清华大学智能产业研究院(AIR)张亚勤院士、刘菁菁教授及詹仙园助理教授课题组在具身智能领域取得新进展,其两篇相关研究成果 "DecisionNCE:Embodied Multimodal Representations via Implicit Preference"及"Instruction-Guided Visual Masking" 于近期获评ICML 2024 MFM-EAI workshop杰出论文奖。


AIR与商汤研究院,上海交通大学,香港中文大学MMlab与上海人工智能实验室共同提出全新具身智能通用表征预训练方案,可实现在数据稀缺场景下的高泛化、轻量级具身智能体学习。该方法可使用大量易获取的领域外数据学习视觉序列-语言指令相匹配的通用表征,可跨域零样本泛化到下游机器人控制任务上,在实体机械臂多任务操作测试中达到了较领域内前沿方案两倍的成功率。目前该论文已被ICML 2024接收。
•论文标题:
DecisionNCE:Embodied Multimodal Representations via Implicit Preference
•Github开源地址:
https://2toinf.github.io/DecisionNCE/
•论文链接:
https://arxiv.org/pdf/2402.18137.pdf
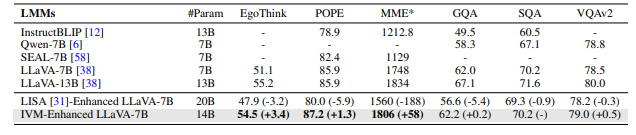
AIR与商汤研究院,香港中文大学MMlab与上海人工智能实验室首次提出了指令引导下的视觉遮罩(Instruction Guided Visual Masking)任务,为解决多模态大模型在视觉定位及视觉-语言推理能力不足的问题提供了全新的解决方案。这篇工作构建了面向语言指令的高质量视觉遮罩数据集,并训练了一个强大的视觉遮罩模型,可有效提升具身智能机器人及多模态大模型在视觉推理方面的能力。在高难度的多模态问答测试任务V*bench中,该模型可将OpenAI最先进的闭源多模态大模型GPT4V的正确率提高35%,首次突破80%。
•论文标题:Instruction Guided Visual Masking
•Github项目开源地址:
https://2toinf.github.io/IVM/
•论文地址:
https://arxiv.org/abs/2405.19783
ICML全称是 International Conference on Machine Learning,即国际机器学习大会,是由国际机器学习学会(IMLS)主办的年度机器学习国际顶级会议。ICML MFM-EAI workshop聚焦于多模态基础模型(MFM)、具身智能(EAI)以及两项研究的交叉领域,受到了广泛关注与认可。
具身智能是通用人工智能(AGI)研究的最终目标之一,是将人工智能真正应用于解决现实物理世界复杂多样任务的重要途径。而对于人类而言,通过语言来向机器人传递任务需求是一个最自然和直接的方式。因此以Google RT1、RT2系列为代表的视觉-语言-控制模型(VLCM,Vision-Language-Control Model)受到广泛关注。VLCM智能体可以通过视觉理解环境,并执行人类语言指令所描述的任务,展现出了极强的zero-shot泛化能力。然而,VLCM模型通常采用端到端架构,规模庞大,需要海量的示教数据进行训练。
为了解决数据稀缺的问题,一个通用的解决方案是:表征预训练(Representation Pretrain)。其中经典的方法便是以CLIP为代表的对比学习方法。然而,对于机器人的决策而言,训练这样的表征是非常困难的,因为高度抽象的语言指令所描述的是序列化的任务执行过程。
在本文中,课题组发现人类反馈强化学习(RLHF)中用于奖励函数训练的Bradley-Terry (BT)模型,可天然地被转化为一种高效的适用于机器人多模态通用表征预训练方法。
Bradley-Terry Model
Bradley-Terry (BT) 模型通常用于RLHF中的奖励函数的学习。其优化目标可表示为下图中的形式:
其中,用
表示一段视频片段
中的第
帧图片。通过提高正样本视频片段
上每一个单帧转移的奖励总和,降低负样本视频片段
上的奖励总和,利用BT模型就可以拟合人类偏好,完成奖励函数的学习。因此,BT model天然的可被应用于轨迹级的对比学习。但是,想直接把BT模型拓展到表征学习的任务中,仍有几个问题需要解决:1. 偏好标签从哪来?2. 视频片段长度如何选择?3. 如何建模奖励函数?
