清华大学智能产业研究院(AIR)与清华大学计算机科学与技术系、清华大学脑与智能实验室、上海人工智能实验室和北京零一万物科技有限公司合作,提出了一种新型大模型微调方法C-RLFT(Conditional Reinforcement Learning Fine-Tuning),充分利用混合质量数据显著提升开源模型性能(如将Mistral 7B在HumanEval上的性能从30.5提升至71.3),相关论文被人工智能顶级国际会议ICLR 2024录用。相应模型OpenChat在参数规模仅为7B的情况下在多个业界广泛使用的评测数据集上取得与ChatGPT相近的性能,并且可在消费级GPU(如RTX 3090)上运行。OpenChat在国内外开源社区产生影响,获得超过4500个GitHub星标,连续三周在HuggingFace全球趋势榜位居Top-5。OpenChat的有效性被华为公司盘古智能体、美国加州大学伯克利分校Starling-LM等最新研究工作实验验证并扩展,受到Anakin.ai、Mindverse、Weel等美国、德国、日本等大模型开源社区媒体报道。
· 论文标题:OpenChat: Advancing Open-source Language Models with Mixed-Quality Data
· 论文链接:
https://arxiv.org/abs/2309.11235
· 代码链接:
https://github.com/imoneoi/openchat
· 模型链接:
https://huggingface.co/openchat
近年来,以OpenAI推出的GPT-4为代表的大规模语言模型蓬勃发展,将人工智能的发展推向一个新的历史阶段。尽管GPT-4在多项任务上展现了惊人的性能水平,但是作为一个闭源模型,其技术细节并不向外界公开。与此同时,以Meta推出的LLaMA为代表的开源模型自2023年以来发展迅速,极大地推动了大规模语言模型领域的持续发展。开源模型的性能通常显著低于闭源模型,一个关键的制约因素是数据质量。目前主流的微调方法,无论是有监督微调SFT(Supervised Fine-Tuning)还是强化学习微调RLFT(Reinforcement Learning Fine-Tuning),都高度依赖时间和人工成本高昂的高质量人工标注数据。尽管大模型开源社区收集的开源数据规模在不断持续增长,但是质量参差不齐,严重制约了开源模型的性能提升。因此,如何充分利用大规模混合质量数据提升开源模型性能成为一个亟待解决的技术难题。
图1:有监督微调(SFT)、强化学习的微调(RLFT)与我们提出的条件式强化学习微调(C-RLFT)之间的对比。
