有奖励标签的专家示例来解决决策问题,然而现有方法的性能在专家数据有限的情况下会严重退化。引入动力学模型可以潜在地提高数据的状态动作空间覆盖率,但是同时也面临着一些问题,例如模型泛化不足导致生成数据的次优性。为此研究团队提出了判别器引导的基于模型的离线模仿学习 (DMIL) 框架,该框架引入了一个判别器以同时区分模型生成数据与专家示例的真实性和正确性,并且采用了一种新颖的合作对抗学习策略,使用判别器来引导和耦合模仿策略及动力学模型的学习过程,从而提高模型的模仿性能和鲁棒性。这个框架也可以扩展到数据集中包含大量次优数据的场景。实验结果表明,在小数据集场景下DMIL及其扩展均取得较好的表现。

Flexible Neural Image Compression via Code Editing
摘要:神经图像压缩(NIC)在率失真(R-D)性能方面优于传统的图像编解码器。然而,它通常需要R-D曲线上的每个点都有专用的编解码器,大大阻碍了实际部署。虽然最近的一些工作已经通过条件编码实现了比特率控制,但它们在训练过程中施加了很强的先验,只提供了有限的灵活性。本文提出了码字编辑,一种基于半均摊推理和自适应量化的高度灵活NIC方法。研究团队的工作是可变比特率NIC的新范式。此外,实验结果表明,研究团队的方法优于现有的变码率方法,并且只需一个解码器即可实现ROI编码和多失真度量的折衷。

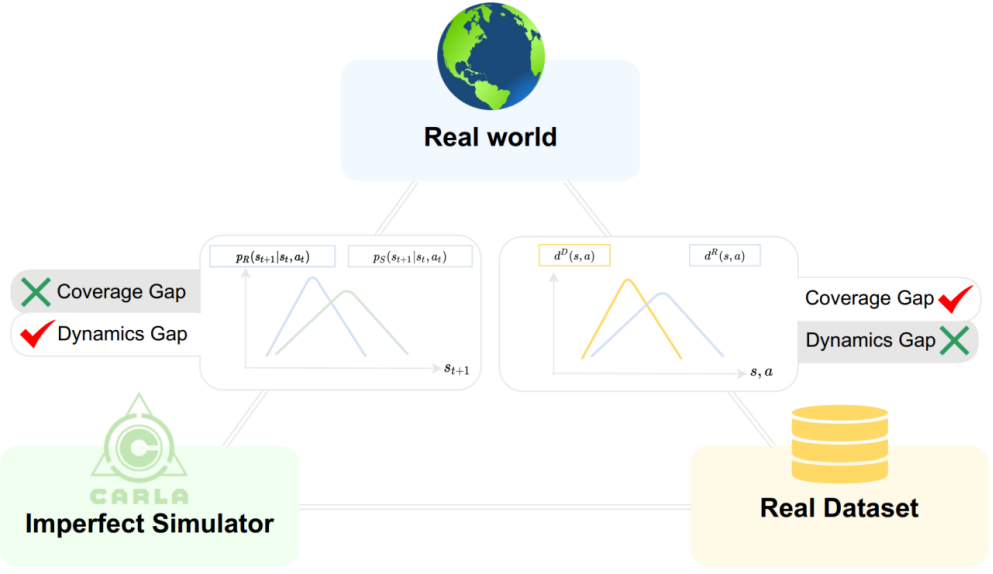
When to Trust Your Simulator: Dynamics-Aware Hybrid Offline-and-Online Reinforcement Learning
作者:牛浩懿、舒布哈姆·沙玛、邱亦文、李明、周谷越、胡坚明、詹仙园
单位:清华大学自动化系、印度理工大学孟买分校、AIR
会议:NeurIPS 2022
摘要:
机器人的决策训练十分依赖高保真度的仿真器,然而即便花费了大量人力物力去打造,现有仿真中的动力学偏差仍然广泛存在,严重影响了仿真中的策略学习和验证。近几年离线强化学习的兴起为直接绕过仿真器而用真实数据训练策略带来了可能,但是采集数据费时费力甚至可能造成危险,数据量和数据覆盖度也难以保证。