隐式偏好标注
针对没有偏好标注的问题,课题组提出了一个隐式人类偏好的概念,即对于一个语言指令而言,与其相匹配的视频片段是优于不匹配视频片段的。实际上,现有的各类视觉-语言数据集中已有大量的语言-视频匹配片段。因此可以利用这些隐式的偏好标注进行训练,并泛化迁移至样本较少的机器人任务。
随机片段采样
课题组设计了随机片段采样方法来解决通用视觉表征局部-全局信息抽取权衡困难的问题。简单地来说,可先从一段完整视频中随机选择一帧作为视频片段的开始,然后在后续视频中选择一帧作为视频片段的结束。这个方法兼顾了提取全局和局部的时序信息。
奖励重参数化
在这篇文章中,课题组提供了两种奖励重参数化方法
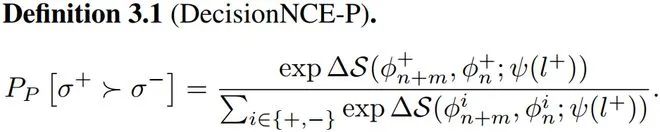
式中,S可以是任何相似度的衡量指标,在此定义为余弦相似度。该奖励函数衡量的是表征空间中视频帧转移向语言前进的距离。这个定义隐含一个优势:中间视频帧的表征会两两相消,进而极大地降低了计算量,简化了训练难度。
然而,由于考虑到一个语言指令代表的不是某一帧静态图片,而是一种从状态A到状态B的动态变化过程。因此课题组进一步提出了第二个奖励重参数化方法:
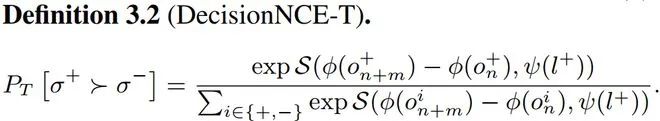
其中,S为余弦相似度。注意此处的余弦相似度计算的是视觉表征之差和语言表征之间的相似度。此时一个语言指令代表的不再对应某一帧静态图片,而是表示表征空间的一个转移方向。
课题组利用提出的特征学习方法训练表征模型,并对其进行了大量实验验证。
全局/时序信息提取
课题组首先测评DecisionNCE-P/T捕捉全局/局部时序信息的能力。理想情况下,DecisionNCE-P/T需要为匹配的视频-语言对分配更高的奖励值,为不匹配的视频-语言对分配较低的奖励值。下图可以清晰地看出来,DecisionNCE-P/T的斜对角线(匹配的视频-语言对)呈现出明显的亮线,说明其不论针对短的视频片段还是长的视频片段都可以识别出正确的时序信息。相比之下,其他baseline算法例如R3M, LIV和CLIP则不具备这样的能力,特别是针对短视频片段受到噪声的干扰严重。
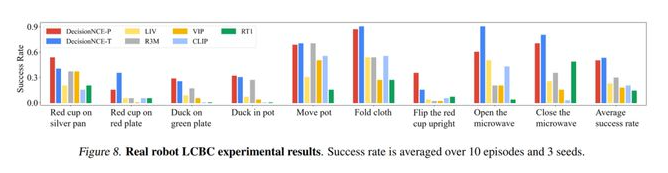
实物机械臂实验

通过将大量领域外数据训练得到的通用表征,接入一个超轻量级的下游决策模型(两层MLP),并基于极少量的机械臂视角数据进行语言条件的行为克隆(Language-conditioned behavior cloning,LCBC)学习,课题组成功构建了具有语言指令理解能力的多任务机械臂决策模型。课题组在实物实验中测试了抓放(pick & place),挪动 (move),开 (open),关 (close),叠 (flod),摆正 (flip)五个机械臂操作的基础技能,涵盖9个子任务。结果表明,所提出的新方法在任务执行成功率方面大幅由于现有主流方法。结果如下表所示。
