清华大学智能产业研究院(AIR)携手水木分子开源全球首个可商用多模态生物医药百亿参数大模型BioMedGPT-10B,该模型在生物医药专业领域问答能力比肩人类专家水平,在自然语言、分子、蛋白质跨模态问答任务上达到SOTA。同时,双方还联合开源了全球首个免费可商用、生物医药专用Llama 2大语言模型BioMedGPT-LM-7B。“AIR-智源健康计算联合研究中心” 合作开源了小分子药物基础模型DrugFM。此次开源的生物医药基础模型重科研、可商用,为生物医药研究与应用提供大模型底座。
开源地址:
https://github.com/PharMolix/OpenBioMed
https://huggingface.co/PharMolix/BioMedGPT-LM-7B
研究动机 打通自然语言与化学、生物编码语言
清华大学智能产业研究院(AIR)首席研究员、水木分子首席科学家聂再清表示:“大模型最令我们惊喜的是智能涌现与触类旁通的能力。生命现象本质也是一种自然进化的语言编码,如果能够将人类总结的知识与氨基酸、分子、蛋白数据压缩到统一的大模型框架内进行编码与学习,有望能够理解生物编码的语言机制,进而从底层推动与生命科学相关的研究与应用。”
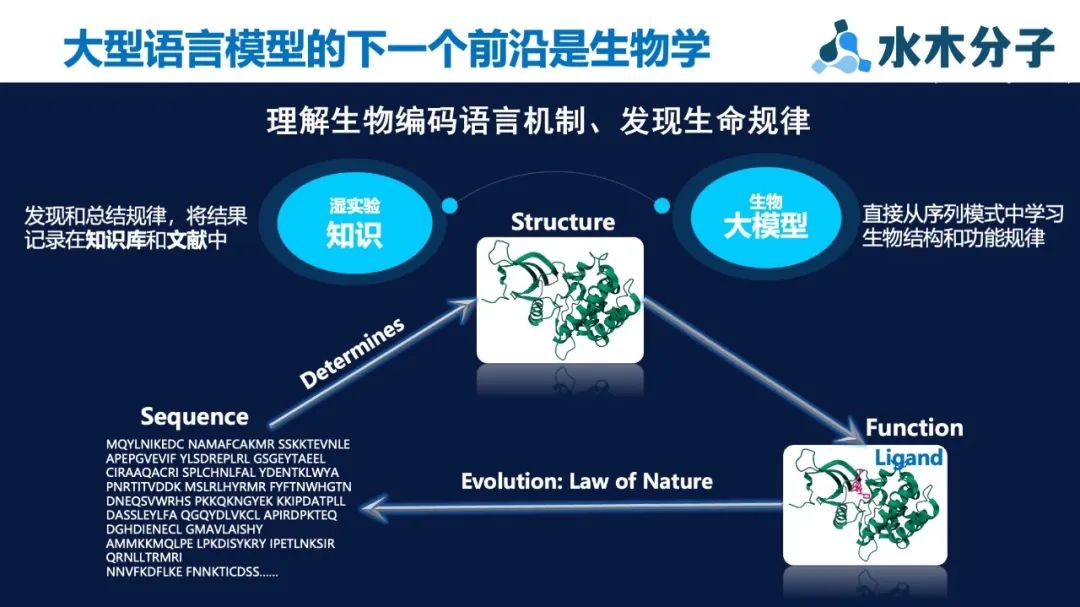
聂再清教授团队提出了一种全新的多模态语义理解框架 BioMedGPT,它运用了生物医学领域中的预训练大语言模型—BioMedGPT-LM作为桥梁,将自然语言、生物编码语言以及化学分子语言等连接起来。
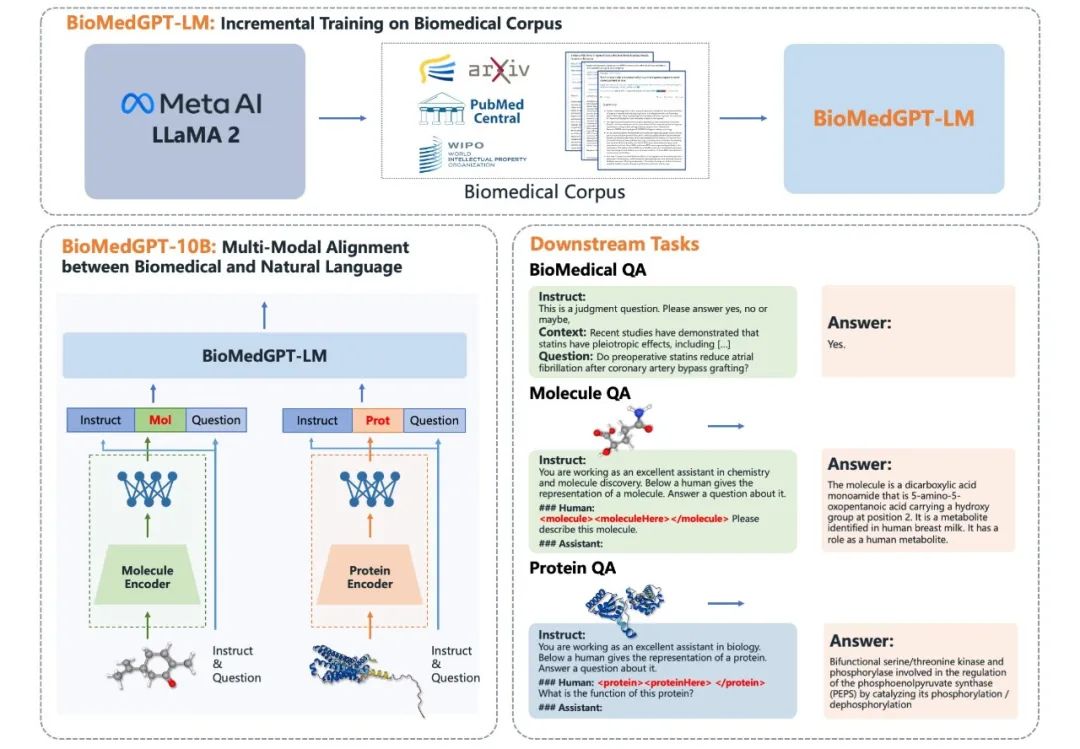
BioMedGPT-LM 通过充分利用海量生物医学相关数据,对通用的基于GPT架构的大型语言模型进行微调,在生物医学领域发挥更出色的性能。作为连接桥梁,BioMedGPT-LM能够连接各种生物模态的编码,包括分子、蛋白质、细胞和基因表达数据,同时还能够整合知识图谱、文档、数值实验结果以及其他格式所体现的专业知识。通过跨模态特征融合模块集成,不同模态的生物编码语言、化学分子语言与自然语言能够在同一个特征空间中实现统一融合。
