过去半年来,AIR围绕智慧交通、智慧医疗、智慧物联三大研究方向开展系统深入的研究,并在ACL、NeurlPS、ICLR和MobiSys等重要国际期刊和会议上发表多篇高水平论文并获得ACL 2023杰出论文奖、CICAI 2023 Best Paper Runner-up等奖项。在最近的NerulPS 2023会议上,AIR共计11篇论文被录用。
今天,小编就为大家精选了一些AIR近期的亮点论文,并梳理了摘要解读,文末可获取完整论文打包下载方式。
LinkerNet: Fragment Poses and Linker Co-Design with 3D Equivariant Diffusion
作者
:关嘉麒,彭鑫港,姜沛麒,罗宇男,彭健,马剑竹
单位
:清华大学智能产业研究院(AIR),伊利诺伊大学香槟分校,佐治亚理工大学
会议
:NeurIPS 2023 (Spotlight)
摘要:靶向蛋白质降解技术(TPD),例如蛋白水解靶向嵌合体(PROTAC),已成为选择性去除致病蛋白质的强大工具。该领域的一个具有挑战性的问题是设计一种连接体(Linker)来连接不同的分子片段以形成稳定的候选药物分子。现有的Linker设计模型均假设两侧的分子片段的相对位置已知,但在PROTAC的实际设计中,该假设并不成立。在这项工作中,我们解决了一个更普遍的问题,即假设分子片段在 3D 空间中的姿态未知,去设计能有效连接分子片段的Linker。为此,我们开发了一个 3D 等变扩散模型 LinkerNet来共同学习分子片段姿态和Linker 的图结构及3D结构的生成过程。其中,通过将分子片段视为刚体,我们受刚体力学中牛顿-欧拉方程的启发,创新性地设计了分子片段姿态预测模块。在 ZINC 和 PROTAC-DB 数据集的实验研究表明,我们的模型可以在无约束和有约束生成设置下均可以生成类药性和可合成更强,且能量更低的分子,为PROTAC中的Linker设计提供了一种有效的解决方案。
DrugCLIP: Contrastive Protein-Molecule Representation Learning for Virtual Screening
作者:高博文,强博,谭海川,任敏思,贾寅君,卢敏思,刘菁菁,马维英,兰艳艳
单位:清华大学智能产业研究院(AIR),北京大学药学院
会议:NeurIPS 2023
摘要
:在近年来的AI领域中,虚拟药物筛选成为了前沿的研究焦点。针对这一挑战,课题组提出了一种全新的范式:DrugCLIP 。与传统方法相比,DrugCLIP提供了一个全新的角度来看待这一任务。首先,DrugCLIP将原本复杂的虚拟筛选任务重构为一个基于稠密向量的检索任务。通过将药物和蛋白质口袋的化学信息转化为高维向量,利用向量间的余弦相似度来表示他们之间的结合亲和力。此外,DrugCLIP还采用了对比学习的策略,使得我们可以从大量的成对数据中进行学习,而无需依赖于昂贵且难以获取的结合亲和力实验数据。同时课题组还为DrugCLIP引入了一个基于生物学知识启发的数据增强策略,进一步增强蛋白质与分子之间的表示能力。
通过大量实验验证,DrugCLIP在多个重要的虚拟筛选测试,如DUD-E, LIT-PCBA等,均展现出了卓越的性能。
它显著地优于传统的对接和监督学习方法,在召回率上有了很大的提升。
同时DrugCLIP还极大地降低了筛选所需的计算时间,能够在仅用几秒的时间内完成对千万级别的候选分子库的筛选。
3D Implicit Transporter for Temporally Consistent Keypoint Discovery
作者
:钟程亮,郑宇航,郑宇鹏,赵昊,弋力,慕晓冬,汪羚,李鹏飞,周谷越,杨超,张鑫亮,赵健
单位
:清华大学智能产业研究院(AIR),北京航空航天大学,中国科学院自动化研究所,清华大学交叉信息研究院,上海人工智能实验室