通用奖励函数
由于BT 模型本身就是一种奖励函数建模方法,因此DecisionNCE-P/T不仅可以用作表征学习,还可以提供通用的奖励函数。课题组可视化了DecisionNCE-P/T对不同的视频-语言对预测的奖励函数,如下图所示。
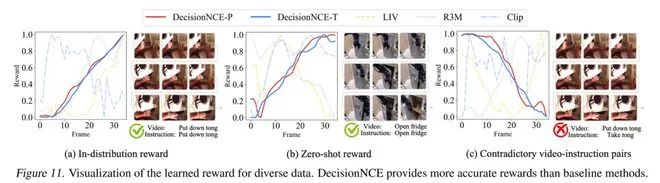
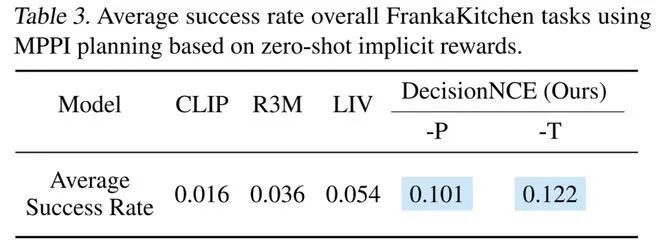
结果表明DecisionNCE-P/T不仅可以对分布内的数据(in-distribution)预测正确的奖励变化趋势,还具有很好的分布外泛化能力(zero-shot reward)。同时值得一提的是,因为DecisionNCE自身对比学习的特性,它可以很为完全相反的视频-语言对分配相反的奖励变化趋势。因此,DecisionNCE所附带提供的通用奖励函数也可以直接与决策领域的规划算法(例如MPPI)相结合,实现zero-shot language-reward planning。课题组在FrankaKitchen仿真环境对此进行了测试,DecisionNCE-P/T学习得到的通用奖励函数在规划任务上同样大幅领先同类方法。
Instruction Guided Visual Masking
具身智能体在复杂场景的泛化能力始终是一个广受关注的研究方向,产业界及学界都希望训练出的智能体不仅仅能够在少数场景中表现良好,也能够在更多未知的复杂场景中具有泛化能力和鲁棒性。然而遗憾的是,这个目标对于目前AI具身智能决策控制模型还是十分困难。课题组发现增加场景的复杂度即视觉干扰(Visual distraction),会导致在简单场景表现良好的决策控制模型性能严重下降。

事实上,这不仅仅是具身智能领域面临的问题,即便是现在最先进的多模态大模型GPT4-V也有类似的困扰。当给定一张语义丰富的图片并询问GPT4-V关于图片局部的一些特定的问题时,课题组发现GPT4-V往往不能正确回答。而相对应的,如果将与问题无关的图片部分遮盖掉,那么GPT4-V的回答又会变得正确。很显然,即便是在数以亿计的数据上训练,GPT4-V的视觉定位能力(Visual Grounding)还还是不足,不能做到根据指令在复杂的视觉场景中找到与指令相关的图片内容。课题组将这个问题归咎于模型的训练范式,不论是刚刚提到的控制模型亦或是多模态大模型,他们多采用端到端(End-to-End)的训练方法,这对于视觉定位的能力学习来说是非常低效的,模型需要对齐(align)抽象的答案和相关的图片区域从而隐式(implicitly)地获得视觉定位能力,这个问题亟待解决。