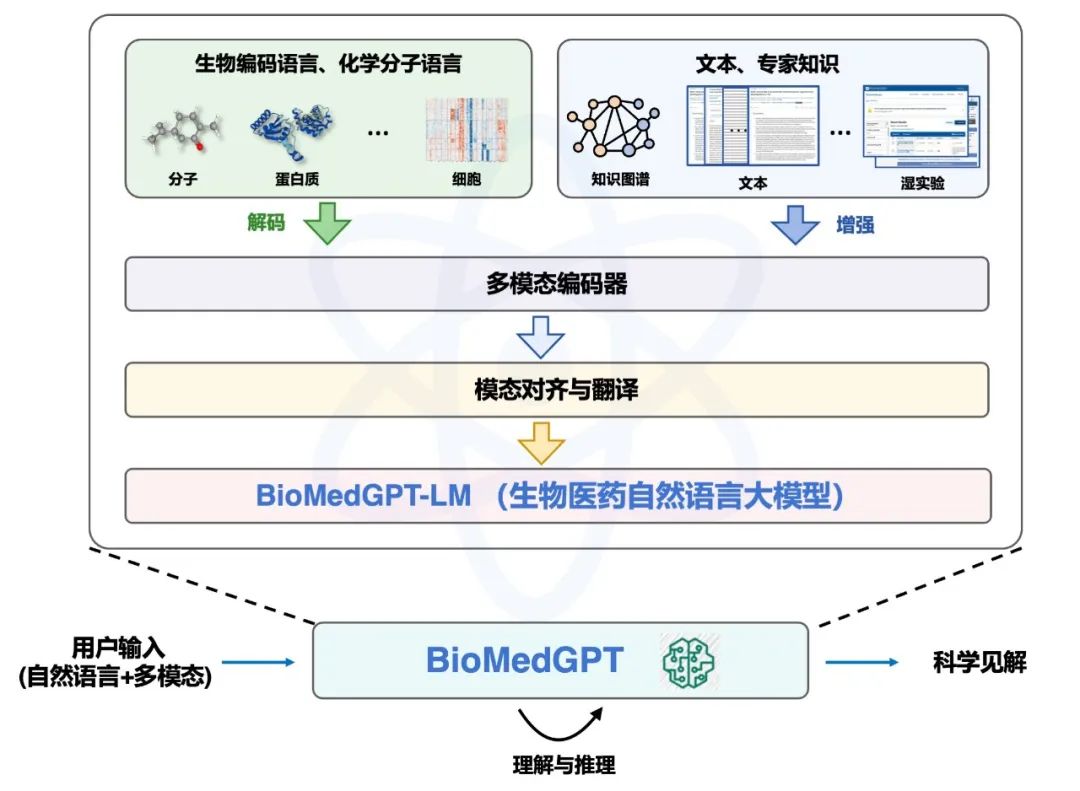
BioMedGPT架构
BioMedGPT-10B 全球首个开源可商用多模态生物医药百亿参数大模型
BioMedGPT-10B作为BioMedGPT的一个开源且可商用的具体实例,建立了文本、分子和蛋白质三个模态的统一特征空间。它支持跨模态自然语言和分子语言的交互式问答,可在药物靶点探索与挖掘、先导化合物设计与优化、蛋白质设计等领域得以应用。同时,在生物医药领域的语言理解能力得到显著提升,在多个生物医药问答基准数据集上实现了SOTA,比肩人类医学专家水平,已成功通过了美国医师资格考试。
通过精心设计的Instruct方法,将不同编码结构的生物医学数据映射到一个共同的文本模态特征空间中,实现了数据的统一性,不同模态的数据可以在相同的语义空间中进行比较和交互。
为了进行分子、蛋白质到自然语言的对齐,我们专门构建并开源了分子-文本问答(PubChem QA)数据集和蛋白质-文本问答(UniProt QA)数据集。分子-文本问答(PubChem QA)数据集用于对齐分子和自然语言语义,包含来自PubChem的 325, 754 个分子和365, 129个分子-文本描述。蛋白质-文本问答(UniProt QA)数据集,包含来自UniProt的 569, 516 个蛋白质,涵盖蛋白质相应的名称、蛋白质功能、亚细胞定位和蛋白质家族信息,共计生成了 1, 891, 506 个蛋白质序列-文本描述问答数据。以上数据集现阶段只支持单轮对话,而聂再清教授团队正在进行多轮版本的打造。
下面重点介绍模型在典型任务中的表现:
