近日,中国云产业联盟暨中关村云计算产业联盟(简称“云联盟”)承办的“2023全球数字经济大会·云融技术创新引领论坛”成功举办。清华大学国强教授、清华大学智能产业研究院(AIR)首席研究员、水木分子首席科学家聂再清教授做了题为《AI大模型行业机遇与挑战》的主题报告。

报告中,聂再清教授首先提到:以ChatGPT为代表的大模型有两个明显的能力特征:
第一,“触类旁通”能力。就是通过Instruction Learning等新学习算法进行训练时,在N-1个任务上进行训练,在第N个从未见过的相关任务上也会有性能的提升。通过Instruction Learning进来进行学习,大语言模型把人类的很多语言、语义在模型层面进行了连接。还可以通过强化学习把N加到很大,从学到的Reward Model来产生监督信号。
第二,“智能涌现”能力。很多科学实验已经证实,通过把模型的参数做大,参数规模大到一定程度以后很多任务的性能可能有一个极速的提升,像NLP的很多任务能够在100亿参数的时候,性能会大幅提升,实现了量变到质变的转换。

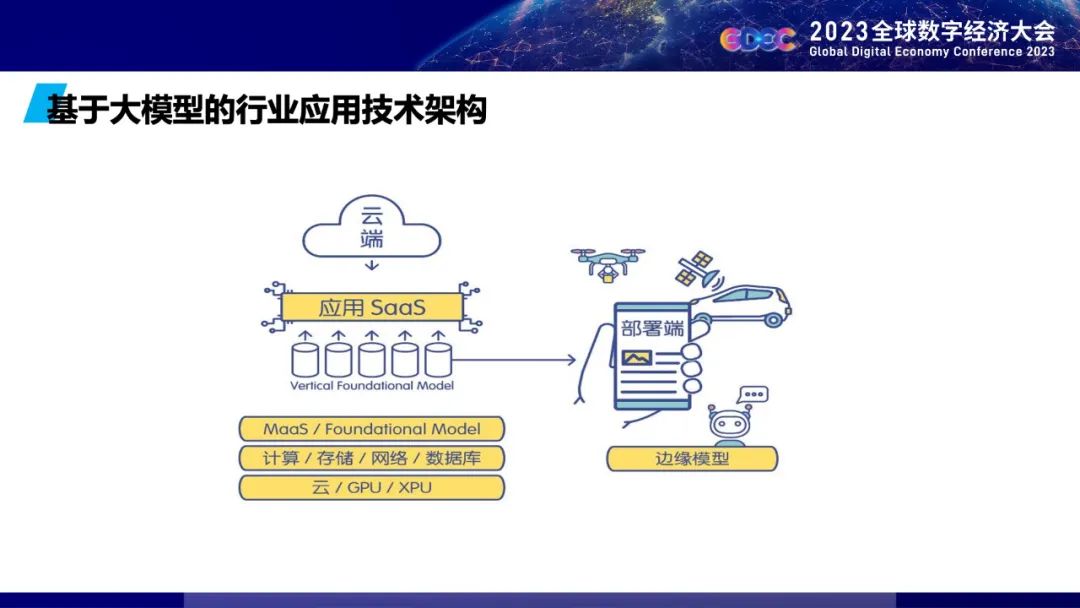
聂再清教授指出:“触类旁通”和“智能涌现”能力,开启了通向通用人工智能之路的曙光,基础大模型+行业大模型会成为人工智能时代的操作系统,链接行业应用。结合自己的工作实践,就大模型分别在自动驾驶和生物医药领域中的应用,分享了自己的见解。