因此,本文提出了一种考虑动力学偏差的离线在线混合强化学习方法——H2O,能够充分利用在仿真器中在线训练可以无限探索的优势和离线真实数据中正确的动力学信息。H2O中设计了考虑动力学偏差的策略评价新方式,可以根据仿真样本动力学偏差的大小来决定其对应价值的惩罚或奖励幅度,同时抬高真实样本对应的价值。通过大量的仿真和现实实验,团队证明了H2O相比于其他仿真到现实迁移方法和离线强化学习基线的优越性。凭借充分的理论分析,团队论证了H2O有潜力给未来实用型强化学习算法的设计提供更多启示。
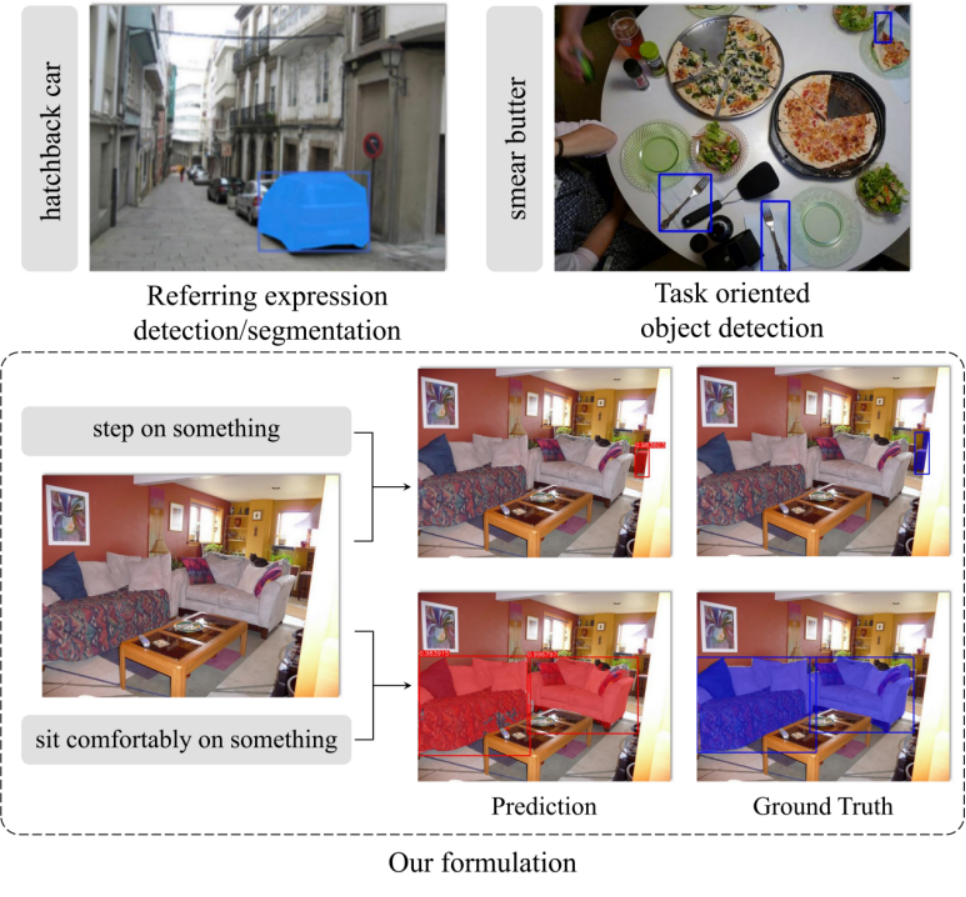
TOIST: Task Oriented Instance Segmentation
Transformer with Noun-Pronoun Distillation
作者:李鹏飞,田倍闻,石永亮,陈小雪,赵昊,周谷越,张亚勤
单位
:
AIR,清华大学计算机系,北京大学,英特尔研究院
摘要:目前的开集场景理解算法可以有效地对名词指称的对象进行目标检测或实例分割,但如何理解动词指称仍有待探索。因此,本文研究了极具挑战性的面向特定任务的目标检测问题,该问题旨在从一幅图片中检测到最适用于某一以动词描述的动作任务的物体,任务描述形式如“舒适地坐在上面”。同时,为了实现对物体更精细的定位以更好地服务于机器人交互等下游应用,研究团队将检测问题扩展到面向任务的实例分割。此问题的一个独特要求是在若干个可能的备选物体中选择 “最合适的”一个。因此,研究团队基于Transformer架构,利用注意力机制自然地对多个可选物体之间的关系进行建模,提出了TOIST方法。为了利用已有的大规模预训练的名词指称表达理解模型,并基于可在网络训练期间获取物体真实类别名词的事实,研究团队提出了一种新颖的名词-代词蒸馏框架。名词范例以无监督的方式生成,融合上下文信息的代词特征通过训练实现对名词原型的高效选择。因此,网络在推理过程中仍然与名词无关。本文在面向特定任务的大规模数据集COCO-Tasks上验证了TOIST,取得了比现有最好方法高10.7% mAP的目标检测结果。所提出的名词-代词蒸馏框架能够进一步提升2.6% mAP的目标检测性能以及3.6% mAP的实例分割性能。代码和模型见:https://github.com/AIR-DISCOVER/TOIST。