该任务针对输入分子式生成对该分子的自然语言描述,同时支持进一步问答,用于探索该分子相关信息。在该任务下,采用了一个经典的分子文本生成任务数据集 ChEBI-20来评估BioMedGPT在处理自然语言和分子语言之间的理解与转化能力。实验针对BioMedGPT-10B的性能与几个基线模型进行了对比。结果表明,BioMedGPT-10B在分子文本生成任务上全面超越了通用语言模型。

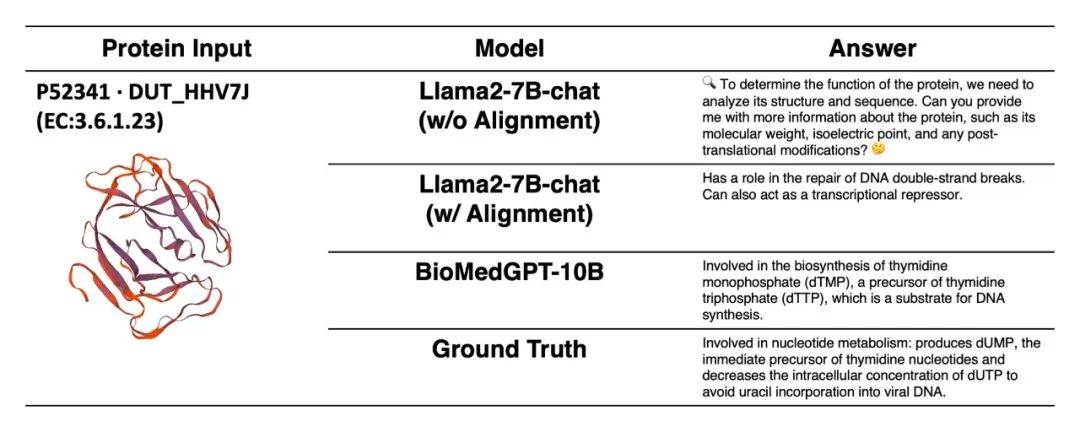
该任务针对输入蛋白序列生成对该蛋白的自然语言描述,同时支持进一步问答,可支撑药物靶点发现、靶点挖掘研究。基于UniProt QA数据集进行了系列对比实验,显示出BioMedGPT-10B 在蛋白质-文本跨模态理解和翻译上的能力。以下图为例,未经过对齐的LLama2-7B-chat无法理解输入的蛋白质数据,经过模态对齐后LLama2-7B-chat能通过提问获悉用户意图是想了解蛋白质功能,但仍然无法提供准确和有信息量的回答。BioMedGPT-10B的回答则更精确、全面、明确指出了蛋白质P52341在胸腺嘧啶核苷酸的生物合成中的作用,更接近于标准答案。
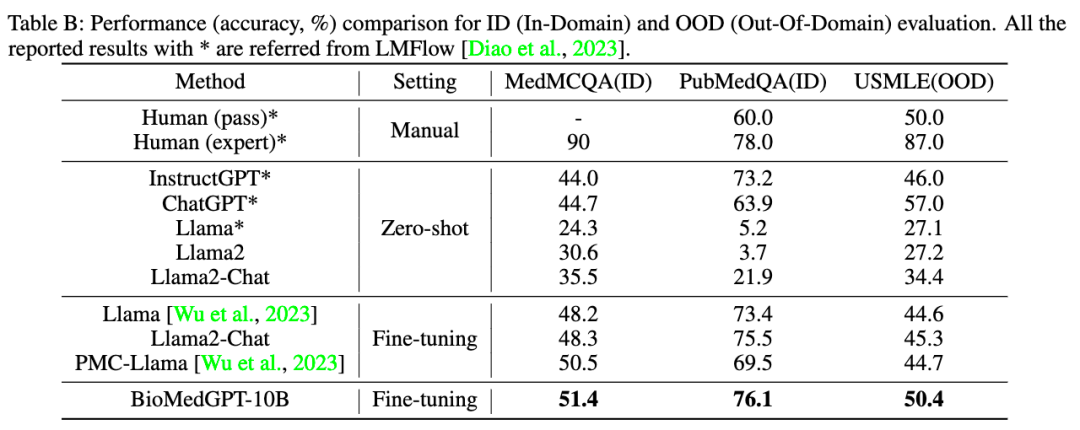
BioMedGPT的语言模型 BioMedGPT-LM 在大规模的生物医学文献数据上进行了训练,其语言能力在生物医学领域表现更为出色。在生物医药领域的三个基准数据集,USMLE、MedMCQA和PubMedQA 达到业内领先水平,在专业生物医学问答方面能够媲美医学专家,成功通过了美国医师资格考。
BioMedGPT-10B 在 PubMedQA 上的准确率达到 76.1%,仅比人类专家(expert)标准低 1.9%。在 OOD (Out-of-Domain)设置中,BioMedGPT-10B 的准确率为 50.4%,是除ChatGPT外唯一一个超过人类人工性能(pass)的模型。但值得一提的是,ChatGPT的参数量是BioMedGPT-10B的17倍以上。
MolFM/DrugFM 小分子药物基础模型