针对上述问题,清华大学智能产业研究院(AIR)与清华大学计算机科学与技术系、清华大学脑与智能实验室、上海人工智能实验室和北京零一万物科技有限公司合作,提出了一种新型大模型微调方法C-RLFT(Conditional Reinforcement Learning Fine-Tuning),充分利用混合质量数据显著提升开源模型性能,相关论文被人工智能顶级国际会议ICLR 2024录用。AIR执行院长刘洋教授是论文共同通讯作者,詹仙园助理研究员对论文核心算法做出了重要贡献,刘洋教授的博士生程思婕是论文共同第一作者。论文作者还包括清华大学脑与智能实验室的宋森研究员(共同通讯作者)、王冠(共同第一作者)和李先刚博士(第四作者)。
C-RLFT充分利用更容易获取的混合质量的监督微调数据帮助提升开源语言模型的指令跟随能力,无需任何成对或者排序的偏好数据。给定一个基座语言模型
,有限的高质量对话数据
和大量的次优对话数据
,目标是仅使用
得到基于预训练语言模型
微调的模型
。以最流行的监督微调数据之一ShareGPT为例,来自GPT-4和GPT-3.5的不同来源数据可以分别被看作
和
,因为GPT-3.5的对话数据质量总体而言会比GPT-4略差一些。显然,仅仅基于
和
是无法得到精确和细粒度的奖励信号的。然而,值得注意的是,
和
之间的质量差异本身可以作为隐含的或弱的奖励信号。为了利用这种粗粒度的奖励信息,我们提供了一个新的见解,通过用一个更好、信息更丰富的基于类别的参考策略
来约束
而不是原始的预训练语言模型
。我们可能会弥补奖励中的潜在缺陷,并实现良好的微调性能。
给定具有不同质量的监督微调对话数据集
,我们可以用不同的数据来源作为类别标签(例如,
,
)来进行补充,从而构建一个基于类别的数据集
。我们使用
来表示基于类别的数据集
中关于指令
和响应
的基于类别的分布,这可以被近似地看作是离线强化学习领域中数据集的行为策略,不同的是
是一个基于类别的策略。根据类别标签的数据总体而言具有不同的质量,可以在
中编码粗粒度奖励
,如下所示:
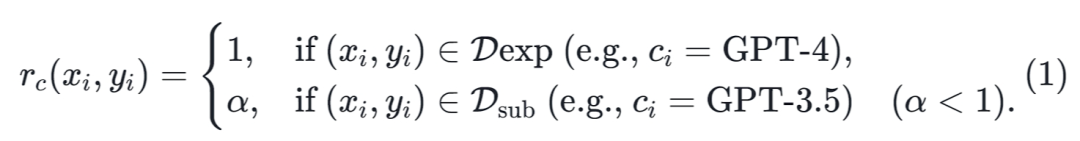
其中,我们将GPT-4的对话数据视为专家数据
,将GPT-3.5对话数据视为次优数据
。同时,我们设置
来引导微调模型更倾向于高质量的回答。
由于公式(1)中的奖励
的粒度非常粗,为了在基于强化学习的微调中可靠地使用它们,我们需要提供额外的信息源来弥补它们的不足。在这里,我们介绍C-RLFT,它受到离线强化学习中基于目标的监督学习的启示,即通过在监督的目标/结果条件策略中添加适当的信息,可以恢复优化的性能。C-RLFT包含两个关键因素:1)将大规模语言模型微调为基于类别的策略
,2)在KL-regularized RL框架中,将
向类别信息增强的参考策略
进行约束,而不是向原始的基座模型策略
