过去半年来,AIR围绕智慧交通、智慧医疗、智慧物联三大研究方向开展系统深入的研究,并在CVPR、ICRA、ICLR和MobiSys等重要国际期刊和会议上发表多篇高水平论文,
并获得ICLR杰出论文奖提名、IEEE Micro年度论文(Top Picks)提名奖等奖项,在最近的ICLR 2023会议上,AIR共计14篇论文被录用。
今天,小编就为大家精选了一些AIR近期的亮点论文,并梳理了摘要解读,文末可获取完整论文打包下载方式。
Bit Allocation using Optimization
作者
:
许通达,高寒,高宸健,王园园,何岱岚,皮金勇,骆继祥,诸子钰,叶茂,秦红伟,王岩,刘菁菁,张亚勤
单位:
清华大学智能产业研究院(AIR),商汤科技,电子科技大学,北京航空航天大学
摘要:
在本文中,我们考虑了神经视频压缩(NVC)中的比特分配问题。首先,我们揭示了NVC中的比特分配与半均摊变分推理(SAVI)之间的基本关系。具体地说,我们证明了具有GoP(图片组)级似然的SAVI等价于具有精确的码率和质量依赖模型的像素级比特分配。基于这种等价性,我们使用SAVI建立了一种新的比特分配范式。与以前的比特分配方法不同,我们的方法不需要经验模型,因此是最优的。此外,由于使用梯度上升的原始SAVI仅适用于单级隐变量,我们通过递归地应用梯度上升内的反向传播将SAVI扩展到多级隐变量,如NVC。最后,我们为实际实现提出了一个易于处理的近似算法。我们的方法可以应用于性能的重要性超过编码速度的场景,且可以作为比特分配在R-D性能的经验上界。实验结果表明,与我们的算法相比,目前最先进的比特分配算法仍有约0.5 dB的PSNR改进空间。
我们的代码开源在 https://github.com/tongdaxu/Bit-Allocation-Using-Optimization
Offline RL with No OOD Actions: In-Sample Learning via Implicit Value Regularization
作者
:
徐浩
然,姜力,李健雄,杨卓然,汪昭然,詹仙园
单位:
清
华大学智能产业研究院(AIR),清华大学,耶鲁大学,西北大学
摘要:现有大多数离线强化学习方法都面临着改进策略以超越行为策略,或者限制策略以减少偏离行为策略这两个抉择。最近提出的样本内学习范式通过仅使用数据样本进行分位数回归来改进策略,这一范式能够学习到最佳策略却不查询任何未见动作的值函数。在这项工作中,我们发现样本内学习范式是在隐式值正则化框架下产生的。这解释了为什么样本内学习范式有效,即它对策略应用了隐式值正则化。基于此框架,我们进一步提出了两个实用的算法:稀疏Q学习和指数Q学习,它们采用了现有工作中使用的相同值正则化,但是以完全样本内的方式进行。本文在不同场景下验证了提出算法的有效性和优势。
DPF: Learning Dense Prediction Fields with Weak Supervision
作者:陈小雪,郑宇航,郑宇鹏,周强,赵昊,周谷越,张亚勤
单位:清华大学智能产业研究院(AIR),清华大学计算机系,北京航空航天大学,中科院自动化所
会议:CVPR 2023