Molecule Generation by Principal Subgraph Mining and Assembling
单位:
AIR,清华大学计算机系,人民大学高瓴人工智能学院
摘要:
分子生成是涉及许多领域应用的重要任务。目前基于子图预测和组装的分子生成模式正在逐渐兴起。然而,在子图库的构建上,目前的方法多依赖于切割单键、抽取成环子图等人工规则或外部的化学结构库。在子图组装上,目前的方法多局限于局部的连接模式。在本文中,作者提出了principal subgraph(下简写为PS)这一新颖的概念,并发现PS可以捕捉分子中带有丰富信息的特定模式。本文同时提供了一种基于合并-更新的算法用于自动地从数据集中抽取高频出现的PS,并作为子图库用于后续的分子图生成。文中也对这一抽取算法的单调性、显著性、完备性进行了理论证明。同时,实验证明以这种方法构建的子图库比现有的其他方法更能提供数据集分子中的模式信息,从而提升模型生成分子的能力。进一步地,本文提出了一种两步式的子图预测和组装方法,以序列预测的方式确定要生成的子图,之后全局地将子图组装为完整的分子。大量实验显示,本文提出的基于PS子图库以及两步式生成框架的模型在效率和效果上相比现有方法都有显著的提升。
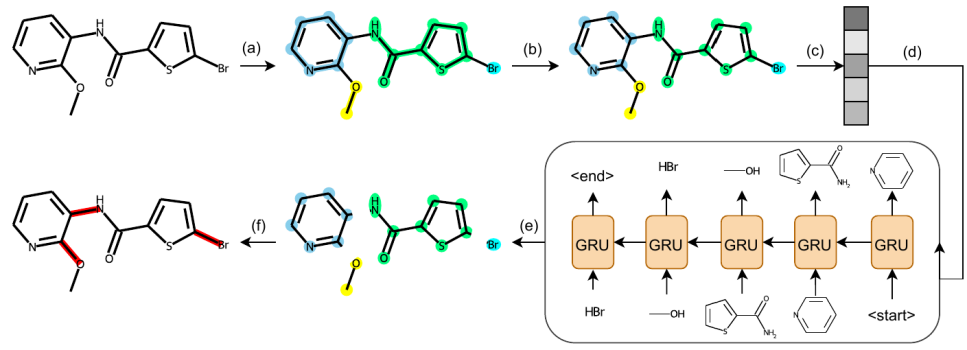
SNAKE: Shape-aware Neural 3D Keypoint Field
作者:
钟程亮,尤沛兴,陈晓雪,赵昊,孙富春,周谷越,慕晓冬,淦创,黄文炳
单位:
清华大学计算机系,AIR,北京大学,英特尔研究院
摘要:通常来说,从点云中检测 3D 特征点对于物体的重建很重要,而本文研究了一个反向问题:形状重建是否有利于 3D 特征点检测?现有方法大多根据不同阶数的统计特性,或者学习对刚性变换保持不变的特征点。然而,将形状重建结合到 3D 关键点检测中的想法尚未得到充分探索。本文认为这受到以前对该问题求解范式的限制。为此,本文提出了一种名为 SNAKE 的新型无监督范式,它是shape-aware neural 3D keypoint field 的缩写。与最近基于坐标的辐射场或距离场类似,本文提出的网络将 3D 坐标作为输入,同时预测隐式的点云表面形状和关键点显著性,从而自然地将3D 关键点检测和形状重建两个任务紧密耦合。