。由于我们将要微调的语言模型建模为基于类别的策略
,可以通过将来自不同数据源的每个示例基于不同的初始提示令牌来实现,如下所示。

为了补偿粗粒度的奖励信息
,我们修改了原始的KL-regularized 强化学习目标公式,从而得到以下优化问题:
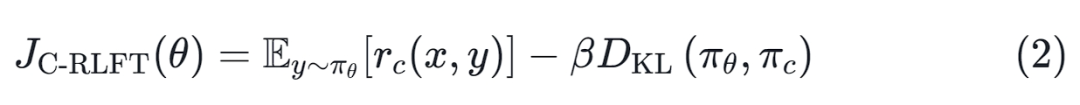
该想法是使用
中的更高质量且信息丰富的基于类别的行为策略
进行约束,而不是预训练模型
。采用这种设计有以下原因。首先,对于大多数现有的开源预训练模型,它们在许多情况下的性能仍然不如基于API的模型,这意味着即使是从GPT-3.5收集的
数据也可能比
的质量高。其次,
包含数据来源信息,可以提供额外的信息来帮助区分数据的质量。根据先前的工作,可以证明上述KL正则化奖励最大化目标的最优解具有以下形式:
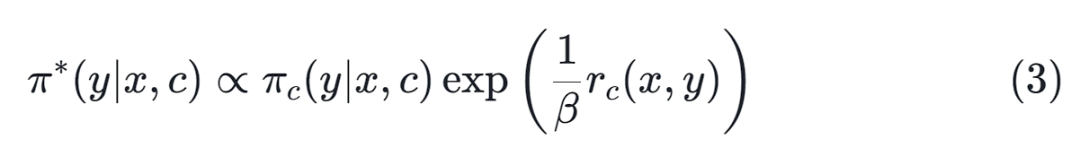
因此,我们可以通过最小化基于类别的数据集
下的
和
之间的KL散度来提取优化的策略
:
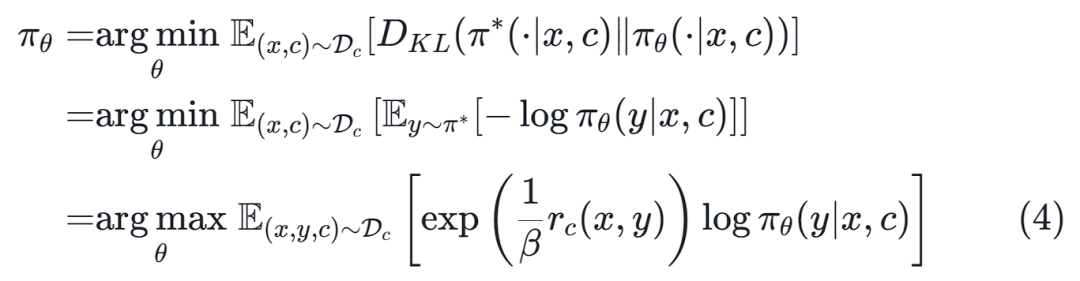
上述推导表明,可以通过一个简单的奖励加权回归目标和基于类别的数据集
来学习微调的策略
。这个学习目标为微调开源大规模语言模型提供了一个非常简单的方案。它不需要精确的奖励标签,而是使用基于条件的方式来区分专家和一般的模型行为。
OpenChat项目由清华大学王冠与程思婕发起,2023年7月1日发布第一版模型,2023年9月21日在arXiv上发布论文预印版,2023年11月1日发布OpenChat-3.5-7B版,2023年12月10日发布OpenChat-3.5-1210版,2024年1月6日发布OpenChat-3.5-0106版,2024年1月16日论文被ICLR 2024录用。最新的OpenChat-3.5-0106版以Mistral-7B为优化对象,主要使用ShareGPT开源项目收集的对话数据,以及推理、代码、数学等开源项目数据集,取得了显著的性能提升,如表1所示。
表1:OpenChat-7B以Mistral-7B为起点,基于混合质量数据,在多个数据集上获得了大幅度的性能提升。
2023年12月22日,华为诺亚方舟实验室、英国帝国理工大学和英国牛津大学在arXiv上发布论文“Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning”,对GPT-3.5、Llama 2-70B、Vicuna-13B、Mistral-7B、OpenChat-3.2和OpenChat-3.5等模型在ALFWorld、GSM8K、HotpotQA、WebShop、HumanEval和BabyAI等任务上进行性能测试。实验结果表明,OpenChat-3.5在接受测试的开源模型中表现最好,整体性能仅次于闭源模型GPT-3.5,在个别任务上能够超过GPT-3.5。