摘要:三维骨架关键点检测和跟踪在动物行为学表征研究中具有重要作用。然而,现有的二维和三维关键点检测方法主要依靠几何一致性来实现空间对齐,忽略了时间一致性。为了解决这个问题,前人针对 二维数据引入了 Transporter 方法,该方法从源帧重建目标帧以结合空间和时间信息。然而,由于三维点云与二维图像的结构差异,将 Transporter 直接应用于三维点云是不可行的。因此,课题组提出了 Transporter 的第一个三维版本,它利用混合三维表征、交叉注意力和隐式重建。我们将这种新的学习系统应用于三维铰接物体和非刚性动物(人类和啮齿动物),并证明习得的关键点是时空一致的。相关代码已开源: https://github.com/zhongcl-thu/3D-Implicit-Transporter
End-to-End Full-Atom Antibody Design
单位
:清华大学智能产业研究院(AIR),清华大学计算机系,中国人民大学高瓴人工智能学院,Beijing Key Laboratory of Big Data Management and Analysis Methods
摘要:课题组提出了dynamic Multi-channel Equivariant graph Network (dyMEAN),只需提供抗体framework region的序列,即可进行CDR序列和整个抗体结构的协同设计,同时可以在氨基酸粒度上进行全原子的建模,因此能够有效地利用侧链信息。课题组研究成员首先从数据集中提取保守结构模板作为初始化,然后通过“shadow paratope”的概念连接抗原和抗体的信息通路,经过dyMEAN多轮迭代后,将native paratope与shadow paratope对齐,得到最后的抗原-抗体复合物结构。在CDR设计、优化以及抗原-抗体Docking的任务上优于各类通过组合不同方法得到的pipeline。
Equivariant Flow Matching with Hybrid Probability Transport for 3D Molecule Generation
作者
:宋宇轩*,龚经经*,徐民凯,曹子尧,兰艳艳,Stefano Ermon,周浩,马维英
单位
:清华大学智能产业研究院(AIR),斯坦福大学
摘要:生成3D分子需要同时决定分类特征(原子类型)和连续特征(原子坐标)。现有的基于扩散模型的方法通常有概率转换不稳定,模态难以对齐以及采样速度低效等局限。课题组提出了等变流匹配(Equivariant Flow Matching),结合了等变建模和更稳定的概率分布转换的优点。具体而言,我们提出了一种混合概率路径,其中坐标概率路径通过等变最优传输(Equivariant Optimal Transport)进行正则化,并对不同模态之间的信息进行对齐。实验证明,所提出的方法可以在多个分子生成基准测试中始终获得更好的性能:对于大型类药分子的有效百分比提高了6%,平均采样速度提高了4.75倍。
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving
作者:武子睿,刘天瑜,罗立一,钟至德,陈建腾,萧鸿民,侯超,娄浩哲,陈远韬,杨润一,黄昱欣,冶晓宇,颜子轲,石永亮,廖依伊,赵昊
单位:清华大学智能产业研究院(AIR),香港科技大学(广州),香港科技大学,麦吉尔大学,北京理工大学,新加坡国立大学,香港大学,威斯康星-麦迪逊大学,西安建筑科技大学,帝国理工学院,浙江大学
会议:CICAI 2023 (Oral)
奖项:Best Paper Runner-up
摘要
:如今,自动驾驶汽车已经可以在大城市示范区内平稳行驶,然而学术界普遍认为,真实的传感器仿真将在通过模拟解决剩余的极端情况方面发挥关键作用。为此,课题组提出了一种基于神经辐射场(NeRF)的自动驾驶模拟器。与现有工作相比,MARS具有三个显着特点:
(1) 实例感知。本仿真器使用独立的网络分别对前景实例和背景环境进行建模,以便单独控制实例的静态(例如大小和外观)和动态(例如轨迹)属性。