本文在多个公共基准测试中展现了该方法的优越性能,包括物体数据集 ModelNet40、KeypointNet,人体数据集SMPL 和场景数据集 3DMatch 和 Redwood。具备物体内在形状感知的设计带来了以下几个优点:(1) SNAKE可以生成与人类按物体语义标注近似的关键点,即使在训练中没有提供这样的监督信息。(2) SNAKE 在可重复性方面优于其他基线方法,尤其是在对输入点云进行下采样时。(3) 生成的关键点适配于点云的配准任务,尤其是在zero-shot的设置下。代码和模型见:https://github.com/zhongcl-thu/SNAKE。

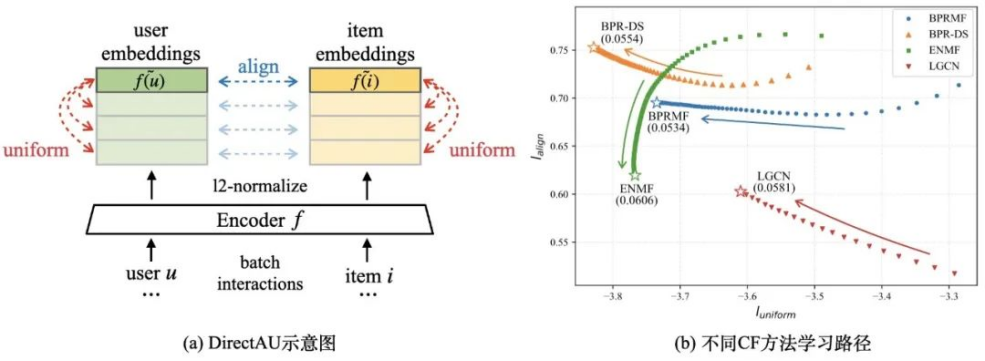
Towards Representation Alignment and Uniformity in Collaborative Filtering
作者:
王晨阳,庾源清,马为之,张敏,陈冲,刘奕群,马少平
摘要:推荐系统中协同过滤算法往往依据用户与待推荐项间的交互行为学习用户和待推荐项在同一空间的向量表示,之前的研究主要关注得到用户和待推荐项表示的不同方法,很少有工作分析用户和待推荐项表示的理想分布情况。本文从对比学习中常用的 alignment 和 uniformity 性质出发,首先理论上揭示了推荐中常用的 BPR 损失函数与这两个性质之间的关系;其次通过实验分析了不同类型 CF 方法在训练时用户和待推荐项表示的 alignment 和 uniformity 如何变化,发现诸如难负例、图神经网络、非采样等改进 CF 的方法都在以不同的方式提升表示的 alignment 或 uniformity 性质,从而达到更好的推荐效果。基于以上理论分析和实验观察,研究团队提出 DirectAU 来直接优化用户和待推荐项表示的这两个性质,实验发现该优化目标结合基本的矩阵分解模型就能够显著优于 SOTA 推荐方法,还拥有无需负样本采样、无需图神经网络等复杂编码器的优势,为隐式反馈下用户和待推荐项的个性化建模学习提供了新的思路。
Knowledge Inheritance for Pre-trained Language Models
