AIR自成立以来,围绕智慧交通、智慧医疗、智慧物联三大研究方向开展系统深入的研究,在美国科学院院刊(PNAS)、CVPR、NeurIPS、ICLR和MobiSys等重要国际期刊和会议上发表88篇高水平论文,研究成果获得MobiSys 2021最佳论文奖、CVPR 2021最佳学生论文奖提名、AAAI-IAAI 2022人工智能创新应用奖等奖项。
今天,小编就为大家精选了12篇近期AIR发表的亮点论文,做一期摘要解读,文末可获取完整论文打包下载方式。
DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection
作者:俞海宝,罗弈桢,舒茂,霍漪漪,杨泽邦,时一峰,郭正龙,李晗禹,胡星,袁基睿,聂再清
单位:AIR、百度、清华大学计算机系、中国科学院大学
会议:CVPR 2022
摘要:单车自动驾驶存在驾驶盲区、中远距离感知不稳定等问题,因而在落地时面临安全性等巨大挑战。融合路侧信息的车路协同自动驾驶将是保障自动驾驶安全运行的必由之路。然而当前车路协同领域缺少来自真实场景的公开数据,为促进学术界和产业界共同打造数据驱动的车路协同自动驾驶,团队公开车路协同自动驾驶数据集DAIR-V2X。DAIR-V2X数据集是首个采自真实场景的大规模(一共71254帧,并全部进行3D标注)、多视角(包含车端与路端及相同时空下的联合视角)、多模态(包含图像和激光点云)数据集。另外数据集还提供了车端与路端联合视角下的融合标注结果,用于更好地服务车路协同算法研究和评估。同时为方便学术界基于DAIR-V2X数据集开展学术研究,团队还从车路协同实际需求出发定义了车路协同3D检测任务-VIC3D Object Detection,即在通信带宽约束下车端融合路端信息进行3D检测。该问题有三大挑战:1)如何融合路端信息以提升3D检测精度;2)如何减少路端数据传输以减少通信带宽消耗;3)如何解决由于时延等带来的时空误差问题。同时团队还提供了完备的车路协同3D检测和单端(车端与路端)3D检测的Benchmark,以作为算法研究基准。目前DAIR-V2X数据集已经可以公开下载(下载链接:https://thudair.baai.ac.cn/index),团队也将于近期公开Benchmark所有相关实现代码。该工作得到北京市高级别自动驾驶示范区、北京车网科技发展有限公司、百度Apollo和北京智源人工智能研究院等单位的大力支持。
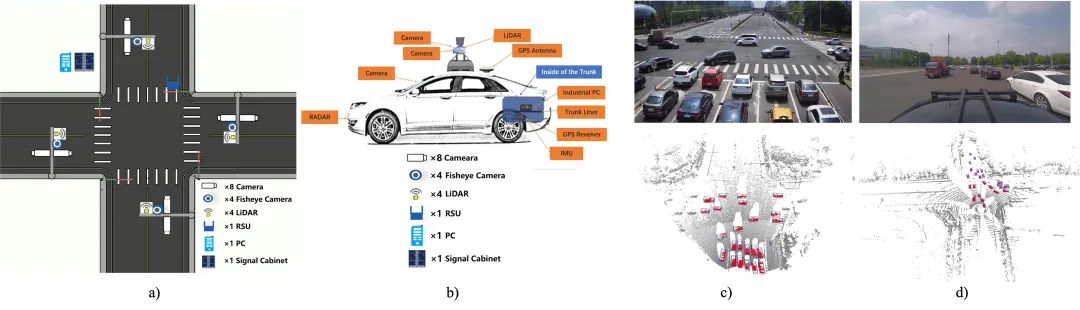
Constraints Penalized Q-Learning for Safe Offline Reinforcement Learning