摘要:密集预测(Dense Prediction)网络是解决诸如语义分割和图像本征分解(Intrinsic Decomposition)等场景理解问题的基本框架。现有工作通常使用像素级标注作为训练密集预测模型的监督。但是像素级别的密集标注非常昂贵, 对一些任务也无法给出精准的像素标注,如在图像本征分解中为野外(In-the-wild)图像标注特定的反射率。这促使我们转而利用廉价的稀疏点监督来训练密集预测网络。为利用点监督的自身特性,我们提出了一种基于坐标点查询的密集预测网络,它可以预测图像空间中每个连续二维坐标点的对应值,该方法被命名为密集预测场(Dense Prediction Field, DPF)。受最近成功的隐式表示的启发,我们使用隐式神经函数来实现 DPF。DPF 为连续的二维空间位置生成可解析的视觉特征,从而允许输出任意分辨率的预测结果。为在语义分割和图像本征分解任务上验证 DPF 的有效性,我们以三个大型公开数据集PASCALContext、ADE20K和IIW为benchmark,DPF在上述数据集上均达到目前最好的实验结果,相比前人方法有显著提升。
代码和模型见:https://github.com/cxx226/DPF。
ADAPT: Action-aware Driving Caption Transformer
作者:晋步,刘昕煜,郑宇鹏,李鹏飞,赵昊,张通,郑宇航,周谷越,刘菁菁
单位
:
清华大学智能产业研究院(AIR),中科院自动化所,清华大学计算机系,西安电子科技大学,南方科技大学,北京航空航天大学
摘要:
在过去十年中,自动驾驶技术取得了重大进展,但很多方法将自动驾驶视为监督学习问题,从人类驾驶行为中学习驾驶策略,如使用深度神经网络,输入车辆前视图像和车辆状态,预测车辆的未来运动。
尽管这些方法具有潜力,但其无法展示系统决策的基本原理,这使得系统决策过程变得不透明且缺乏可解释性。
此前,有人尝试使用视觉注意图(Attention Map)或者成本量图(Cost Volume)来解释自动驾驶模型,但由于用户对于智能系统算法的不熟悉,这些方法很难被乘客理解。
而文本解释可以解决这个问题,自然语言的优势在于其本质上易于理解,即使用户不熟悉自动驾驶算法,也能理解车辆执行决策的原因,例如,“[描述]:
the car pulls over to the right side of the road,[解释]:
because the car is parking”。
为此,我们提出了第一个基于端到端Transformer的架构:
ADAPT(Action-aware Driving cAPtion Transformer),它可以为乘客提供自然语言形式的车辆决策描述和原因解释。
我们采用多任务学习的方法来联合训练车辆决策任务和文本描述任务,以减少任务之间的差异。
我们在大规模数据集BDD-X上验证了ADAPT的有效性,并在实车测试中取得了优秀的结果。
代码和模型见:https://github.com/jxbbb/ADAPT
Annotating Covert Hazardous Driving Scenarios Online: Utilizing Drivers' Electroencephalography (EEG) Signals
作者:郑琛,訾慕肖,江文杰,初梦迪,张研,袁基睿,周谷越,龚江涛
摘要:
随着自动驾驶的普及,自动驾驶系统从细粒度驾驶场景数据库中进行学习变得越发重要。目前大多数可用的数据库都由人类标注,因此这些数据库的获得十分昂贵且耗时,更重要的是人类标注不可避免地受到人类认知和行为偏差的影响。本文提出了一种基于驾驶员脑电(EEG)信号的驾驶风险标注技术,并给出支持这一标注技术的初步证据。我们邀请了10位有十年以上驾驶经验的驾校教练员观看真实和模拟驾驶场景视频,其中包含显性驾驶风险(如车辆或行人突然出现或从遮挡物后冲出)和隐性驾驶风险(如遮挡物)。受试者的任务是在探查到视频中的驾驶风险时迅速按键报告。