作者:
秦禹嘉,林衍凯,易靖,张家杰,韩旭,张正彦,苏裕胜,刘知远,李鹏,孙茂松,周杰
摘要:近年的研究表示,大规模预训练语言模型在下游任务上的效果与模型参数呈正相关性,因而训练越来越大的预训练语言模型成为重要趋势。然而,大规模预训练语言模型的训练需要消耗大量的计算资源,耗时且昂贵;并且,目前的大规模预训练语言模型大多是从头开始训练的,忽略了业已训练完成的预训练语言模型的可复用性。本文中重点讨论了如何利用已有预训练语言模型来加速大规模预训练语言模型训练的问题。具体的,研究团队提出了名为“知识继承”( Knowledge Inheritance,KI)的预训练框架,并探讨了如何利用知识蒸馏技术在预训练期间基于已有的预训练语言模型为训练过程提供辅助监督信号,进而提升大规模预训练语言模型的训练效率。实验结果显示了知识继承框架的有效性。同时研究团队还系统全面地分析了模型架构、预训练数据等因素对知识继承框架效果的影响。最后,本文实验结果也表明知识继承框架在跨领域适配和知识迁移等方向也具有很好的应用价值。

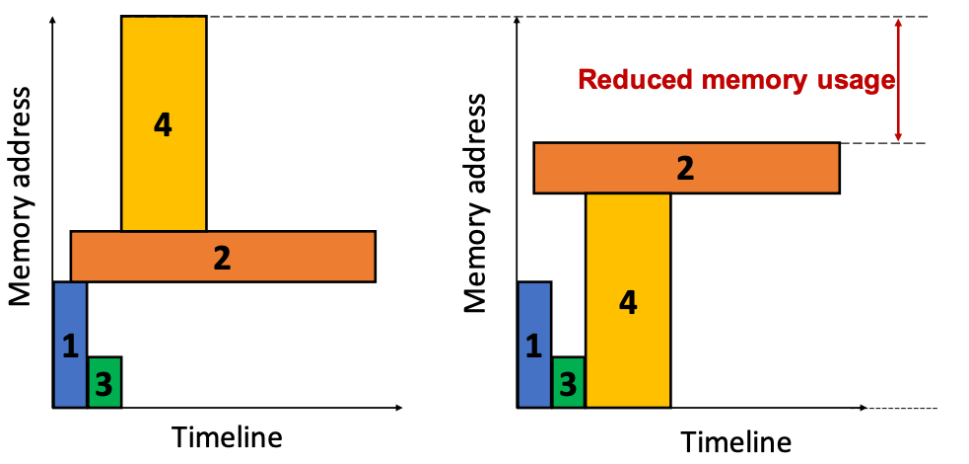
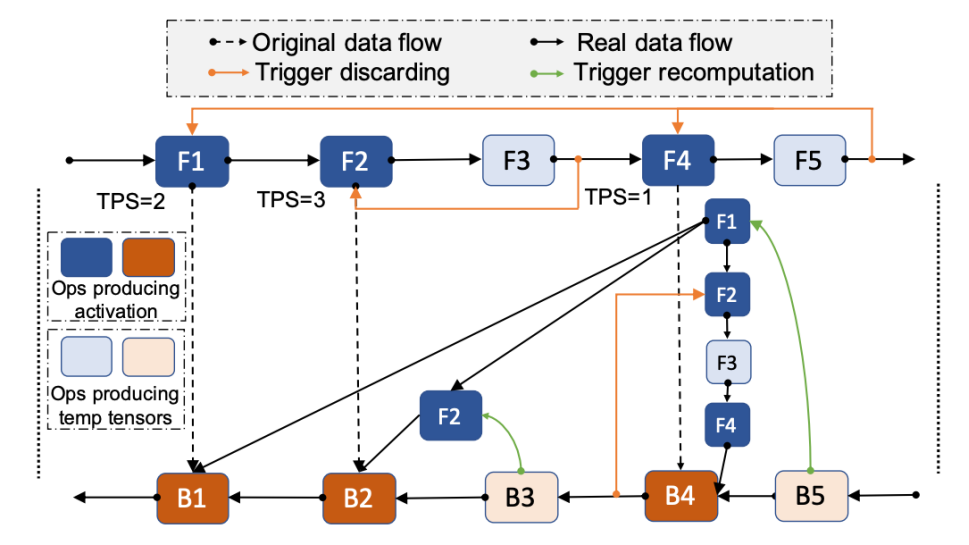
Melon: Breaking the Memory Wall for Resource-Efficient On-Device Machine Learning
作者:王启鹏,徐梦炜,金超,董欣然,袁进良,金鑫,黄罡,刘云新,刘譞哲
摘要:随着人们对数据隐私的重视,端上设备学习成为机器学习领域内一项很有前景的技术。然而,现有的商用移动端设备由于存储容量的限制无法支持较大批量数据的DNN训练。为了解决这个问题,研究团队提出了一种内存友好的端设备上学习框架Melon,它可以支持超出物理内存容量的大批量数据DNN训练任务。Melon精细地改进了现有的内存管理技术以匹配资源受限的移动端设备,同时也采用了新的技术来处理内存碎片化等一系列相关问题。该问题有三大挑战:1)如何减少端上设备训练过程中严重的内存碎片化 2)如何使得预分配内存池的大小和张量的生命周期相匹配3)基于移动端设备多任务的环境如何动态地分配内存。研究团队在商用移动设备上使用各种典型的DNN模型实施和评估Melon。结果表明,在相同的内存预算下,Melon可支持4.33倍的批量大小数据的DNN训练。在相同的批量数据下,Melon的DNN训练平均吞吐量提高了1.89倍(最高可达4.01倍),可节省49.43%的能量消耗。