(2) 模块化。本仿真器允许在不同的NeRF主干、采样策略、输入模态等配置之间灵活切换。我们期望这种模块化设计能够促进基于 NeRF 的自动驾驶模拟的学术进步和工业部署。(3) 真实感。使用最佳模块组合,本仿真器可以达到照片级真实感的渲染效果。本仿真器也是世界上首个开源的模块化NeRF自动驾驶仿真器,代码地址:https://github.com/OPEN-AIR-SUN/mars
Look Beneath the Surface: Exploiting Fundamental Symmetry for Sample-Efficient Offline RL
作者
:成鹏,詹仙园,武志昊,张文嘉,宋守诚,王涵,林友芳,姜力
单位
:清华大学智能产业研究院(AIR),北京交通大学,上海人工智能实验室
摘要:离线强化学习(RL)通过从预先收集的数据集中学习策略,为RL部署到实际应用场景提供了一种可行的技术路径。然而,现有的离线RL算法的性能普遍在小数据集或状态-动作空间覆盖不足的数据集中表现不佳,导致相关方法在实际落地方面遇到很大的障碍。为了解决这个问题,课题组提出了一套基于动力学系统基础对称性的全新框架TSRL,大幅改善离线强化学习在小数据集上的学习性能。TSRL的核心是一个符合时间反演对称性(T-对称性)的动力学模型(TDM),其可为离线策略学习提供更好的表征,对泛化更友好的策略约束及可靠的数据增强。通过大量实验,我们发现TSRL在极小样本上表现十分出色,无论是在数据利用效率还是算法本身的泛化能力方面,即使只有原始样本的1%,该算法的性能也显著优于现有的离线强化学习算法。
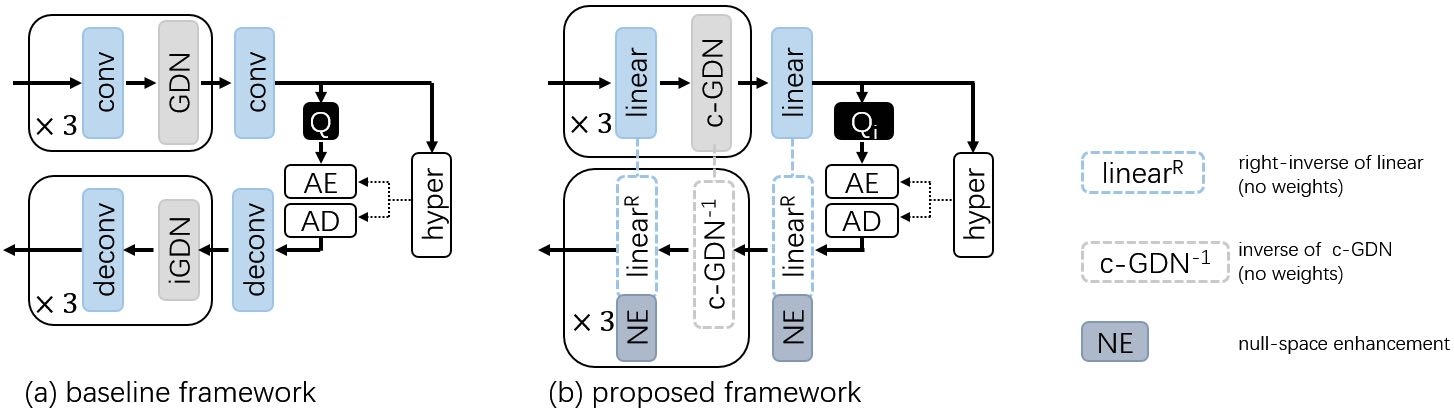
Idempotent Learned Image Compression with Right-Inverse
摘要:本文提出一种基于右逆(right-inverse)的幂等(idempotent)深度图像编解码器(DIC)框架。编解码器的幂等性是指编解码器对重新压缩的稳定性。为了实现幂等性,以前的编解码器采用可逆变换,例如离散余弦变换(DCT)和可逆流(invertible flow)。在本文中,课题组首先确定可逆变换对于幂等性来说是充分的,但不是必需的。实际上, 幂等性仅靠右逆变换就可以实现。并且,这种要求的放宽使得更复杂多样的变换函数成为可能。基于此,课题组提出用分块重排(block rearrangement)和零空间增强(zero-space enhancement)来实现幂等编解码器。多个数据集上的实验结果表明,研究成果实现了幂等编解码器中最先进的率失真性能。 此外,通过打破右可逆性,课题组提出的框架还可以实现近幂等编解码器, 且与其他近幂等编解码器相比,在 50 轮重新压缩后的质量衰减显著减少。
Flow-Based Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
作者
:
俞海宝,汤颖娟,谢恩泽,毛继磊,罗平,聂再清
单位
:清华大学智能产业研究院(AIR),
香港大学,北京理工大学
摘要:由于路端传感器安装位置高具备更广阔的视野,融合路端数据可以大幅提升自动驾驶感知能力。然而由于通信条件限制,协同感知存在不确定时延和通信带宽约束等问题,这些问题导致车路数据时空融合不对齐并限制了路端数据充分利用。针对这些挑战,本文提出了一种基于特征流(Feature Flow)的特征融合框架FFNet。与传统的只传输单帧静态特征的方法不同,FFNet从路端序列中提取带有时序预测能力的特征流,通过传输融合特征流从而实现车路数据的时空同步,有效解决时延带来的融合误差问题。本文还引入了一种自监督训练方法,使FFNet能够从路端原始序列生成具有特征预测能力的特征流。基于DAIR-V2X数据集的实验结果表明,我们提出的方法在不同时延上,仅需要原始数据传输成本的1/100,就能超越所有现有的协同检测方法。相关代码已开源在https://github.com/AIR-THU/DAIR-V2X。