我们在受试者观看驾驶场景视频的同时记录了它们的脑电信号。结果发现,受试者几乎只在显性风险出现时按键报告,但它们的脑电信号在显性风险和隐性风险出现时都会增强。因此,受试者的口头标注仅对显性驾驶风险敏感,因而其在标注过程中会忽视内隐风险的存在,而其脑电信号对显性和隐性风险均敏感,利用受试者的脑电信号对驾驶风险进行标注比其口头报告具有更高的准确性。为了探索这一技术的可行性,我们用Time-Series AI根据受试者的脑电信号对其看到的驾驶风险进行了分类。本文还讨论了实现这一标注技术所需的后续工作。
Breaching FedMD: Image Recovery via Paired-Logits Inversion Attack
作者:
Hide
aki Takahashi,刘菁菁,刘洋Veronica
摘要:使用模型蒸馏的联邦学习(FedMD)是一种新兴的协作式学习范例,它仅传输公共数据集的精炼知识,而不是传递易受梯度泄漏攻击影响的私有模型参数。本文发现,即使共享公共数据集的输出暗知识比直接共享模型更安全,仍然存在由精心设计的恶意攻击引起的数据曝光风险。我们的研究表明,恶意服务器可以通过训练一个利用服务器和客户端模型之间置信度差距的反转神经网络,针对FedMD及其变体进行PLI(配对暗知识反转)攻击。在多个面部识别数据集上的实验验证了在FedMD等方案下,仅使用公共数据集的配对服务器-客户端暗知识,恶意服务器能够以高成功率重构所有测试基准中的私有图像。
Conditional Antibody Design as 3D Equivariant Graph Translation
单位:
清华大学,人民大学高瓴人工智能学院,清华大学智能产业研究院(AIR)
摘要:
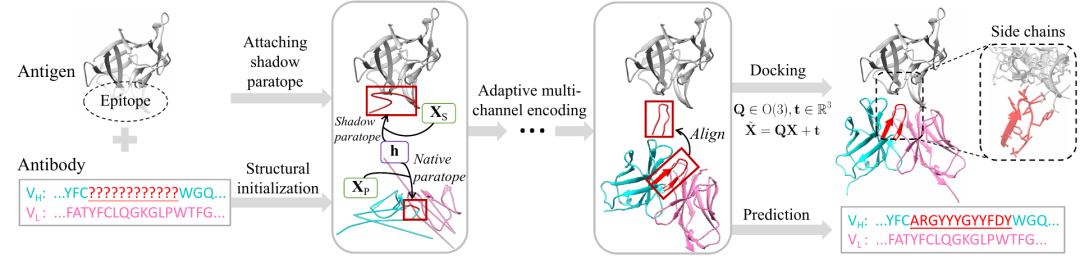
抗体设计对治疗和生物研究非常有价值。现有的基于深度学习的方法遇到了几个关键问题:1)无法建模生成互补决定区(CDR)所需的完整上下文;2)无法捕捉输入结构的完整3D几何;3)用自回归方式低效地预测CDR序列。本文提出了多通道等变注意力网络(MEAN),以协同设计CDR的1D序列和3D结构。具体而言,MEAN将抗体设计作为条件图翻译问题来进行,导入目标抗原和抗体轻链等额外组件。然后,MEAN采用E(3)等变消息传递以及提出的注意机制,以更好地捕捉不同组件之间的几何相关性。最后,采用多轮逐步全射方案输出1D序列和3D结构,这比以前的自回归方法更高效和精确。我们的方法在序列和结构建模、抗原结合CDR设计和结合亲和力优化方面显著超越了现有技术,特别是在抗原结合CDR设计和亲和力优化方面,相对于基线的改进分别约为23%和34%。
End-to-End Full-Atom Antibody Design
单位:
清华大学,人民大学高瓴人工智能学院,清华大学智能产业研究院(AIR)
摘要:
抗体设计是治疗和生物学等各领域中不可或缺且具有挑战性的任务。
目前基于学习的方法存在两个主要缺陷:
1)仅处理整个抗体设计流程的某个子任务,因此效果不佳或效率低下;
2)省略框架区域或侧链,因此无法捕捉完整的原子几何。
为了解决这些问题,我们提出了动态多通道等变图网络(dyMEAN),这是一种端到端的全原子模型,用于在给定抗原和不完整的抗体序列的情况下进行E(3)等变抗体设计。
具体而言,我们首先探索知识引导的抗体结构初始化,然后提出影子位点来桥接抗原-抗体之间的联系。
通过自适应多通道等变编码器更新1D序列和3D结构,该编码器能够在考虑全原子时处理可变大小的蛋白质残基。