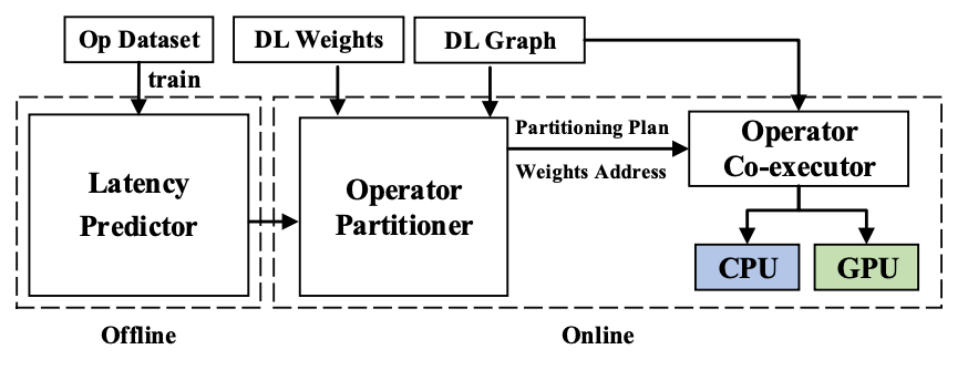
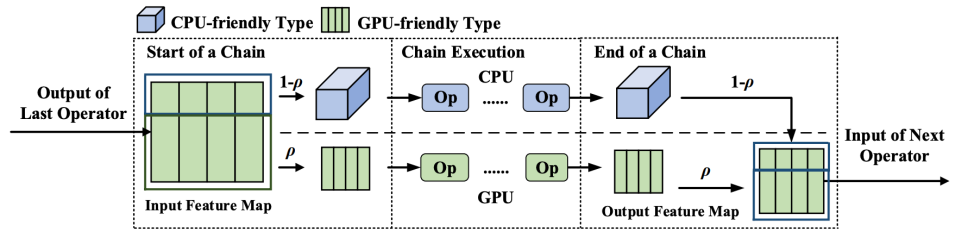
CoDL: Efficient CPU-GPU Co-execution for Deep Learning Inference on Mobile Devices
作者:贾富程,张德宇,曹婷,姜世琦,刘云新,任炬,张尧学
单位:
中南大学,MSRA,AIR, 清华大学计算机系
摘要:异构处理上的深度神经网络的并发推理执行对于提升日益庞大的模型推理性能至关重要。然而,现有的推理框架每次只能利用一个处理器或者即使利用多个处理器并发执行也无法获得明显的加速效果。关键挑战在于1)如何减小数据共享开销2)如何在不同的处理器之间合理划分算子。为了解决这些问题,研究团队提出了CoDL, 一种针对移动端CPU和GPU的深度学习并发推理框架,从而可以充分利用不同的处理器资源加速模型的推理计算。研究团队主要采用了两种新技术:1)混合类型数据共享,使得每个处理器都能够利用最高效的数据类型做推理 2)兼顾非线性和并发性的时延预测,通过建立一个针对不同处理器的超轻量且准确的时延预测器,对模型算子进行合理地切分。研究团队在常用的DL模型上做了评估,实验结果表明,与目前最好的并发推理框架相比,CoDL可以实现4.93倍的推理加速,节约62.3%的能量消耗。
FedBalancer: Data and Pace Control for Efficient Federated Learning on Heterogeneous Clients
作者:
Jaemin Shin,李元春,刘云新,Sung-Ju Lee