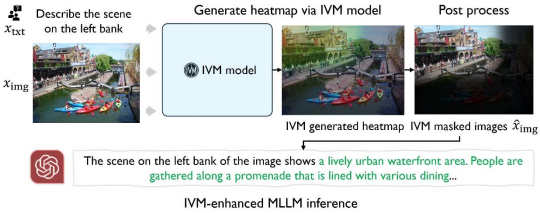
在这篇文章中,课题组考虑将视觉定位和执行下游任务解耦开,利用直接的像素级视觉定位标签来监督训练一个视觉定位模型,这样的话这个模型将能够非常高效地显式地(explicitly)学习到面向指令的视觉定位能力,然后可以利用这个模型来辅助各种下游模型,即当给定一个复杂视觉场景和一个特定指令时,先利用这个模型定位到所有和指令相关的部分并将其他所有的无关部分通过简单的后处理遮盖掉。再将处理后的图片输入给下游模型以提升他在下游任务上的性能表现,在这里我们称这个方法为面向指令的视觉遮罩(Instruction Guided Visual Masking),简称为IVM。
Instruction Guided Visual Masking

如上图所示,IVM与已经存在的视觉定位(VG)任务一定的相似度但是更加具有挑战性,已经存在的最先进的视觉定位模型在复杂的视觉理解任务下均失败了,这是因为过去的VG任务主要面向定位一些由特定语言描述的或是提前定义好的物品,而IVM需要面向复杂的语言指令进行推理并定位所有与指令相关的内容部分。
数据生成
从上述分析可以看出训练一个这样的VG模型是具有挑战性的,其中最大的问题是缺少具有多样性且符合要求的丰富数据。为了解决数据缺失的问题,课题组针对已有的两类可用开源数据分别设计了一套由大语言模型驱动的多专家合作数据生成方案(LLM-empowered Mixture of Expert Annotation Pipeline):1. 针对视觉定位标签但缺少丰富指令的数据,通过调用大语言模型来根据标签的内容生成对应的复杂指令 2. 针对具有指令单缺少定位标签的数据,由于现有的任一单一模型都不足以生成足够好的标签,因此课题组首先调用大语言模型对指令进行推理简化,再将简化后的指令和图片输入到多个视觉定位专家模型中,整合所有专家的输出来得到高质量标注。
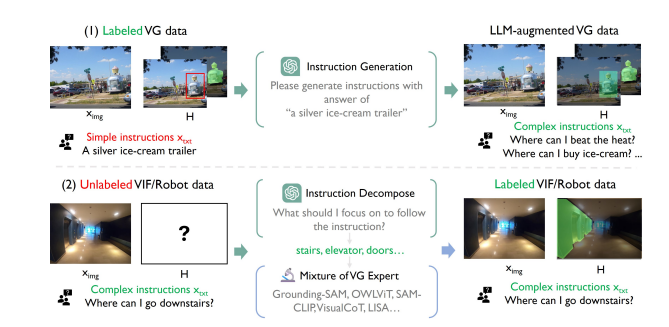
由于以上数据是由已有的深度学习模型生成的,缺乏可解释性且不可避免的存在一些质量较低的数据。因此为了进一步提升模型性能上限,课题组手动标注了10K个高质量样本数据。最终将自动生成和手动标注的数据整合,构建了IVM-Mix-1M数据集。
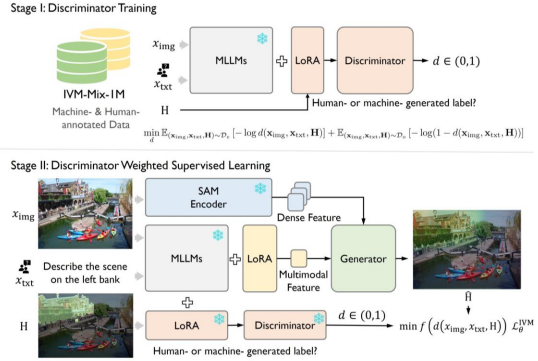
模型框架与训练
以下介绍IVM的模型架构设计。相关的设计受到了最近“推理分割”任务的启发,课题组引入了SAM和一个多模态大模型LMM来分别提取稠密视觉信息和多模态信息。最后将两者输入到一个生成器中来实现遮罩预测。