作者:徐浩然、詹仙园(通讯作者)、朱翔宇
单位:京东科技、AIR、西安电子科技大学
会议:AAAI 2022
摘要:离线强化学习是近年来强化学习研究的热点方向,其目标是直接从收集的大量历史数据中学习策略,而不和真实环境进行交互,这是使得强化学习能够应用于真实世界的最佳路径。然而,将离线强化学习应用在真实世界时必须要考虑到安全因素的影响,现有的工作难以在满足安全约束和最大化奖励价值中取得平衡,容易导致策略出现过保守或者欠保守的现象。
为了解决这一问题,本文提出了一种新的基于约束值惩罚的Q学习算法CPQ。首先在用数据集拟合风险Q函数时加上一个额外的损失项,该损失项会将偏离数据分布的动作的风险Q函数值升高;然后在更新价值Q函数的目标值时,在原来的贝尔曼方程上乘上一个是否满足约束条件的指示函数,通过该指示函数,隐式地将数据分布外和不满足安全约束的动作的价值Q函数变小;最后在学习策略时,和常见的Actor-critic算法一样,让策略朝着能使得价值Q函数值最大的方向更新。
文章中从理论上证明了所提方法的收敛性以及与最优安全策略价值差的上界,并在不同种类的离线数据集上验证了CPQ的有效性。实验证明团队的方法在奖励最大化和训练稳定性上均优于其他基准算法,并且对于安全约束限制值的改变表现出鲁棒性。
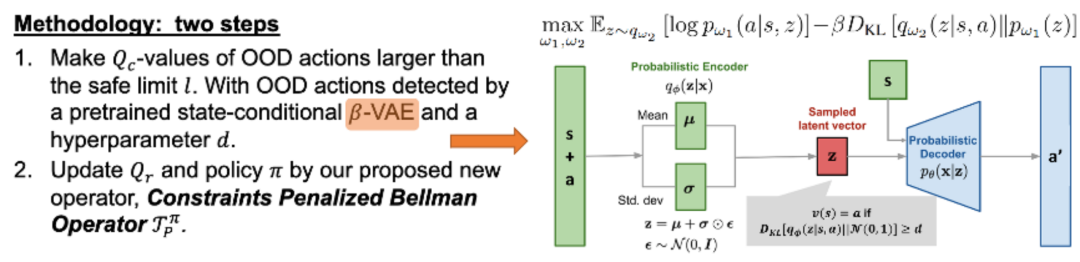

Cerberus Transformer: Joint Semantic, Affordance and Attribute Parsing
作者:陈小雪,刘天瑜,赵昊,周谷越,张亚勤
单位:AIR,香港科技大学,北京大学,英特尔研究院
会议:CVPR 2022
摘要:多任务室内场景理解是计算机视觉的一个重要研究方向,与单任务模型相比,利用不同任务间的相关性可能会提高各个任务的性能。在本文中,团队提出并解决了语义、可供性和属性联合解析的新问题。成功地解决这个问题需要一个模型来捕捉长程依赖,从弱对齐的数据中学习,并在训练期间适当地平衡子任务。为此,团队提出了一个名为 Cerberus 的基于注意力的架构和其适配的训练框架。团队的方法有效地解决了上述挑战,并在所有三个任务上取得了最先进的性能。此外,深入分析显示团队的模型体现了与符合人类认知的子任务相关性,这激发了团队探索弱监督学习的可能性。令人惊讶的是,Cerberus 仅使用 0.1%-1%的标注就获得了较强的结果,可视化进一步证实,这种成功归功于跨任务的共同注意力机制。代码和模型见:https://github.com/OPEN-AIR-SUN/Cerberus 
