近日,清华大学智能产业研究院(AIR)、微众银行和美国明尼苏达大学等单位合作在《IEEE Transactions on Signal Processing》期刊(简称:IEEE TSP,创刊于1991年,是“信息与通信工程”学科的国际顶级期刊,最新影响因子为5.028,中科院分区工程技术大类一区)发表了学术论文:FedBCD: A Communication-Effificient Collaborative Learning Framework for Distributed Features。研究团队提出了面向分布式特征的纵向联邦学习的高效通信协作学习框架,突破了传统纵向联邦学习通信瓶颈并提高了安全性,助力跨机构间数据价值流通。
▲图1 | 相关论文(来源:IEEE Transactions on Signal Processing)
近年来,个人数据隐私泄露和数据滥用事件频发,不仅影响着个人权益安全和国家安全,也严重制约着数据价值潜能释放。为了加强对数据安全和个人隐私的保护,全球各国纷纷出台了相关法律法规,例如我国的《数据安全法》与《个人信息保护法》、欧盟的GDPR、新加坡的PDPA、美国的CCPA等。在全球对数据使用监管趋严和数据成为生产要素的新形势下,各互联网平台和企业均面临极大挑战,如何既保护用户隐私,又实现数据挖掘、创造商业价值是亟待解决的关键问题。
在此背景下,隐私计算因其能确保数据“可用不可见”方面的独特优势而受到广泛关注,已经成为助力数字经济发展、构建数据要素市场不可或缺的重要支撑技术。近日,科技部等六部门联合印发了《关于加快场景创新以人工智能高水平应用促进经济高质量发展的指导意见》。《指导意见》中提出:要采用区块链、隐私计算等新技术,在确保数据安全的前提下,为人工智能典型应用场景提供数据开放服务。
联邦学习作为实现隐私计算的重要技术路径之一,专门用于解决数据隐私保护下跨机构或跨设备间模型训练的问题。其主要目标是在满足用户隐私保护和数据安全的前提下,利用分散在用户设备上或机构间的数据进行分布式的模型训练,而不需要将原始数据集中汇聚。与传统的将原始数据集中进行模型训练相比,极大地保护了用户数据安全和隐私安全,增强了数据使用的合规性。
联邦学习可具体细分为横向联邦学习、纵向联邦学习和联邦迁移学习。其中,多主体分布式特征下的协作学习属于纵向联邦学习,是一类应用广泛的联邦学习问题,适用于用户重叠多、特征互补的联邦建模应用场景。例如同一地区的零售商和银行进行联合营销,他们触达的用户都为该地区的居民(样本相同),但业务不同(特征不同)。由于其在解决企业数据孤岛上广泛的应用价值,近年来纵向联邦学习的基础训练框架已经被多个国际国内隐私计算项目作为基础支撑算法实现,并在金融、营销、政务等场景广泛应用。