直接在这样的混合质量(mix-quility)的数据上进行监督训练是低效的,因此课题组针对数据特性提出了判别器引导的监督训练(Discriminatory-Weighted Supervised Learning)。具体来说,本文引入了一个基于多模态大模型的判别器,并训练它来识别手动和自动生成数据,如下图stage1所示。在得到了这个判别器后,将判别器判别每一个样本是手动标注样本(高质量样本)的概率作为每个数据在监督学习中的权重,如下图stage2所示。
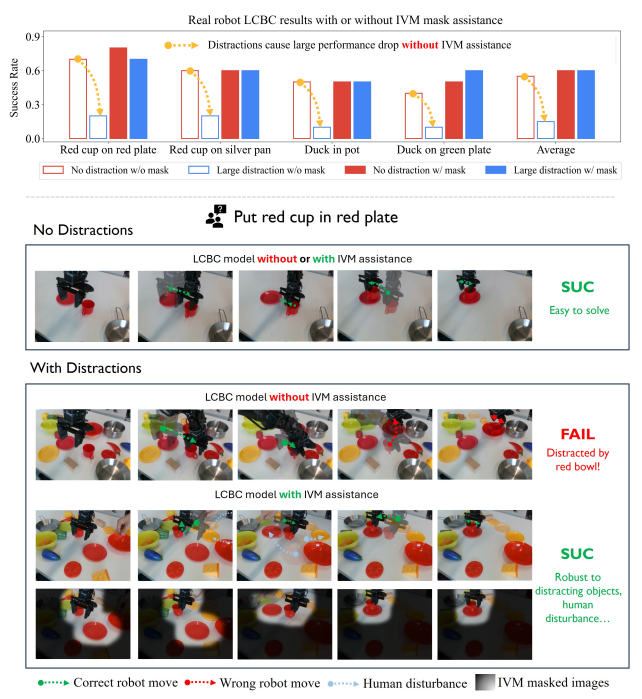
课题组在具身智能的决策任务和多模态问答任务上做了大量的实验来证明IVM模型的有效性。实验结果证明了本文提出并训练的IVM模型在下游任务上的通用性和强大能力,在IVM的辅助下,原本在复杂视觉场景性能较差的各种下游模型在不经过任何微调的情况获得了巨大的性能提升。
在决策任务上,本文的实验方法为,在控制过程中将IVM简化前后的图像分别输入到由相同数据训练得到的控制模型中进行测试,比较两者的性能差异。结果如下图所示,视觉输入经过IVM简化后,控制模型展现出了良好的抗视觉干扰能力,任务成功率远高于输入原图像的控制模型。
在多模态问答任务上,本文的验证实验分成两部分:首先,尝试将IVM模型与现有最先进的闭源多模态大模型GPT4V相结合,在最新的多模态问答测试集V*bench上进行测试。IVM将GPT4V在该测试集上的正确率提高了35%,首次突破80%,展现了强大的视觉定位能力。
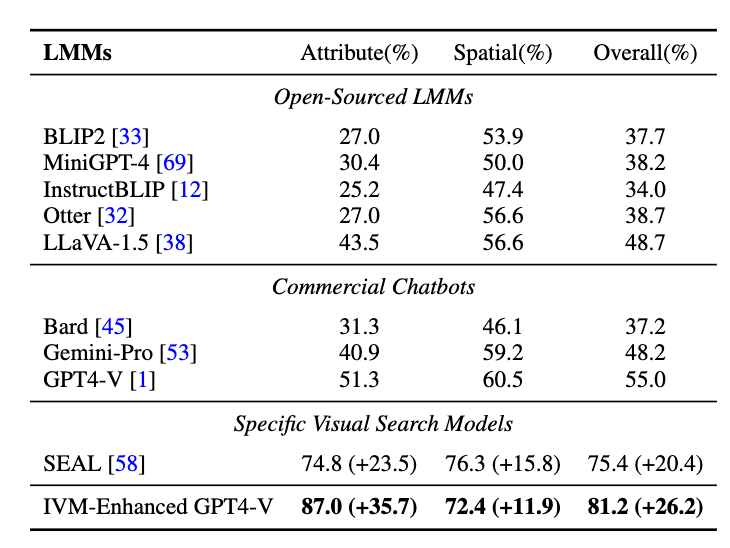
其次,将IVM模型与现有最流行的开源大模型LLaVA相结合,并在六个经典的多模态问答测试集上进行测试,结果表明IVM能够稳定地提升正确率,展现了IVM的通用性。
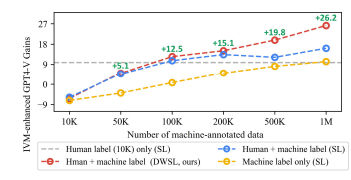
消融实验
课题组主要针对所提出的框架中最重要的数据和训练算法进行了消融实验如下图所示。
可以看到随着数据量增加,模型在下游性能稳步提升,并且我们提出的DWSL
训练算法与朴素的监督学习相比也能够进一步地大幅提升模型性能。
更多关于细节的实验结果欢迎进一步阅读论文以及附录内容。

李健雄,清华大学智能产业研究院(AIR)三年级博士生。研究方向为离线强化学习与具身智能。

郑金亮,清华大学智能产业研究院(AIR)一年级博士生。研究方向为计算机视觉,多模态及具身智能模型。

郑一楠,清华大学智能产业研究院(AIR)一年级博士生。研究方向为安全离线强化学习,自动驾驶以及具身智能。

詹仙园,清华大学智能产业研究院(AIR)助理研究员。研究方向为数据驱动决策优化理论与算法、复杂工业、能源系统控制优化,具身决策模型,及智能交通系统。个人主页:http://zhanxianyuan.xyz/。