最后,通过对齐影子位点将更新的抗体对接到抗原上。
在抗原结合CDR-H3设计,复杂结构预测和亲和力优化方面的实验证明了我们的端到端框架和全原子建模的优越性。
Fractional Denoising for 3D Molecular Pretraining
作者:
冯世坤,倪
雨
嫣,兰艳艳,马志明,马维英
单位:
清华大学,中国科学院数学与系统科学研究院,清华大学智能产业研究院(AIR)
摘要:
坐标去噪方法是当下
3D分子预训练中的代表性方法,它对稳态分子坐标加高斯噪声,再让模型学习去噪。
坐标去噪具有学习分子近似力场的理论解释。
然而,坐标去噪方法具有两个显著的问题,一是样本覆盖低,一是近似力场不精确,其根本原因在于模型假设的分子的概率分布与实际分布不相符。
实际中分子具有刚性和柔性两种部分,即分子的概率分布是各向异性的,而去噪方法假设的分子的概率分布是各向同性的。
针对上述两个问题,我们提出了一种新的混合噪声策略,先对稳态分子中可旋转二面角加高斯噪声,再对分子坐标加高斯噪声。
这种混合噪声可以采样更多有价值的低能量样本,并刻画各向异性的分子的概率分布。
然而,我们在理论上发现对混合噪声去噪与力场学习不等价,其核心挑战在于混合噪声中二面角噪声的方差对输入构象的依赖性。
针对此挑战,我们建议将这两种类型的噪声解耦,并设计了一种新的分数去噪方法(Frad),该方法只对混合噪声中坐标部分进行去噪。
通过这种方式,我们证明Frad既能采样更多低能量结构,也等价于学习更准确的近似分子力场。
广泛的实验表明了Frad在分子表征方面的有效性,在QM9和MD17 Benchmark上都达到了最先进的水平。
Coarse-to-Fine: a Hierarchical Diffusion Model for Molecule Generation in 3D
作者:
强
博,宋宇轩,徐民凯,龚经经,高博文,周浩,马维英,兰艳艳
单位:
清华大
学,北京大学,清华大学智能产业研究院(AIR)
摘要:
由于分子在展现所需要的性质,或者形成分子-分子,蛋白-分子相互作用的过程中,都是以三维的形式存在的,因此设计生成模型直接生成3D分子是重要的研究方向。
针对于现有生成方法(尤其是大分子生成)效率低的问题,我们使用了一种基于分层扩散的模型(即~HierDiff),以在不依赖于自回归建模的情况下保持局部分段的有效性。
为了满足小分子相邻片段的匹配性,我们设计了高效的三维片段生成策略,即先对分子片段进行整体化建模,再通过进行细粒度生成优化。
具体来说,HierDiff首先通过等变扩散过程生成粗粒度分子几何结构,其中每个粗粒度节点反映分子中的片段的相对坐标位置与某些理化性质。
然后通过消息传递过程和新设计的迭代细化采样模块将粗粒度节点解码为细粒度片段。
最后,对细粒度的碎片进行三维空间组装,得到完整的原子分子结构。
我们进一步在实验中发现,在生成结构的理化性质上,HierDiff生成的分子有更小的毒性以及更高的可合成性,此方法具有辅助药物设计的潜力。
在生成三维结构的构象质量上,能够生成更为稳定低能的分子构象。
综上所述,HierDiff能够持续提高分子生成的质量,同时为有强局部条件约束的扩散模型提供了新的见解。
Weakly Supervised Vision-and-Language Pre-training with Relative Representations
单位:
清华大学计算机系、清华大学智能产业研究院(AIR)