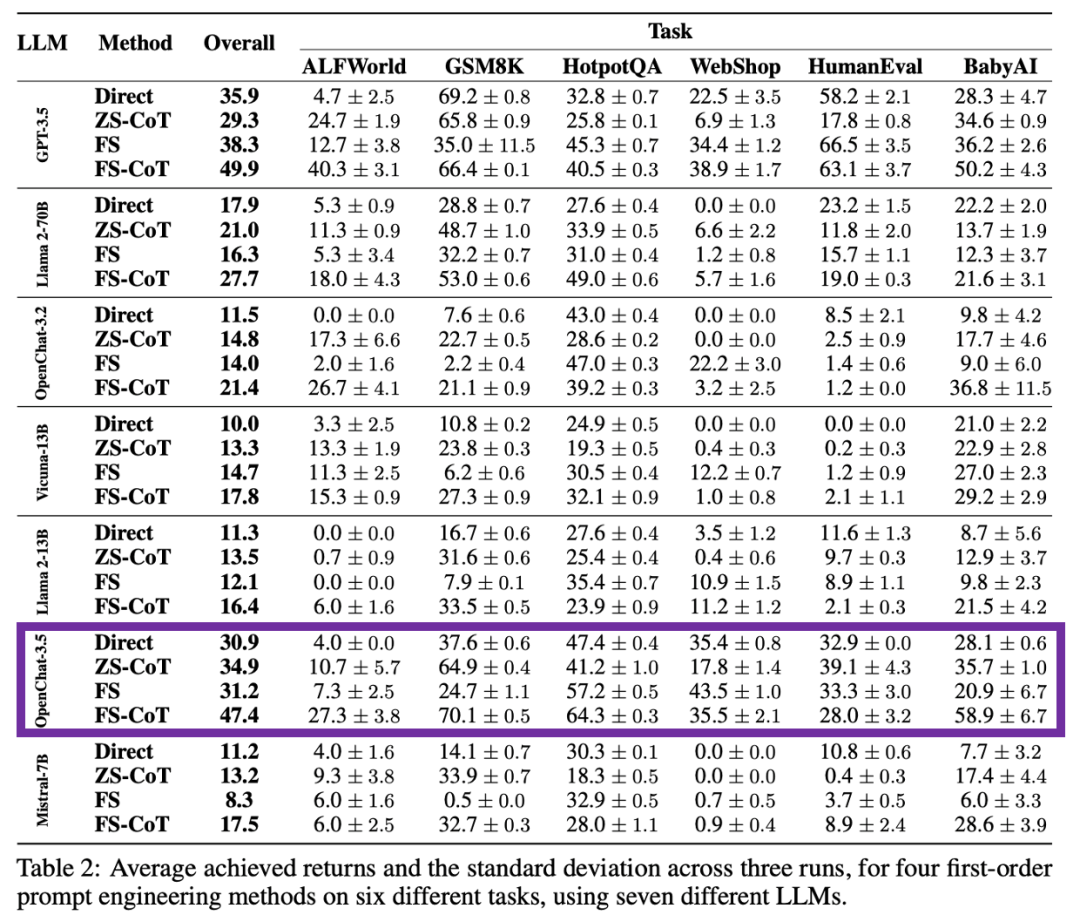
图2:Pangu-Agent对GPT-3.5、Llama 2-70B、Vicuna-13B、Mistral-7B、OpenChat-3.2和OpenChat-3.5等模型的测试结果。图片来源:https://arxiv.org/pdf/2312.14878.pdf。
OpenChat项目自2023年7月1日启动以来,在国际大模型开源社区产生了影响,获得超过4500个GitHub星标,连续三周在HuggingFace全球趋势榜位居Top-5。OpenChat受到Anakin.ai、Mindverse、Weel等美国、德国、日本的大模型开源社区媒体报道。2023年11月,美国加州大学伯克利分校推出了Starling-7B,将OpenChat-3.5作为策略微调(policy fine-tuning)的初始模型,通过新提出的RLAIF方法进一步提升了开源模型的性能。
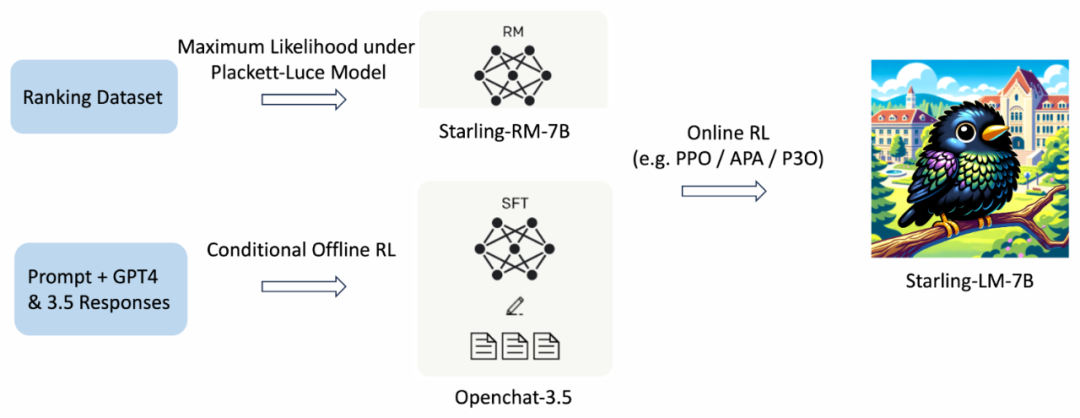
图3:美国加州大学伯克利分校推出的Starling-7B将OpenChat-3.5作为策略微调的初始模型。图片来源:https://starling.cs.berkeley.edu/。
OpenChat项目团队将继续致力于开发高性能、易于部署、可在消费级GPU上运行的开源语言模型,进一步提升模型在复杂推理、持续学习、多语言和多模态等方面的能力。OpenChat作为一个国际化开源项目,已经吸引了来自清华大学、上海人工智能实验室、零一万物、RunPod、GPT Desk、Alignment Lab AI、Nous Research、Pygmalion AI的教师、研究人员、工程师、从业者和学生的参与和支持。我们热忱地欢迎更多的志同道合之士加入进来,共同建设普惠开源语言模型!
程思婕,清华大学计算机科学与技术系2023级博士生。研究方向为人工智能基础模型、世界模型、具身智能。个人主页:https://adacheng.github.io/。
詹仙园,清华大学智能产业研究院(AIR)助理研究员。研究方向为基于离线深度强化学习的数据驱动复杂系统控制优化、智能交通系统以及复杂网络。个人主页:http://zhanxianyuan.xyz/。
刘洋,清华大学万国数据教授、智能产业研究院(AIR)执行院长、计算机系副系主任,国家杰出青年基金获得者。研究方向为自然语言处理。个人主页:https://nlp.csai.tsinghua.edu.cn/~ly。