Evaluation of Pedestrian Safety in a High-Fidelity Simulation Environment Framework
作者
:马琳,陈龙瑞,张研,江文杰,沈嘉浩,初梦迪,李楚璇,潘屹峰,时一峰,骆乃瑞 ,高旭,袁基睿,陈亦伦,周谷越,龚江涛
单位
:清华大学智能产业研究院(AIR),北京百度网讯科技有限公司
摘要:安全是自动驾驶的一个关键问题,在真实道路上测试之前,必须在仿真环境中进行测试。但是,大多数当前的自动驾驶仿真环境主要考虑的是车辆中的安全关键事件,而不是涉及难以仿真的行人的事件。考虑到行人是交通的重要的、最易受伤害的参与者,课题组提出了一种自动驾驶行人安全评价方法,包括了多维度的行人关键特性仿真和多层次的行人安全量化评估,并搭建了自研的高保真仿真环境对其性能进行实验测试。结果表明,课题组的行人仿真及评估方法可以有效地量化不同行人安全策略的性能。据了解,这是第一个在仿真平台上综合评价行人安全的方法,相关从业者可以将其自动驾驶算法与所提出的仿真评估框架相结合,以评估自动驾驶算法对行人的安全影响。
LUT-NN: Empower Efficient Neural Network Inference with Centroid Learning and Table Lookup
作者:唐小虎,王阳,曹婷,张丽,陈琪,蔡登,刘云新,杨懋
单位:清华大学智能产业研究院(AIR),浙江大学,微软亚洲研究院
会议:MobiCom 2023
摘要
:端侧深度神经网络(DNN)推理往往消耗大量的计算资源和开发工作。为了缓解这一问题,课题组提出了LUT-NN,第一个通过查表来实现神经网络推理的系统,以降低推理成本。LUT-NN学习每个算子的典型特征,称为质心,并预先计算这些质心的结果,保存在查找表中。在推理过程中,可以直接从表中读取与输入最接近的质心的结果,作为无需计算的近似输出。
LUT-NN集成了两个主要的新技术:(1)可微分的质心学习,其考虑了三个层次的近似,以最小化质心对准确性的影响;(2)基于查表的推理执行,它综合考虑不同层次的并行性、内存访问减少和专用硬件单元,以实现最佳性能。LUT-NN在多个真实任务上进行了评估,涵盖了图像和语音识别,以及自然语言处理。与相关工作相比,LUT-NN将准确性提高了66%到92%,达到了与原始模型相似的水平。LUT-NN在所有维度上都降低了成本,包括FLOPs(≤ 16×)、模型大小(≤ 7×)、延迟(≤ 6.8×)、内存(≤ 6.5×)和功耗(≤ 41.7%)。
NN-Stretch: Automatic Neural Network Branching for Parallel Inference on Heterogeneous Multi-Processors
作者
:魏剑宇,曹婷,曹士杰,姜世琦,傅绍伟,杨懋,张燕咏,刘云新
单位
:清华大学智能产业研究院(AIR),中国科学技术大学,微软亚洲研究院
摘要:移动设备越来越多地配备了异构多处理器,例如CPU + GPU + DSP。然而,现有的神经网络(NN)推理由于NN模型的串行结构,无法充分利用异构多处理器的计算能力。为此,本文提出了一种新的模型适应策略NN-Stretch,以及对应的支持系统。它根据处理器架构特征自动将给定的模型转为多分支结构。与其他常用的模型适应技术(如模型剪枝)相比,NN-Stretch在保持准确性的同时加速推理。
NN-Stretch的核心思想是水平拉伸模型结构,从一个长而窄的模型变成一个短而宽的多分支模型。课题组将模型分支形式化为一个优化问题。NN-Stretch通过考虑硬延迟约束来缩小设计空间,这些约束包括分支收敛的位置、每个分支如何缩放以适应异构处理器,以及软准确性约束,通过保持模型骨架和每个分支的表达能力。根据这些约束,NN-Stretch可以高效地生成准确和高效的多分支模型。为了方便部署,本文还设计了一种基于子图的空间调度器,用于现有的推理框架,以并行地执行多分支模型。课题组的实验结果非常有希望,在不牺牲准确性的情况下,与单CPU/GPU/DSP执行相比,速度提高了3.85倍。