PQ-Transformer: Jointly Parsing 3D Objects and Layouts from Point Clouds
作者:陈小雪,赵昊,周谷越,张亚勤
单位:AIR,北京大学,英特尔研究院
会议:RA-L+ICRA 2022
摘要:基于点云的三维场景理解对于各种机器人应用起着至关重要的作用。不幸的是,当前最先进的方法通常使用单独的神经网络来完成不同的任务,例如三维目标检测或房间布局估计。这样的方案有两个限制:1)对于一般机器人平台来说,为不同的任务存储和运行多个网络是昂贵的。2) 单任务网络输出的结果可能忽视了不同任务间的内在联系和约束。为此,团队提出了第一个使用点云输入同时预测 3D 目标和布局的Transformer网络。与现有的布局估计方法不同,团队直接将房间布局参数化为一组四边形。因此,所提出的架构被称为 P(oint)Q(uad)-Transformer。除四边形表示之外,团队还提出了一种适配的物理约束损失函数,可以阻止对象与布局出现相交的现象。在ScanNet数据集上的定量和定性结果表明,PQ-Transformer可以成功地联合解析物体和布局。而且,新的物理约束损失可以提高准确率,房间布局的 F1-score 从 37.9%显著提升到 57.9%。代码和模型见:https://github.com/OPEN-AIR-SUN/PQ-Transformer。

Deep Learning Guided Optimization of Human Antibody Against SARS-CoV-2 Variants with Broad Neutralization
作者:单思思,罗世通,杨子卿,洪俊贤,苏雨峰,丁凡,傅莉莉,李晨雨,陈鹏,马剑竹,史宣玲,张绮,Bonnie Berger,张林琦,彭健
单位:清华大学医学院,华深智药生物科技(北京)有限公司,伊利诺伊大学厄巴纳-香槟分校,麻省理工学院,AIR
期刊:PNAS
摘要:通过突变,病毒可以逃逸人体免疫系统的攻击,而开发用于疫苗和治疗的广谱中和抗体仍是很大的技术挑战。面对新冠病毒变种,包括已被批准紧急使用(EUA)的许多中和抗体,都减弱甚至失去了中和能力。在此,团队引入了一种能有效增强抗体对病毒的亲和力的几何深度学习算法,以提高抗体对病毒变种的广谱中和能力。通过优化人源抗体P36-5D2,一种能中和新冠病毒阿尔法,贝塔,伽马变种但无法中和德尔塔变种的抗体,团队展示了方法的有效性。