摘要:弱监督的视觉和语言预训练 (WVLP) 可以在有限的跨模态监督下学习跨模态表征,从而有效减少预训练的数据成本,并在下游任务中保持良好的性能。然而,目前的 WVLP 方法只使用图像的局部描述(即对象标签)作为跨模态锚点,以构建弱对齐的图像-文本对进行预训练,这影响了数据质量,进而影响了预训练的效果。为此,我们建议直接使用少量对齐的图像-文本对作为锚点,并通过它们与其他未对齐的图像和文本的相似性来表示每个未对齐的样本,即使用相对表示。我们提出了一个基于相对表征的 WVLP 框架 RELIT,该框架从大规模的纯图像和纯文本数据中,通过基于相对表征的检索和生成收集高质量的弱对齐图像-文本对用于预训练。实验结果表明,在弱监督环境下,RELIT 在四个下游任务上取得了最先进的性能表现。
AdaptiveNet: Post-deployment Neural Architecture Adaptation for Diverse Edge Environments
作者:温皓,李元春,张尊帅,姜世琦,叶晓舟,欧阳烨,张亚勤,刘云新
单位:
清华大学智能产业研究院(AIR),微软研究院,亚信科技,上海大学,浦江实验室
摘要:
深度学习模型越来越多地被应用于实时边缘设备,为了确保跨不同边缘环境的稳定服务质量,我们希望为不同条件生成定制的模型架构。
然而,传统的模型部署方法由于难以处理边缘环境的多样性和对边缘信息的需求而不尽人意。
本文提出了一种在目标环境下部署后对模型架构进行适应性调整的方法,可
以精确地测量模型质量并保留私有边缘数据,以确保有效的边缘模型生成。
我们引入了一种基于预训练辅助的云端模型弹性化方法和一种适合边缘设备的设备端架构搜索方法。
模型弹性化方法利用开发者指定的预测模型的指导来生成高质量的模型架构搜索空间。
空间中的每个子网络都是一个有效的模型,具有不同的环境亲和性,每个设备都可以基于一系列边缘定制优化找到并维护最适合的子网络。
对各种边缘设备的广泛实验表明,我们的方法能够在最小开销(云端13 GPU小时的训练和边缘服务器2分钟的自适应部署)的情况下实现显著更好的精度-延迟权衡(例如相对于baseline,平均精度提高46.74%,延迟预算为60%)。
NN-Stretch: Automatic Neural Network Branching for Parallel Inference on Heterogeneous Multi-Processors
作者:魏剑宇,曹婷,曹士杰,姜世琦,傅绍伟,杨懋,张燕咏,刘云新
单位:
中国科
学技术大学,微软研究院,清华大学智能产业研究院(AIR)
摘要:
移动设
备越来越多地配备了异构多处理器,如CPU + GPU + DSP。
然而,由于大多数神经网络模型是单分支的结构,现有的神经网络推理系统无法充分利用异构多处理器的计算能力。
为此,本文提出了一种新的模型自适应策略NN-Stretch及其支持系统,根据处理器体系结构特征自动地对给定的模型进行多分支化。
NN-Stretch的核心思想是对模型进行水平拉伸,把一个长而窄的模型转变成一个有多个分支的短而宽的模型。
NN-Stretch将该问题抽象为一个具有巨大设计空间的优化问题,通过考虑硬延迟约束来缩小搜索空间,以及通过维护每个分支的模型结构和表达性来约束精度损失。
根据约束条件,NN-Stretch可以有效地生成准确高效的多分支模型。
为了方便部署,本文还设计了一个基于子图的空间调度器,作为现有移动推理框架的插件,以有效地执行多分支模型。
实验结果展示了与在单一CPU/GPU/DSP上执行相比,NN-Stretch取得了高达3.85的加速比,同时模型精度最高可提高0.8%。