ConvReLU++: Reference-based Lossless Acceleration of Conv-ReLU Operations on Mobile CPU
单位:清华大学智能产业研究院(AIR),上海交通大学
摘要:ReLU是卷积神经网络(CNN)中最常用的激活函数,使用ReLU的层中很多输出值都是零,利用这个特性,一种CNN的加速方法是通过估计和跳过零输出的冗余计算,但这往往需要牺牲准确性和繁琐的配置。在本文中,课题组介绍了一种无损加速方法ConvReLU++,用于在移动设备上进行CNN推理,它可以准确地检测和跳过零输出,从而实现加速,同时不会对网络输出结果有任何影响。这种检测方法的关键是采用基于参考值的上界计算,通过从一个卷积层中选定一个向量点乘运算作为参考,并以此估计其他点乘运算的上界,在检测到点乘运算上界为负时,即可以直接跳过剩余的计算。课题组严格证明了ConvReLU++的无损性质,分析了理论上的计算量节省,并展示了我们的方法与移动平台上的指令并行性的兼容性。本文课题组在流行的移动推理框架中实现了ConvReLU++,并在常见的深度视觉任务上进行了评估。结果表明,ConvReLU++可以在边缘设备上实现2.90%到8.91%的无损加速。
PAD: A Dataset and Benchmark for Pose-agnostic Anomaly Detection
作者
:周强,李维泽,江力涵,王国梁,周谷越,仉尚航,赵昊
单位
:清华大学智能产业研究院(AIR),武汉大学,北京大学
摘要:工业品异常检测任务是机器视觉领域的一个重要问题,近年来取得了显著进展。然而,两大挑战阻碍了其研究和应用。首先,现有数据集缺乏各种姿势角度下的全面视觉信息。它们通常有一个不切实际的假设,即无异常训练数据集是姿势对齐的,且测试与训练样本具有相同的姿势。然而,在实际应用中,异常可能来自不同的姿态,训练和测试样本也可能具有不同的姿态,这就需要研究姿态无关的异常检测;其次,对姿势无关异常检测的实验设置缺乏共识,导致不同方法之间的对比不公平,阻碍了姿势无关异常检测的研究。为了解决这些问题,课题组开发了多姿态异常检测(MAD)数据集和姿态无关异常检测(PAD)基准,向解决姿态无关异常检测问题迈出了第一步。具体来说,课题组使用了 20 个形状复杂的乐高玩具建立了 MAD 数据集,其中包括各种姿势的 4k 视图,以及模拟和真实环境中高质量、多样化的 3D 异常样本。此外,课题组还提出了使用 MAD 训练的 OmniposeAD,专门用于姿势无关异常检测。通过综合评估,证明了数据集和方法的优越性。此外,课题组还提供了一个开源基准库,其中包括涵盖 8 种异常检测范例的数据集和基准方法,以促进该领域的未来研究和应用。
Can Quadruped Guide Robots be Used as Guide Dogs?
作者
:
王璐瑶,陈启鹤,张研,李子昂,颜廷旻,王帆,周谷越,龚江涛
摘要:四足机器人常常被认为很适合作为机器导盲犬来引导盲人出行,因为它们具有高度灵活的运动和类似导盲犬的仿生形态。然而,四足导盲机器人的开发很少涉及BLV用户的参与式设计和评估。在本文中,课题组在室内控制和室外现场场景中进行了两次实证实验,定量定性结合,探讨了四足引导机器人的优点和缺点。结果表明,与轮式机器人相比,当今的商用四足机器人在可用性和信任度方面存在显着劣势。结果表明,四足机器人的移动步态和行走噪声会在一定程度上限制其引导效果,且其仿生形态对BLV用户的共情作用无法充分体现。基于轮式机器人和四足机器人优势的发现,课题组讨论了 BLV 用户未来引导机器人设计的设计意义。本文首次报道了盲人用户对四足导引机器人的实证实验,初步探索了其替代导盲犬的潜在改进空间,为四足导引机器人的进一步专业化设计提供了启发。