团队的几何深度神经网络改造优化了该抗体互补决定区域(CDR)的序列,有效提高了其对多个新冠病毒变种的亲和力。经过多轮优化与实验测量,团队能扩展该抗体的中和谱,并以10到600倍增强了其对包括德尔塔变种在内多个新冠病毒变种的亲和力。新冠奥密克戎变种在抗原表位上有两个突变位点逃逸抗体的结合,而团队也进一步阐述了我们的方法能有效侦测抗体互补决定区的改变,以减弱病毒突变对抗体结合的影响。这些结果突出展示了团队的深度学习算法在抗体优化上的强大能力,并有极大潜力被应用在其他蛋白质优化改造工程中。经过优化的抗体也将有极高潜力被用于作为针对当前各类新冠病毒变种的抗体药。
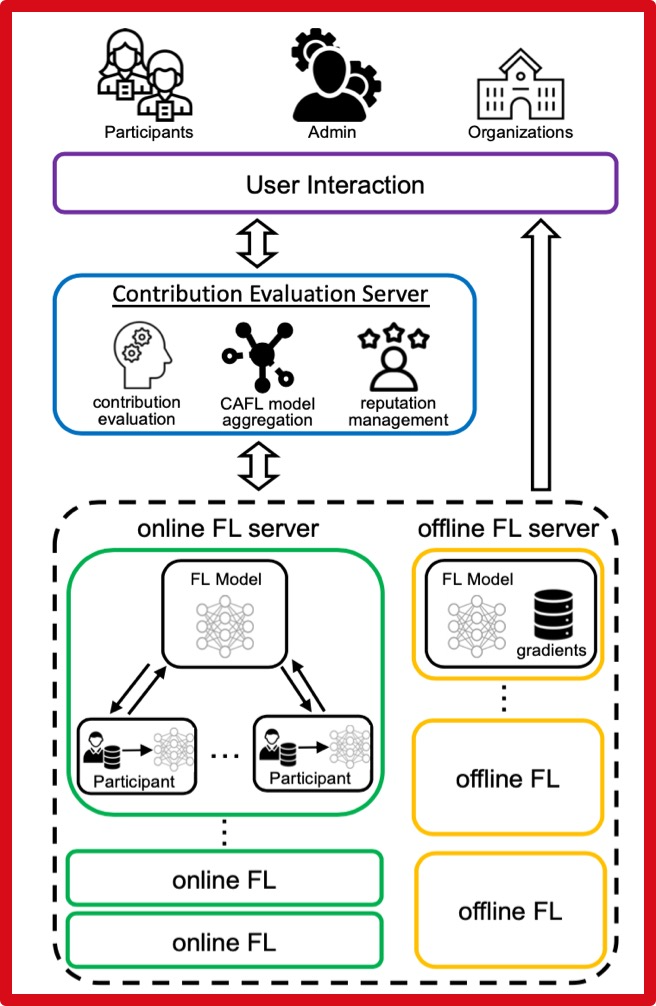
Contribution-Aware Federated Learning for Smart Healthcare
作者:Zelei Liu, Yuanyuan Chen, Yansong Zhao, Han Yu, 刘洋,包仁义,蒋锦鹏,聂再清,徐倩,杨强
单位:新加坡南洋理工大学,AIR,医渡云,微众银行
会议:AAAI-IAAI 2022
奖项:AAAI-IAAI 2022人工智能创新应用奖
摘要:在文章中,研究团队联合提出了一个贡献感知联邦学习框架,并在医渡云的真实业务场景中得到了验证。框架在不暴露私人数据的情况下,提供了一种有效和准确的方法来公平地评估联邦学习参与者对模型性能的贡献,并改进了联邦学习模型训练协议,允许将表现最好的中间模型分配给联邦学习训练的参与者。研究发现,模型对联邦学习贡献度的分析评估为原有方法提速2.84倍。同时,模型更是将准确度提升了2.62%,为智慧医疗健康的产业应用带来显著提升。
Equivariant Graph Mechanics Networks with Constraints
作者:黄文炳,韩家琦,荣钰,徐挺洋,孙富春,黄俊洲
单位:AIR,清华大学计算机系,腾讯AI Lab,德克萨斯大学阿灵顿分校
摘要:多体交互及其动力学建模广泛存在于物理、化学等科学领域的诸多问题中,从分子动力学模拟到机器人动力学控制等。近年来,越来越多的研究人员考虑利用图神经网络对多体交互进行表示与推理。然而,与普通图谱数据不同,多体交互所形成的几何图谱(Geometric Graphs)具有内在物理对称性,并常常需要满足某种几何约束。为了更好处理这些数据,本报告将介绍作者最近提出的一种全新的图神经网络——图力学网络GMN。首先,GMN是等变的,即无论对输入做任何的平移、旋转、翻转等变换,输出都相应地改变。其次,GMN是满足刚体约束的,输出不会改变输入的几何属性(如棍子的长度、铰链的连接等)。最后,理论上,GMN具有良好的模型表达能力。为了更好地验证GMN的能力,我们构造了一个由一定数量的球、棍子和铰链组成的虚拟物理系统,GMN能比其他方法更准确地预测这些系统演变,并满足上述所说的性质。此外,在真实的应用场景包括分子动力学模拟和人体骨架轨迹预测等,验证了GMN的有效性。