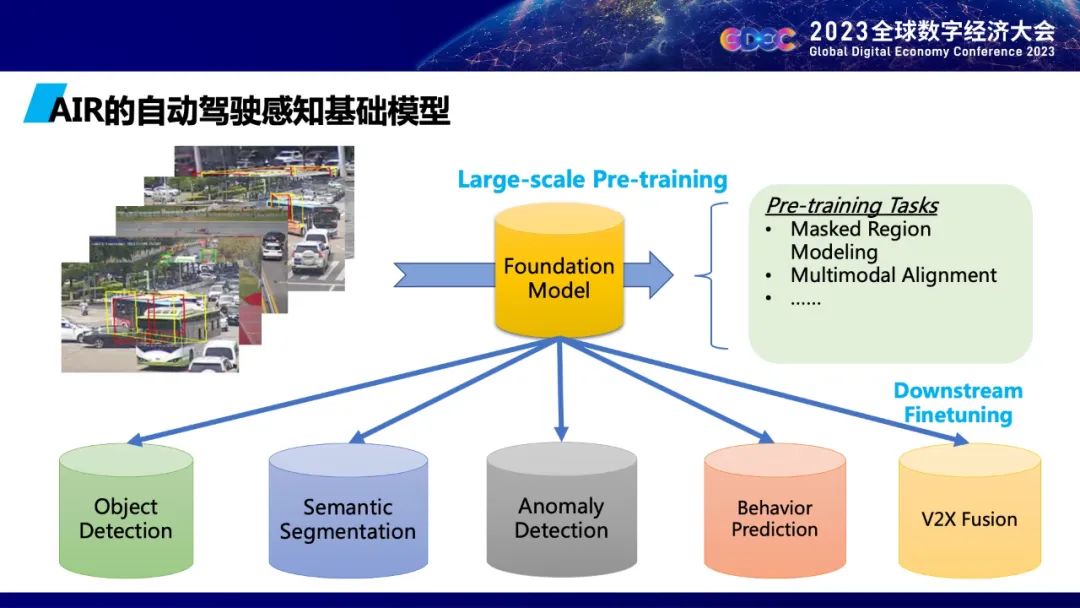
自动驾驶有感知、认知、决策以及控制等不同模块组成,数据输入以后,经过不同模块处理后能够实现自动驾驶或者辅助驾驶。在传统自动驾驶系统里边,各个模块比较独立,像对象检测、语义分割、异常检测、行为预测等没有统一的大模型来把它统一起来,每一个模块都需要做大量的标注。基于自监督的自动驾驶大模型,可以实现下游的模型通过这个自动驾驶Foundation Model赋能下游每一个模型,能够解决很多安全性的问题。自动驾驶的基础模型是清华大学智能产业研究院正在做的比较重要的研究项目。
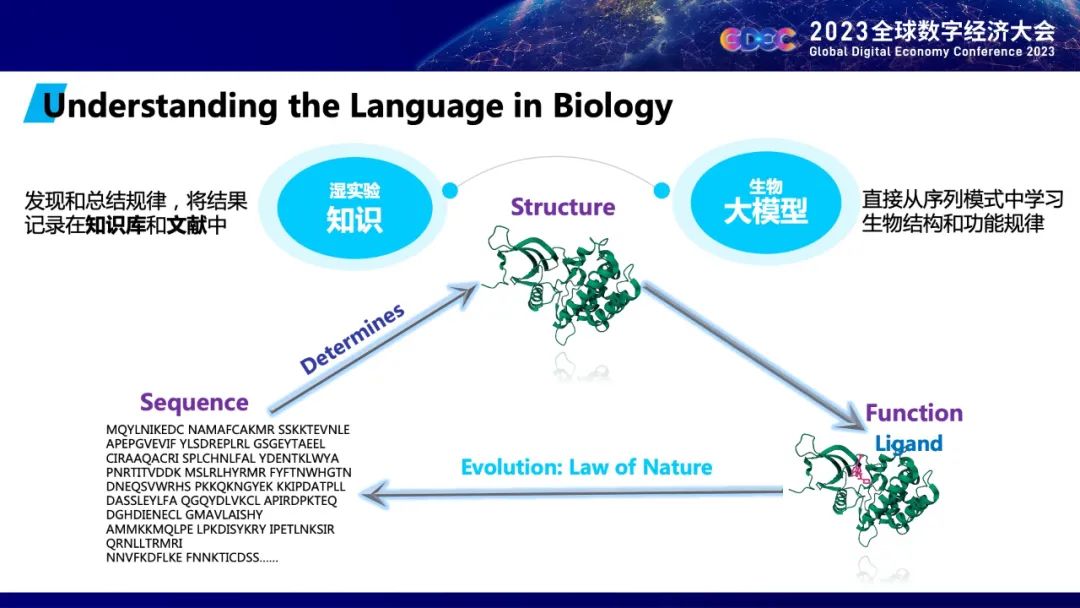
在生物医药领域,分子语言和自然语言也很像。一个蛋白质的信息,可以表示成为一个字符序列。而这些字符序列就能够决定蛋白质的结构,蛋白质的结构又决定了蛋白质的功能以及跟药物的结合亲和力。蛋白质的功能规范又决定了下一次基因变异导致的新蛋白的生存和遗传概率,通过自然法则的选择,只有真正合理的那部分序列才会产生出来,这跟自然语言有语法限制是一样的。
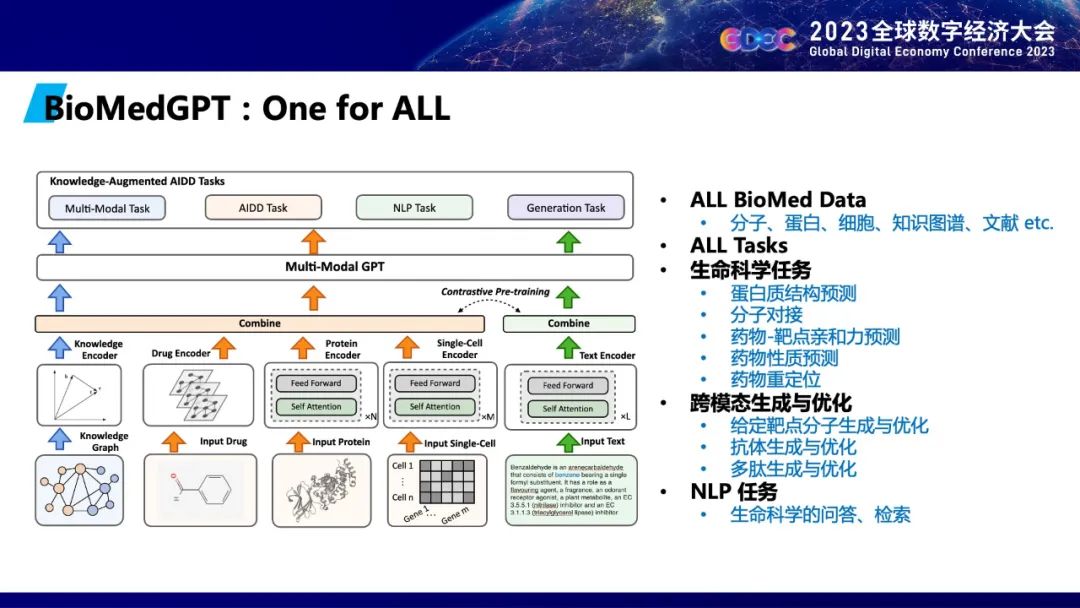