然而,现有的纵向联邦学习框架依然面临严峻的通讯效率瓶颈,在实际应用中往往只能支撑简单易用的线性回归和树模型训练。随着人工智能尤其是深度学习技术的广泛应用,如何建立支持神经网络等复杂计算的大规模可扩展的纵向联邦学习框架是联邦学习研究领域所面临的关键问题。在纵向联邦学习的训练过程中,多主体需要每次迭代时实时交换梯度更新信息进行联合计算和训练,导致通信效率成为决定纵向联邦学习框架可扩展性的主要瓶颈问题,制约了纵向联邦学习的广泛应用。
在基于样本分割的横向联邦学习中,被最为广泛使用的联邦平均(FedAvg)算法,运行随机梯度下降(SGD)并行进行多次本地局部更新,可以实现更好的通信效率。那么,在纵向联邦学习中,是否可以采用多次本地局部更新这一思路来协作减少通信开销呢?即在纵向联邦学习中,是否可以达到“联邦平均”同样的效果?这并不是一个容易回答的问题。协作效率与模型效果、数据安全均是联邦学习的关键指标,而他们又存在矛盾和平衡。对于效率的优化还要同时考虑算法的收敛性和传输信息的动态变化导致的安全问题,这增加了解决这一问题的难度。但在基于特征分割的纵向学习中,每次迭代的梯度计算需要各参与方共同协作完成而非简单加权平均。
鉴于以上问题,AIR副教授刘洋及合作团队在论文中提出了一种面向分布式特征的高效纵向联邦学习框架(如图2所示),通过系统地采用本地Block Coordinate Descent (BCD)算法和联邦协作,在保证理论收敛性的指导下进行足够数量的局部更新来解决纵向联邦学习场景中昂贵的通信开销问题。该纵向联邦学习方法允许具有关于同一用户不同属性集的多方联合构建模型,而无需公开其原始数据或模型参数,算法具体交互流程如图3所示。
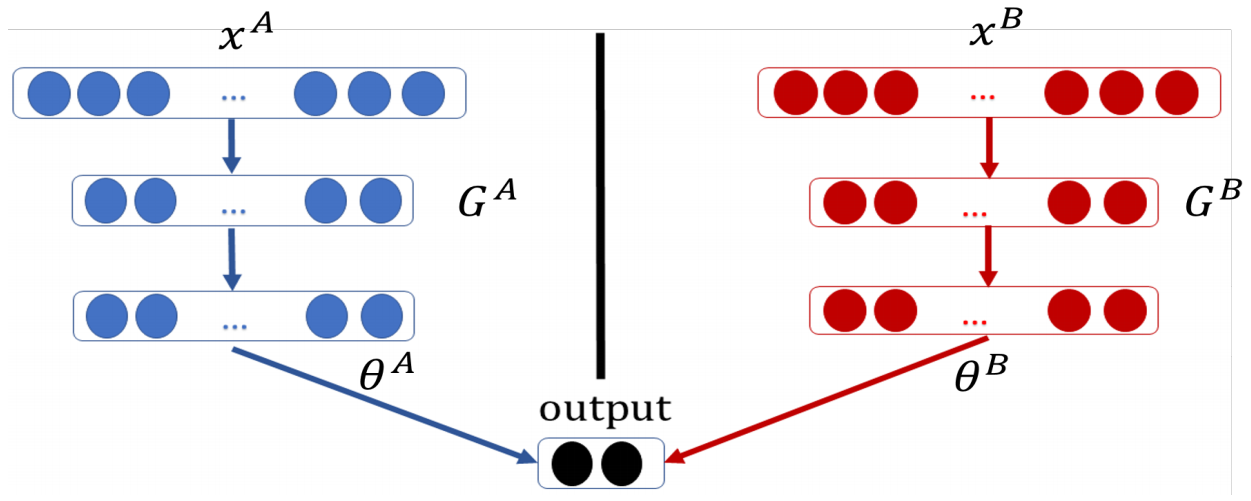
▲图2 | 一个基于神经网络(NN)的局部模型的两方协作学习框架(来源:研究论文)
▲图3 | FedBCD算法:FedBCD-s算法和 FedBCD-p算法(来源:研究论文)
在FedBCD算法中,双方在训练前或训练后都不学习其他参与方的数据或模型参数,与集中式训练的模型相比,协作模型的性能没有损失。此外,在实用安全模型下,论文还进一步证明了无论要执行多少次通信迭代,从传输的明文中间结果中都无法反推确切的原始数据,即各方均无法从纵向联邦学习框架中交换的信息集合里推断出其他人的确切原始特征。