摘要:联邦学习 (Federated Learning, FL) 在不暴露个人数据的前提下分布式地在客户端上训练机器学习模型。与基于精心组织的数据的集中式训练不同,FL处理的通常是未经过滤且不平衡的设备上数据。因此,对所有数据一视同仁的传统FL训练方式会导致计算资源的浪费、减慢学习过程。为了解决这个问题,研究团队提出了FedBalancer框架,可以主动选择客户端上的训练样本,来平衡不同客户端之间的负载。FedBalancer在考虑到隐私和客户端计算资源的前提下,优先选择包含更大信息量的样本。为了更好地利用样本选择来加速全局训练,研究团队进一步引入了一种自适应期限调控技术,它可以根据不同的客户端训练数据预测每一轮的最佳期限。与现有的FL期限调控算法相比,在来自3个领域的5个数据集上的评估表明,FedBalancer将达到给定准确率的时间缩短了1.20~4.48倍,同时将模型准确率提高了1.1%~5.0%。此外,当FedBalancer与3种不同的FL算法联合操作时都能提高收敛速度和准确率,这说明FedBalancer能够较为容易地迁移到其他FL算法中。
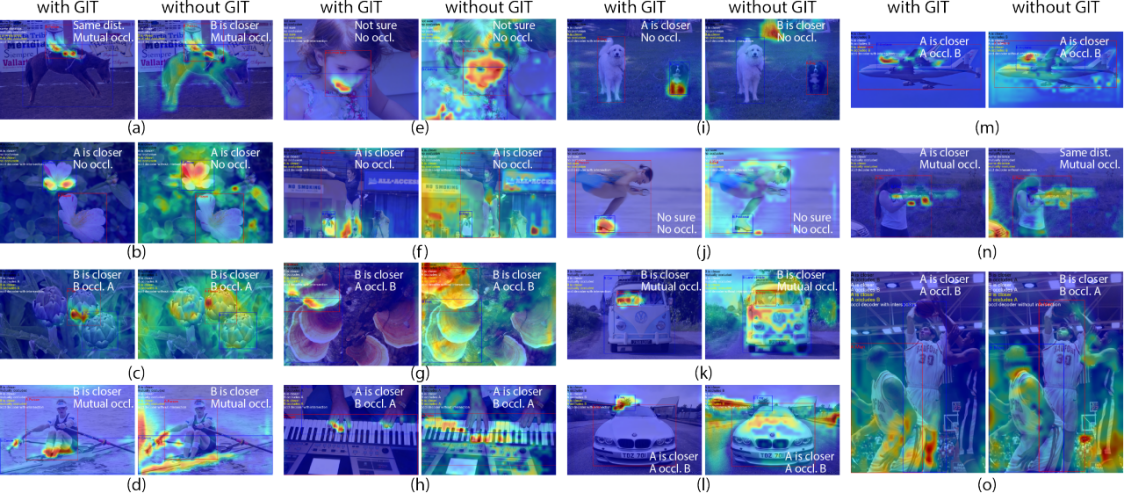
Distance-aware Occlusion Detection with Focused Attention
单位:
AIR
、UCSD、北京大学、英特尔研究院
期刊:
IEEE Transactions on Image Processing
摘要:对于人类来说,基于视觉信号理解物体之间的关系是自然而然的。然而,对于人工智能来说,这项任务仍然具有挑战性。前人工作在语义关系检测方面取得了重大进展,如人物交互检测和关系检测。本文将视觉关系的研究从语义层面进一步扩展到几何层面。具体来说,本文预测相对遮挡和相对距离关系。然而,从单张图片中检测这些关系具有挑战性,强化对特定任务区域的集中注意力对于成功检测这些关系至关重要。在这项工作中,(1)研究团队提出了一种新的三解码器架构作为注意力的框架;2) 研究团队使用广义交集框预测任务(GIT)来有效地引导模型关注遮挡相关区域;3) 研究团队的模型在遮挡和相对距离关系检测方面取得了迄今最好的性能。具体而言,研究团队的模型将相对距离的F1分数从33.8%提高到38.6%,并将遮挡的F1分数从34.4%提高到41.2%。本文的代码和数据已公开:https://github.com/Yang-Li-2000/Distance-Aware-Occlusion-Detection-with-Focused-Attention.git