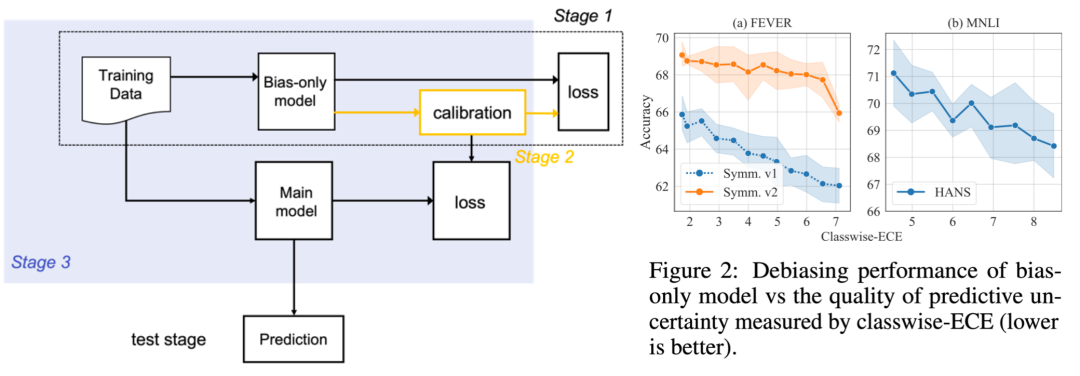
Uncertainty Calibration for Ensemble-Based Debiasing Methods
作者:熊睿彬,陈奕梦,庞亮,程学旗,马志明,兰艳艳
单位:中科院计算技术研究所,百度,中科院数学与系统科学研究院,AIR
摘要:机器学习模型对数据集偏差(dataset bias)的依赖会损害其在分布外数据集上的泛化能力。基于集成的去偏方法(EBD)能够有效减轻分类器对数据集偏差的依赖。它们通过利用偏差模型(bias-only model)的输出来调整分类器的学习目标。在此项工作中,团队关注偏差模型,它在EBD方法中发挥重要的作用,但没有得到足够的关注。实验上,本文发现现有的偏差模型产生的不确定性估计存在一定误差,理论上,本文证明了偏差模型不准确的不确定性估计(uncertainty estimates)会极大的损害去偏性能。基于这些发现,本文提出对偏差模型进行校准,从而实现一个基于集成的三阶段去偏框架 MoCaD。在自然语言推理和事实验证任务上的大量实验表明,MoCaD在已知和未知数据集偏差方面优于相应的EBD方法。此外,团队通过详细的实证分析验证了文章中证明的理论结论。
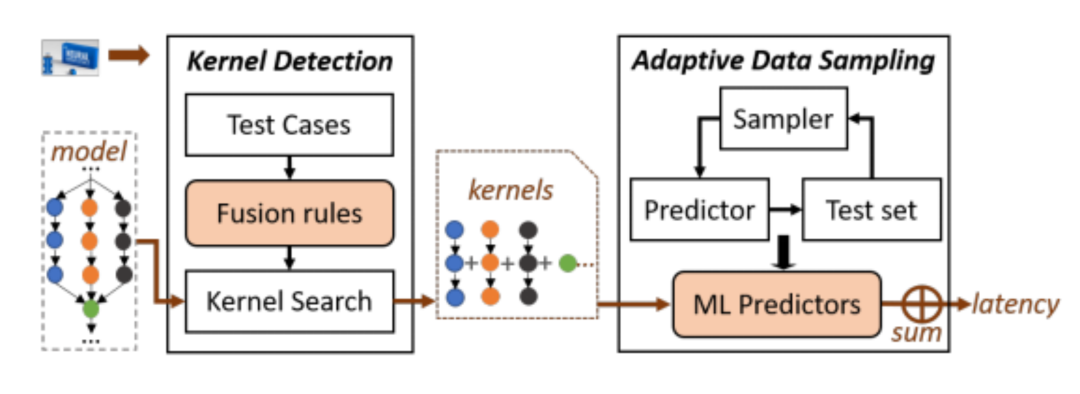
nn-Meter: Towards Accurate Latency Prediction of Deep-Learning Model Inference on Diverse Edge Devices
作者:张丽,韩世豪,魏剑宇,郑宁馨,曹婷,杨玉庆,刘云新
单位:微软亚洲研究院,罗斯-霍曼理工学院,中国科学技术大学,AIR
会议:MobiSys 2021
奖项:最佳论文奖(Best Paper)、本届会议唯一获得Artifact Evaluation 全部三个最高级别徽章
摘要:随着深度学习在移动端的兴起,推理延迟(inference latency)已经成为在各种移动和边缘设备上运行深度神经网络(DNN)模型的一个重要指标。为此,预测DNN模型推理的延迟非常必要,尤其是对于无法在真实设备上测试延迟或者代价太高的任务,例如从巨大的模型设计空间中寻找具有延迟约束的有效的DNN模型。然而,由于不同边缘设备上运行时(runtime)的不同优化导致了模型推理延迟的巨大差异,准确预测推理延迟仍然非常具有挑战性。目前,现有方法无法实现高精度的预测。