目前,在生物医药领域已经有许多多模态数据。除了蛋白大分子数据,还有海量的可成药小分子数据和单细胞的数据。同时,还有自然语言文本(像论文)和知识图谱这样的不同模态的数据。每一个数据都能够自监督的学习出一个大模型出来。这样对于一个靶点JAK1,可以通过大模型学到的向量来表示,而其相对应的小分子药物也可以有小分子的表示。当然除了分子序列信息这个模态,也可以通过人类总结的海量论文和知识图谱信息这些模态的信息来自监督学习相应大模型,用以表示这个靶点和小分子药。清华大学智能产业研究院正在和水木分子公司合作把知识图谱、分子序列和文本融合在一起生成一个生物医药的多模态大模型,第一次把微观分子、单细胞、知识的表示融合在一起,能够支持NLP、生命科学、跨模态的任务。
未来还会不断的把BioMedGPT进行更新, BioMedGPT可以通用大模型和很多行业内的工具结合起来,一起赋能到下游生物医药的研发任务,像靶点发现、高通量的药物筛选、药物重定位等任务。希望能够通过产业和科学的研究,能够把真正的行业大模型建立起来。
聂再清教授总结到:ChatGPT是一个非常具有影响力的进展,它有触类旁通的能力,让我们感觉到了通用人工智能时代的曙光。未来基础大模型一定会成为AI时代的操作系统。每个行业也都会有属于自己行业的垂直大模型,会把该行业的工具、数据总结在一起,解决行业里面的各种任务。