此外,论文还对FedBCD算法进行了广泛的实验评估(如图4、5所示),在医疗(MIMIC-III)、多模态(NUS-WIDE)、金融(Default-Credit)、图像(MNIST)等数据集上测试了包括线性回归、神经网络和联邦迁移学习等多项训练任务。实验结果表明论文所提方法显著减少了通信轮次和总通信开销。从理论上,论文首次给出了FedBCD算法在全局收敛速度的证明,并证明了FedBCD算法相比传统纵向联邦学习算法在通讯效率上更优。
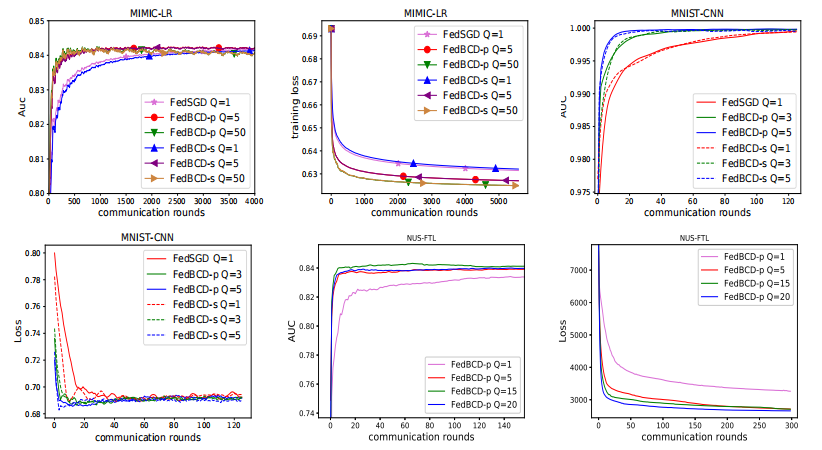
▲图4 | MIMIC-LR、MNIST-CNN、NUS-FTL与不同Q局部迭代的AUC和训练损失的比较(来源:研究论文)
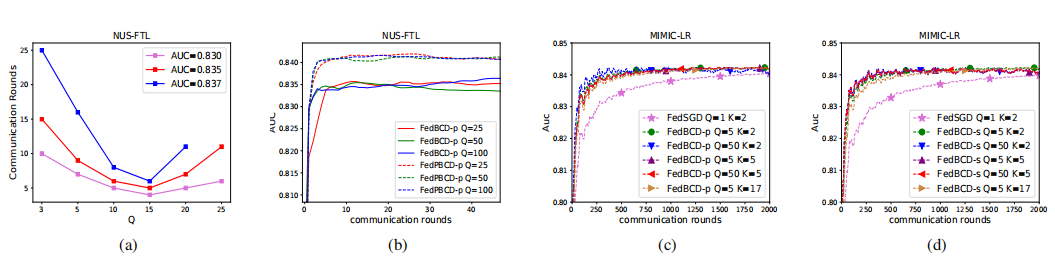
▲图5 | (a) 通信轮次VS Q. (b) FedBCD-p和FedPBCD-p之间的大型局部迭代比较。MIMIC-III 数据集中的AUC与不同的Q和参与方数量K的比较。(c) FedBCD-p;(d) FedBCD-s。(来源:研究论文)
目前,FedBCD算法已经在联邦学习产业级的主流开源平台FATE上的基于神经网络的联邦迁移学习模块中实现。根据中国信通院、隐私计算联盟等单位联合发布的《隐私计算白皮书(2021年)》中指出,国内55%的隐私计算产品是基于或参考了以FATE为主的开源项目开发的。FedBCD算法适用于通用的纵向联邦学习框架,可用于解决纵向联邦学习尤其是基于神经网络的纵向联邦学习效率低的问题,其像联邦平均算法一样实现简单,并不需要额外的计算并适用于具有任意局部子模型的纵向联邦建模,可广泛引入现有纵向联邦学习中应用于医疗、金融、政务、通信和营销等领域。
论文第一作者为AIR刘洋副教授和明尼苏达大学张欣为博士,通讯作者为刘洋副教授和微众银行首席AI官杨强教授。刘洋副教授的研究领域包括机器学习、联邦学习(FL)、隐私计算等,及其产业应用(加入团队:【招聘】大数据与人工智能团队)。杨强教授是香港科技大学讲席教授、加拿大皇家科学院和工程院院士,研究领域包括迁移学习、联邦学习、机器学习、数据挖掘和自动规划。论文的合著作者还包括美国明尼苏达大学的洪明毅教授,他的研究方向包括优化算法、信息处理、无线网络等。
参考资料:
[1]Y. Liu et al., "FedBCD: A Communication-Efficient Collaborative Learning Framework for Distributed Features," in IEEE Transactions on Signal Processing, 2022, doi: 10.1109/TSP.2022.3198176.