在本文中,团队提出并开发了 nn-Meter,可高效、准确地预测 DNN 模型在不同边缘设备上的推理延迟。它的关键思想是将整个模型推理划分为内核(kernel),即设备上的执行单元,然后执行内核级预测。nn-Meter 建立在两个关键技术之上:(i) 内核检测:通过一组设计好的测试用例来自动检测模型推理的执行单元;(ii) 自适应采样:从大空间中有效地采样最有益的配置,以构建准确的内核级延迟预测器。团队在三个常用的边缘硬件平台(移动 CPU、移动 GPU 和Intel VPU)上实现了nn-Meter系统、并使用包含26,000个模型的大型数据集进行评估,结果nn-Meter的表现明显优于先前的最好方法。论文代码开源于https://github.com/microsoft/nn-Meter。
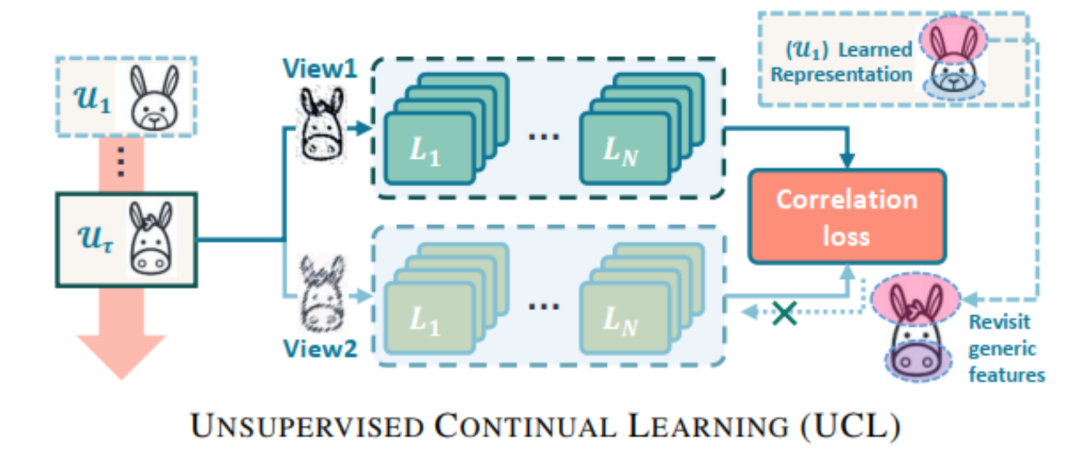
Rethinking the Representational Continuity: Towards Unsupervised Continual Learning
作者:Divyam Madaan,Jaehong Yoon,李元春,刘云新
会议:ICLR 2022 (oral)
摘要:持续学习的目标是学习一连串的任务,并且不会忘记之前获得的知识。然而现有的持续学习方法受限于有监督持续学习场景,不能很好的扩展到数据分布不同且没有标注的真实世界应用中。本文专注于无监督持续学习,学习一连串的无标注任务,同时表明了标注数据对于持续学习不是必需的。
本文融合了持续学习和表征学习方法,解决了无监督持续学习问题。提出了终生无监督混合(LUMP)方法,利用当前任务和之前任务的插值数据来缓解无监督数据表征的灾难性遗忘,通过系统的分析学习到的数据表征,并表明无监督视觉表征对灾难性遗忘更健壮,一致性更好,比有监督持续学习能更适应分布之外的任务。除此之外,本文通过定性分析,发现无监督持续学习得到的数据表征更有意义,损失函数更加平滑。在CIFAR-10和CIFAR-100数据集上的实验表明,比现有无监督持续学习方法的遗忘更少,训练更平滑。而且在少样本学习场景中,LUMP方法达到了最好的性能。论文代码开源于https://github.com/divyam3897/UCL。
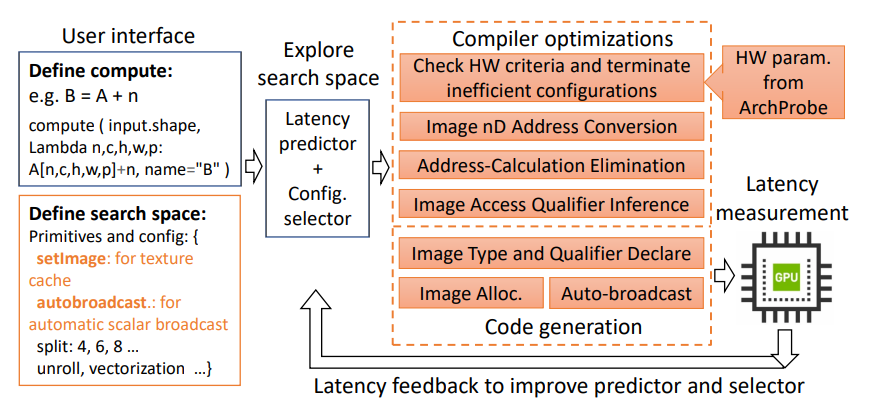
Romou: Rapidly Generate High-Performance Tensor Kernels for Mobile GPUs