本次与BioMedGPT-10B一同开源的还有小分子药物基础模型:MolFM/DrugFM。MolFM 由 AIR 聂再清教授团队研发,是首个能够统一表示分子结构、生物医学文献以及知识库的基础模型。MolFM 引入了跨模态注意力机制,将分子结构中的原子、分子实体的邻居以及与之相关的语义文本相连接。通过在特征空间中最小化同一分子的不同模态以及具有相似结构或功能的分子之间的距离,MolFM 能够捕获局部和全局的分子知识,从而促进跨模态的理解。MolFM的有效性已在各种下游任务中得到广泛验证,包括跨模态检索、分子描述、分子-文本生成和分子特性预测。MolFM: A Multimodal Molecular Foundation https://arxiv.org/abs/2307.09484
DrugFM由“清华AIR-智源联合研究中心”联合研发,AIR兰艳艳教授团队针对小分子药物的核心组织规律与数据表示进行了更前沿的探索与更精细设计,形成有效的小分子药物预训练模型 UniMAP。同时,将该小分子药物预训练模型与已有的多模态小分子药物基础大模型MolFM有机结合。模型在Cross-modal Retrieval 跨模态检索任务取得SOTA。DrugFM 作为小分子药物基础科研模型,将持续迭代,有效支撑和提升小分子药物筛选、设计、优化等相关下游任务。

水木分子:水木分子由清华大学智能产业研究院(AIR)孵化,清华大学国强教授、AIR首席研究员聂再清教授担任首席科学家。致力于打造生物医药行业基础大模型及新一代对话式生物医药研发助手。公司产品将服务于药物研发各环节,包括早研立项、靶点发现、分子设计优化、临床实验设计、药物重定位等。
清华AIR-智源健康计算联合研究中心:由清华大学智能产业研究院与北京智源人工智能研究院于2021年8月联合成立,致力于通过人工智能技术推动生命健康各领域从孤立、开环走向协同、闭环发展,在智能生物计算、智能新药研发、主动式健康管理等领域开展研究合作。