AIR刘云新教授有4篇论文被收录MobiCom 2021,是本届会议被收录数最多的作者。刘云新教授近年来致力于智能边缘计算的研究,本次入围的4篇论文都与该研究方向有关,这些工作与微软研究院、南京大学、中国科学技术大学、西安交通大学、上海交通大学、美国Rutgers大学等单位合作完成。
MobiCom(International Conference on Mobile Computing and Networking)是移动计算和网络领域的国际顶级学术会议,也是CCF的A类会议,至今已举办了27届。由于疫情原因,原定于2021年举办的第27届MobiCom大会推迟到了今年的3月28日 - 4月1日,以线下和线上结合的方式进行。
MobiCom 2021大会共计收录60篇论文,其中按第一作者署名单位所在地统计,中国有22篇论文被收录[1],与美国并列第一。按署名单位统计[2],清华大学有6篇论文被收录,与微软公司并列第一。
*数据来源:acm.org(https://dl.acm.org/action/showFmPdf?doi=10.1145%2F3447993)
[1]含微软亚洲研究院一篇。
[2]含非第一作者。

标题:AsyMo: Scalable and Efficient Deep-Learning Inference on Asymmetric Mobile CPUs
作者:王曼妮,丁劭华,曹婷,刘云新,许封元
CPU 是移动端侧最主要的计算资源,目前端侧大部分模型推理也都在 CPU 完成。端侧 CPU 多采用大小核的异构多核架构,以同时满足低能耗和高性能的需求。但当增加小核硬件资源时,现有的模型推理实现并不能取得相应的性能加速(如下图左),而且还浪费了宝贵的硬件资源。

(左)Kirin970 上加上小核后部分框架推理时间不降反增;(右)MobilenetV1 推理过程中频率响应不及时。
AIR刘云新教授与合作者们分析发现该问题是由于推理运行时各个核上不均衡的任务分配所导致。比如在运行常用的 CNN 模型时,平均的小核利用率甚至不足10%,大核利用率也只有70%左右。现有的各种端侧推理实现仍然沿用传统的服务器端同构并行任务划分的方式,没有考虑异构多核在计算和数据访问能力上的差异,以及端侧硬件资源有效性,因此 CPU 利用率很低。
此外,在能耗方面,作者们也发现,由于缺乏对执行任务的理解,现有操作系统的动态电压频率调节(DVFS)不能及时对推理执行做出响应(如上图右),推理的开始和结束与 CPU 频率(即上图中功耗)的升降并不匹配,而且 DVFS 也无法找到最低能耗的 CPU 频率,所以造成了额外的能耗开销。
为了解决以上问题,作者们提出了 AsyMo 解决方案,通过高效利用端侧异构多核 CPU 来加速模型推理的工作。AsyMo 充分考虑了端侧 CPU 的异构性、缓存资源的有限性和执行环境的不确定性,结合推理执行的确定性、算子的易并行性和计算/访存的密集性,实现了基于延迟开销模型的任务划分策略、面向异构的任务调度策略和最优能耗频率设置策略三个关键技术。
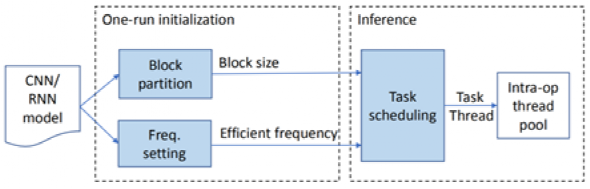
AsyMo 工作流程图
并行任务划分对模型推理性能有很大影响,为了找到在大小核上最合适的任务大小,作者们通过分析不同任务大小对并行度、访存和任务调度开销等带来的影响,构建了任务大小和延迟开销的关系模型,利用该模型可以直接计算得到大小核上延迟最小的任务尺寸。当模型运行时,面向异构的任务调度会将这些划分好的任务公平地分配到相应的大核或小核上执行,并根据各个核运行的情况适时地调整任务分配,以达到各个核的任务均衡。整个划分和执行过程如下图所示。因此,在 AsyMo 的作用下,推理执行过程中各个核所执行的任务数与其计算能力一致,并使各个核的利用率都提升到了90%以上。

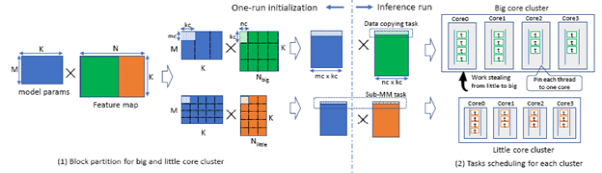
矩阵乘算子的初始化任务划分和运行时的任务调度图