Multimodal Federated Learning via Contrastive Representation Ensemble
摘要:
随着现代移动系统和物联⽹设备上多媒体数据的增加,如何在不侵犯用户隐私的前提下利用起这些海量的多模态数据成为⼀个重要问题。
联邦学习是一种新兴的注重隐私保护的分布式机器学习范式。
然而,目前的多模态联邦学习方法依赖单模态级别分别的“模型”聚合,这要求服务器端和客户端模型具有相同的架构,限制了服务器端模型的复杂度。
本⽂提出了一种多模态联邦学习框架CreamFL,能够从模型架构和数据模态异构的客户端训练更⼤的服务器端模型。
我们设计了⼀种全局-局部协同的跨模态聚合策略来对客户端模型⽣成的表示进行聚合。
进⼀步地,为了减轻由多模态差异造成的客户端模型偏移,我们提出模态间和模态内的对比学习,以对客户端模型的训练做正则化。
这为单模态客户端补充了缺少的模态信息,并约束着客户端学习全局共识。
对图像文本检索和视觉问答任务的评估和消融研究表明,本框架优于最先进的联邦学习方法。
ConvReLU++: Reference-based Lossless Acceleration of Conv-ReLU Operations on Mobile CPU
单位:
上
海交通大学、清华大学智能产业研究院(AIR)、浦江实验室
摘要:
卷积神经网络(CNN)中最常用的激活函数之一是ReLU,导致CNN中许多输出激活值会为零。
因此,一类加速CNN推理的思路是提前识别那些输出为零的神经元,从而跳过这些神经元相关的冗余的计算,起到加速的效果。
然而,目前这类方法在提高推理效率的同时会带来识别精度的损失。
为此,研究团队提出了一种称为ConvReLU++的无损加速方法,用于移动设备CNN推理加速。
该方法可以准确地检测和跳过零输出计算,以实现CNN推理加速,而不会造成任何精度损失。
研究团队在流行的移动推理框架中实现了ConvReLU++,并对其进行了常见的深度视觉任务评估。
实验结果表明,相比原始的推理框架,ConvReLU++ 可以减少大量的计算量,并且在真实边缘设备上获得2.90%至8.91%的端到端推理加速效果,并且不会牺牲精度。
代码和模型详见https://github.com/GAIR-team/conv_relu_plus_plus。
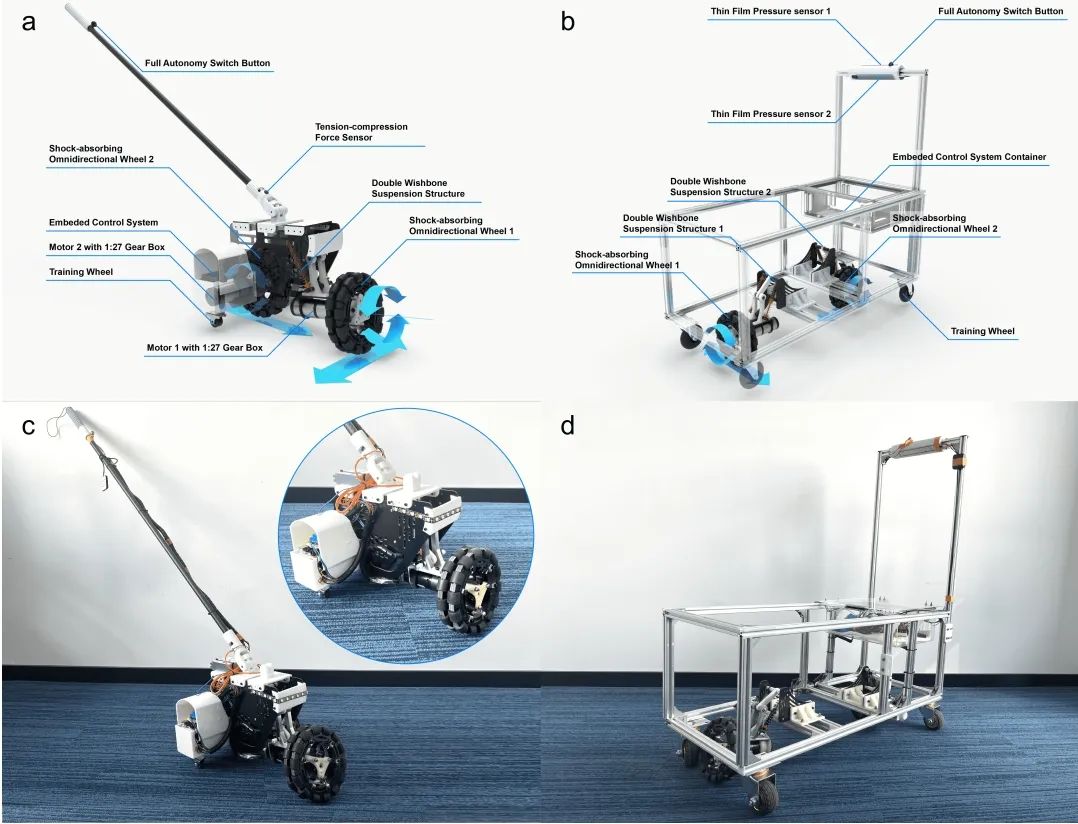
"I am the follower, also the boss": Exploring Different Levels of Autonomy and Machine Forms of Guiding Robots for the Visually Impaired
作者:
张研,李子昂,郭昊乐,王璐瑶,陈启鹤,江文杰,范明明,周谷越,龚江涛
单位:
清华大学智能产业研究院(AIR),香港科技大学(广州)
摘要:
基于自动驾驶技术的导航机器人,可以帮助盲人和低视力人群获得独立出行的能力。在本研究中,我们设计了自主性可切换的两种形态的机器人(智能盲杖和智能小车),并且面向视障用户进行了实验室中的控制对照研究(N=12)和真实环境的自然行走实地研究(N=9)。结果表明,虽然在控制对照研究中,完全自主性的机器人得到了更好的行走表现和主观评价,然而在自然环境中参与者行走时要求保留更多的控制权。此外,与盲杖机器人相比,小车形态机器人被证明了提供更高安全感和导航效率。我们的发现提供了关于视障人群使用不同机器形态和自主性的实证研究证据,这些可以为辅助机器人的设计提供启发参考。