作者:作者:梁任冬,曹婷,文吉成,王曼妮,王阳,邹建华,刘云新
单位:微软亚洲研究院,美国加利福尼亚大学尔湾分校,西安交通大学,AIR
会议:MobiCom 2022
摘要:移动GPU作为一种无处不在的强大加速器,对深度神经网络(DNN) 在端侧设备上进行推理加速发挥着重要作用。移动GPU的频繁升级和型号的多样性需要自动内核生成以实现快速DNN的快速部署。然而,目前自动生成内核的性能较差。
本文的目标是快速生成高性能内核以适用于不同型号的移动GPU。主要的挑战是(1)由于缺乏对硬件的了解,不清楚什么是性能最佳的内;(2) 如何从一个巨大搜索空间中快速生成内核。对于第一个挑战,团队提出了一个跨平台的分析工具,首次公开和量化了移动GPU体系结构。团队的结果揭开了硬件瓶颈的神秘面纱,同时也为第二个挑战的解决方案提供了指导,因为我们找到了独特的高性能硬件特征,识别出不适配硬件约束的低效内核,并为内核性能确定了的边界。进而,团队提出了一个为移动GPU特别设计的内核编译器Romou。它支持在内核实现中利用独特的硬件能力,并针对硬件特征去除低效的内核。因此,Romou可以快速地生成高性能GPU内核。与目前性能最好的自动生成内核相比较,它在卷积上实现了平均高达 14.7倍的加速,同时能减少99%的搜索空间。Romou的性能甚至比最好的手工优化的内核有1.2×的加速提升。论文代码开源于:
https://github.com/microsoft/ArchProbe。
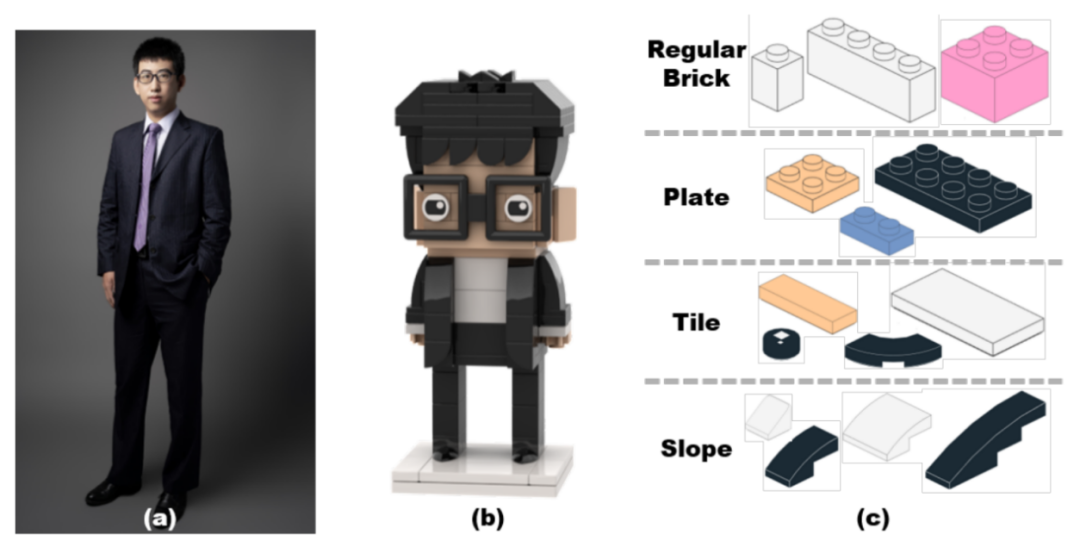
Brick Yourself within 3 Minutes
单位:AIR,麦吉尔大学,千帜科技,北京大学,英特尔研究院
会议:ICRA 2022
摘要:本文介绍了一种智能制造系统,可以自动将拍摄的肖像转换成由乐高积木组成的实体小工具。与合成 2D 图像或虚拟 3D 对象相反,生成物理 3D 装配对象需要考虑物理特性和装配过程,这带来了更多挑战。为了生成任意肖像的积木块模型,团队将属性空间(从二维图像中提取)和积木块模型空间之间的转换公式化为约束整数规划问题,这可以通过启发式搜索方法解决。此外,由于积木在物理上是分散的,团队提出了一种算法来为定制的图形特征积木生成相应的组装指令,以方便用户组装。同时,团队将所提出的算法部署在集成了相机、打印机、笔记本电脑和积木操作单元的自动机器上。最后,生成的积木模型和组装说明由大量用户评估。值得一提的是,整个系统就像一台智能自动售货机,可以在3分钟内生产出一个具有150块积木的模型。
【内附完整论文】AIR近期亮点论文解读