对于能耗方面,AsyMo 根据目标深度学习模型的数据重用率,以及 CPU 在不同频率下的计算和访存能耗曲线,为不同深度学习模型确定了推理执行的能耗最低频率。该方法既消除了 DVFS 响应不及时所带来的错位,也使 AsyMo 在延迟降低的同时大幅度节约了能耗。(*以上内容根据微软亚洲研究院论文解析整理)
标题:Elf: Accelerate High-resolution Mobile Deep Vision with Content-aware Parallel Offloading
作者:张午阳,何哲陟, 刘路阳, 贾振华, 刘云新,Marco Gruteser, Dipankar Raychaudhuri, 张燕咏
AIR刘云新教授与合作者们发现通过分割图片视频来利用多服务器进行并行计算是可行的更优加速方式。但简单的均匀分割方式可能会将完整的物体切割成碎片,从而降低模型的精确度。同时这种方式还可能会让不包含任何物体的切片上传至服务器,从而造成网络资源和计算资源的浪费。此外,如何有效地匹配切片的计算复杂度,以及服务器当前的计算资源也是很大的挑战。
为此,作者们通过高效的任务分割,利用多边缘云服务器的并行计算以加速模型推理,并提出了名为 Elf 的解决方案。Elf 充分考虑了推理任务的计算复杂度,图片视频中候选区域的位置、计算需求分布以及多个边缘云服务器网络、计算资源的动态不确定性,重点实现了候选区域的高速追踪预测、基于候选区域的视频流分割,和基于多边缘云服务器性能感知的并行上传计算。
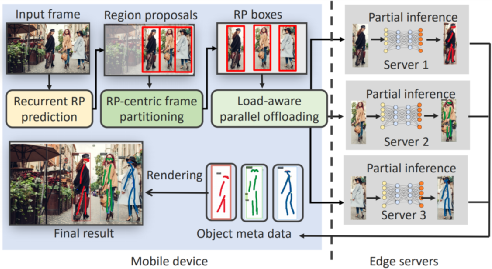
Elf 系统工作流程图
在移动端,Elf 系统根据候选区域在历史视频帧的位置分布,通过轻量级的注意力 LSTM 深度学习网络,而不是主流的高复杂度的基于卷积神经网络的模型,来预测当前帧中的候选区域的位置。同时,为了提升预测的精确度,作者们还提出了候选区域快速匹配,以及低像素补偿的方法。
在视频流分割上,作者们提出了内容认知、计算复杂度认知,以及网络计算资源认知的方法。内容认知可以帮助分割候选区域的完整性,从而不影响应用的精确度,并有效移除无关的背景区域;计算复杂度认知可以帮助考虑分割碎片的异构计算资源需求,进而实现多边缘云计算服务器的负载均衡;网络计算资源认知则可以帮助考虑边缘云计算服务器高动态的资源变化,以减少计算瓶颈情况的出现。
总的来说,Elf 系统通过以上步骤,可有效地在移动端将视频帧分割成多碎片,再上传至多个边缘云服务器进行并行计算,来大幅提升计算速度,同时不影响视觉应用的精确度。(*以上内容根据微软亚洲研究院论文解析整理)
Elf 系统中视频帧分割的流水线作业
标题:PECAM: Privacy-Enhanced Video Streaming and Analytics via Securely-Reversible Transformation
作者:吴昊, 田雪津, 李明昊, 刘云新,Genesh Ananthanarayanan, 许封元, 仲盛
视频流分发与智能分析(Video Streaming & Analytics,VSA)系统(如下图所示)近年来被广泛部署,并且在智慧城市、居家安防、养老看护等应用场景中发挥了重要的作用。但越来越多的无死角摄像区域容易造成人们的焦虑和压迫感,特别是引起人们对个人和空间隐私泄漏的担忧。如何在 VSA 系统中平衡出色的分析能力与视觉的隐私保护就成了一个十分重要并具有挑战的研究问题。具体来讲,就是需要做到在保证 VSA 的分享观看、智能分析、和调查取证的服务质量的同时,有效且实时地增强视觉隐私信息的保护。
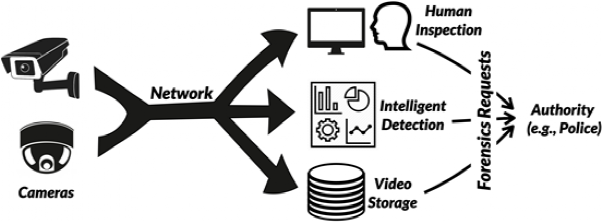
常见的视频流分发与智能分析系统。视频流分析系统通常包含两个主要部分,前端视频源和后端订阅用户。前端视频源通过网络将实时视频流传输到相应的后端订阅用户。后端订阅者会对视频进行分享观看/人工检查、智能检测以及数据存储。当被授权时,授权方可以利用视频流进行取证,比如进行犯罪现场分析。
针对上述问题,作者们提出了一种基于深度学习的、可安全恢复的视觉信息变换及隐写 PECAM,并利用该技术设计了较为通用的 VSA 隐私增强架构及系统实现。
PECAM 可以实时运行在智能摄像头上,无需对后端服务改动,保证了 VSA 的功能,减少了带宽要求,还能够抵御非法的隐私视频恢复。
下图展示了将 PECAM 应用在交通监控场景中进行事故检测的工作样例:左侧被监控摄像头所采集到的原始视频帧中包含了车牌号,车牌号对于多数司机来说是敏感信息,但这些信息并不影响事故检测的结果。
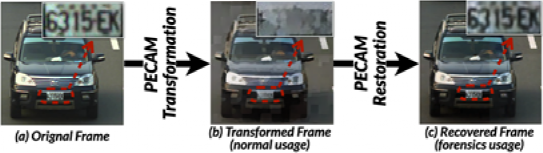
配备 PECAM 的 VSA 系统中的视频帧。PECAM 的隐私保护是应用于整帧的。在平时分析时,PECAM 可以隐去隐私信息,而在合法取证时,PECAM 则可以重建隐私信息。
PECAM 系统可以有效的把该原始视频转换成类似于卡通的隐私保护视频,此时车牌号会被保护起来但车的形状依然是可以辨识的。当在保护后的视频中检测到交通事故时,被授权的工作人员,如警察,则可以将该保护后的视频重建成原始视频,从而完成调查取证。值得一提的是,PECAM 去掉的是监控画面中所有物体的细节而不仅仅是车牌号。
支撑PECAM 实现安全可逆变换的是一个安全增强的生成对抗模型,研究员们还引入了密钥机制来保证 PECAM 保护后的视频无法被攻击者还原。下图是以 Alice 的 PECAM 系统为例展示了该对抗网络的工作流程。在运行时,Alice 的编码器(Encoder)会实时地对视频进行隐私保护,被保护后的视频可以用于人工检查、智能分析和存储以备回溯分析。
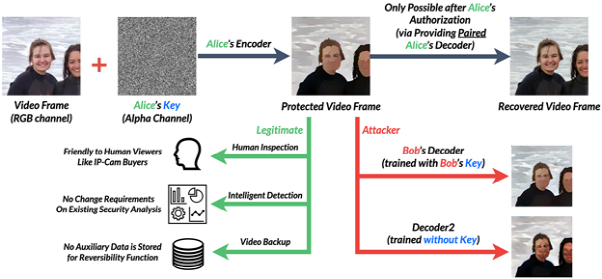
安全增强的生成对抗模型的工作流程
在得到 Alice 授权后,就可以用 Alice 的解码器(Decoder)从被保护的视频中重建出原始视频,该重建过程不需要借助任何额外存储的数据。实验显示,未经授权的攻击者难以非法还原 Alice 保护后的视频。因此,该模型能够帮助 PECAM 解决 VSA 系统中事故发现前视觉隐私信息保护与事故发现后个体标识信息取证之间的需求矛盾。
此外,PECAM 系统针对隐私保护视频优化了网络带宽使用,在相同传输数据质量的情况下,PECAM 的带宽效率是H.264的1.8倍。PECAM 同时对系统运行性能进行了优化,其运行延迟满足 VSA 前端源的实时要求,比流行的 CycleGAN 和 YoloV3 的计算速度分别快12.3倍和46.8倍。(*以上内容根据微软亚洲研究院论文解析整理)
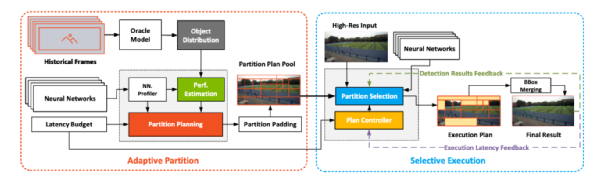
标题:Flexible High-resolution Object Detection on Edge Devices with Tunable Latency
作者:姜世琦, 林郅琦, 李元春,舒元超, 刘云新
在许多视频分析的场景中,人们发现相比于使用云服务,如果可以在边缘设备,如智能摄像头上直接运行目标检测模型,将会带来诸多便利,包括更低的网络延迟、更少的带宽使用、更低廉的部署和使用成本、更好的隐私保护等等。然而边缘设备上的运算资源非常有限,如何使其可以运行计算密集的 DNN 充满了挑战。
与此同时,近些年来高分辨率相机的成本越来越低,大量装配与部署 4K 甚至 8K 摄像头的设备屡见不鲜。高分辨率设备带来更清晰画面细节的同时,也要求使用更大规模的 DNN 来进行处理,进而就导致了在边缘设备更高的推理延迟。
一方面是有限的计算资源,另一方面则是快速准确的目标检测需求。为了弥合这一差距,AIR刘云新教授与合作者们最近作出了一些尝试,提出了名为 Remix 的计算框架,在充分分析和利用现有模型多样性能力的基础上,通过对有限计算资源的合理分配调度,实现了灵活可调谐的高分辨率目标检测。在给定的任一边缘设备上,Remix 都会试图找到最佳运行方案,以保证在不超过设定延迟约束的前提下,达到最佳检测性能。经评估,与 SOTA 目标检测模型相比,Remix 在多种边缘设备上到达相同检测性能时可以加速推理最高达8.1倍;同时,在相似延迟约束下,Remix 也可以取得平均65.3%的检测准确率增幅。(*以上内容根据微软亚洲研究院论文解析整理)
AIR刘云新教授4篇论文入选MobiCom'21,收录数量位列第一